Обсуждение: WIP: Upper planner pathification
Those with long memories will recall that I've been waving my arms about
$SUBJECT for more than five years. I started to work seriously on a patch
last summer, and here is a version that I feel comfortable exposing to
public scrutiny (which is not to call it "done"; more below).
The basic point of this patch is to apply the generate-and-compare-Paths
paradigm to the planning steps after query_planner(), which only covers
scan and join processing (the FROM and WHERE parts of a query). These
later steps deal with grouping/aggregation, window functions, SELECT
DISTINCT, ORDER BY, LockRows (SELECT FOR UPDATE), LIMIT/OFFSET, and
ModifyTable. Also UNION/INTERSECT/EXCEPT. Back in the bad old days we
had only one way to do any of that stuff, so there was no real problem
with the approach of converting query_planner's answer into a Plan and
then stacking more Plan nodes atop that. Over time we grew other ways
to do those steps, and chose between those ways with ad-hoc code in
grouping_planner(). That was messy enough in itself, but it had other
disadvantages too: subquery_planner() had to choose and return a single
Plan, without regard to what the outer query might need. (Well, we did
pass down a tuple_fraction parameter, but that is a pretty limited bit of
information.)
An even larger problem is that we had no way to handle addition of new
alternative plan types for these upper-planning steps without fundamental
hacking on grouping_planner(). An example is the code I added in commit
addc42c339208d6a and later (planagg.c and other places) for optimization
of MIN/MAX aggregates: that code had a positively incestuous relationship
with grouping_planner(), and was darn ugly in multiple other ways besides.
Of late, the main way this issue has surfaced is that we have no practical
way to plan pushdown of aggregates or updates on remote tables to the
responsible FDWs, because the FDWs cannot create Paths representing such
operations.
The present patch addresses this problem by inventing Path nodes to
represent every post-scan/join step, and changing the API of
grouping_planner() and subquery_planner() so that they return sets of
Paths rather than single Plans. Creation of a Plan tree happens only
after control returns to the top level of standard_planner(). The Path
nodes for these post-scan/join steps are attached to "upper relation"
RelOptInfos that didn't exist before. There are provisions for FDWs to
inject candidate Paths for these upper-level steps. As proof of concept
for that, planagg.c has been revised to work by injecting a new Path
into the grouping/aggregation upper rel, rather than predetermining what
the answer will be. This vastly decreases its coupling with both
grouping_planner and some other parts of the system such as equivclass.c
(though, the Law of Conservation of Cruft being what it is, I did have to
push some knowledge about planagg.c's work into setrefs.c).
I'm pretty pleased with the way this turned out. grouping_planner() is
about half the length it was before, and much more straightforward IMO.
planagg.c no longer seems like a complete hack; it's a reasonable
prototype for injecting nontraditional implementation paths into
aggregation or other late planner stages, and grouping_planner() doesn't
need to know about it.
The patch does add a lot of net new lines (and it's not done) but
most of the new code is very straightforward boilerplate.
The main thing that makes this WIP and not committable is that I've not
yet bothered to implement outfuncs.c code and some other debug support for
all the new path struct types. A lot of the new function header comments
remain to be fleshed out too, and some more documentation needs to be
written. But I think it's reviewable as-is; the other stuff would just
make it even longer but not more interesting.
There's a lot of future work to be done within this skeleton. Notably,
I did not fix the UNION/INTERSECT/EXCEPT planning code to consider
multiple paths; it still only generates a single Path tree. That code
needs to be rewritten from scratch, probably, and it seems like doing so
is a separate project. I'd also like to do some more refactoring in
createplan.c: some code paths are still doing redundant cost estimation,
and I'm growing increasingly dissatisfied with the "use_physical_tlist"
hack. But that seems like a separable issue as well.
So, where to go from here? I'm acutely aware that we're hard up against
the final 9.6 commitfest, and that we discourage major patches arriving
so late in a devel cycle. But I simply couldn't get this done any faster.
I don't really want to hold it over for the 9.7 devel cycle. It's been
enough trouble maintaining this patch in the face of conflicting commits
over the last year or so (it's probably still got bugs related to parallel
query...), and there definitely are conflicting patches in the upcoming
'fest. And the lack of this infrastructure is blocking progress on FDWs
and some other things.
So I'd really like to get this into 9.6. I'm happy to put it into the
March commitfest if someone will volunteer to review it.
Comments?
regards, tom lane
Вложения
Hi, On 2016-02-28 15:03:28 -0500, Tom Lane wrote: > Those with long memories will recall that I've been waving my arms about > $SUBJECT for more than five years. I started to work seriously on a patch > last summer, and here is a version that I feel comfortable exposing to > public scrutiny (which is not to call it "done"; more below). Yay! > So, where to go from here? I'm acutely aware that we're hard up against > the final 9.6 commitfest, and that we discourage major patches arriving > so late in a devel cycle. But I simply couldn't get this done any faster. > I don't really want to hold it over for the 9.7 devel cycle. It's been > enough trouble maintaining this patch in the face of conflicting commits > over the last year or so (it's probably still got bugs related to parallel > query...), and there definitely are conflicting patches in the upcoming > 'fest. And the lack of this infrastructure is blocking progress on FDWs > and some other things. > > So I'd really like to get this into 9.6. I'm happy to put it into the > March commitfest if someone will volunteer to review it. Hard. This is likely to cause/trigger a number of bugs, and we don't have much time to let this mature. It's a change that we're unlikely to be able to back-out if we discover that it wasn't the right thing to integrate shortly before the release. On the other hand, this is a major architectural step forward; one that unblocks a number of nice features. There's also an argument to be made that integrating this now is beneficial, because it'll cause less churn for patches being developed while 9.6 is stabilizing. Greetings, Andres Freund
On 28 February 2016 at 20:03, Tom Lane <tgl@sss.pgh.pa.us> wrote:
--
So, where to go from here? I'm acutely aware that we're hard up against
the final 9.6 commitfest, and that we discourage major patches arriving
so late in a devel cycle. But I simply couldn't get this done any faster.
I don't really want to hold it over for the 9.7 devel cycle. It's been
enough trouble maintaining this patch in the face of conflicting commits
over the last year or so (it's probably still got bugs related to parallel
query...), and there definitely are conflicting patches in the upcoming
'fest. And the lack of this infrastructure is blocking progress on FDWs
and some other things.
Thanks for working on this; it is important.
I'm disappointed to see you do this because of FDWs, with the "some other things" like parallel aggregation not getting a mention by name.
While I wouldn't mind seeing this go in, what worries me is the multiple other patches that now need to be rewritten to exploit this and since some aren't mentioned would it be reasonable to imagine those other things won't be prioritised for this release? Or will we be deciding to elongate the integration phase to cope with this? Delay or favour forks, which should we choose?
Anyway, glad to see you will now experience the problems of maintaining large patches across multiple releases and/or the difficulty of arguing in favour of patches that still require work going in at the last minute. Not with relish, just so that understanding isn't limited to the usual suspects of feature-crime.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sun, Feb 28, 2016 at 3:03 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > So, where to go from here? I'm acutely aware that we're hard up against > the final 9.6 commitfest, and that we discourage major patches arriving > so late in a devel cycle. But I simply couldn't get this done any faster. > I don't really want to hold it over for the 9.7 devel cycle. It's been > enough trouble maintaining this patch in the face of conflicting commits > over the last year or so (it's probably still got bugs related to parallel > query...), and there definitely are conflicting patches in the upcoming > 'fest. And the lack of this infrastructure is blocking progress on FDWs > and some other things. > > So I'd really like to get this into 9.6. I'm happy to put it into the > March commitfest if someone will volunteer to review it. I'll abstain from the question of whether this patch is too late in coming (but the answer is probably "yes") and instead volunteer to review it. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> I'll abstain from the question of whether this patch is too late in
> coming (but the answer is probably "yes") and instead volunteer to
> review it.
OK, I've put it into the commitfest. Thanks for volunteering!
regards, tom lane
> The basic point of this patch is to apply the generate-and-compare-Paths > paradigm to the planning steps after query_planner(), which only covers ...> The present patch addresses this problem by inventing Path nodes to> represent every post-scan/join step I'm really glad to see that. Separating path nodes for later steps opens a new ways to optimize queries. For first glance, consider select * from a left outer join b on a.i = b.i limit 1; Limit node could be pushed down to scan over 'a' table if b.i is unique. I tried to look into patch and I had a question (one for now): why LimitPath doesn't contain actual limit/offset value? I saw a lot of subqueries with LIMIT 1 which could be transformed into EXISTS subquery. > So I'd really like to get this into 9.6. Me too. I applied the patch and can confirm that 'make test' doesn't fail on FreeBSD 10.2. Now I will try to run kind of TPC-H with and without patch. -- Teodor Sigaev E-mail: teodor@sigaev.ru WWW: http://www.sigaev.ru/
On Tue, Mar 1, 2016 at 3:11 PM, Teodor Sigaev <teodor@sigaev.ru> wrote:
The basic point of this patch is to apply the generate-and-compare-Paths...
paradigm to the planning steps after query_planner(), which only covers
> The present patch addresses this problem by inventing Path nodes to
> represent every post-scan/join step
I'm really glad to see that. Separating path nodes for later steps opens a new ways to optimize queries. For first glance, consider
select * from a left outer join b on a.i = b.i limit 1;
Limit node could be pushed down to scan over 'a' table if b.i is unique.
This patch opens a lot of possibilities to our ongoing project on indexing subselects, which we plan to use for jsonb. Having it in 9.6 will certainly facilitate this. So, I'm +1 for this patch, even if we have to postpone 9.6 a bit. Hope, Robert, Teodor and other reviewers could help Tom with this patch.
--
Teodor Sigaev E-mail: teodor@sigaev.ru
WWW: http://www.sigaev.ru/
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
On 2/28/16 4:02 PM, Andres Freund wrote: >> So, where to go from here? I'm acutely aware that we're hard up against >> >the final 9.6 commitfest, and that we discourage major patches arriving >> >so late in a devel cycle. But I simply couldn't get this done any faster. >> >I don't really want to hold it over for the 9.7 devel cycle. It's been >> >enough trouble maintaining this patch in the face of conflicting commits >> >over the last year or so (it's probably still got bugs related to parallel >> >query...), and there definitely are conflicting patches in the upcoming >> >'fest. And the lack of this infrastructure is blocking progress on FDWs >> >and some other things. >> > >> >So I'd really like to get this into 9.6. I'm happy to put it into the >> >March commitfest if someone will volunteer to review it. > Hard. This is likely to cause/trigger a number of bugs, and we don't > have much time to let this mature. It's a change that we're unlikely to > be able to back-out if we discover that it wasn't the right thing to > integrate shortly before the release. On the other hand, this is a > major architectural step forward; one that unblocks a number of nice > features. There's also an argument to be made that integrating this now > is beneficial, because it'll cause less churn for patches being > developed while 9.6 is stabilizing. Perhaps the best way to handle this would be to commit it to a branch sooner rather than later. If things work out, that branch can become the official beta. If not, in can become the basis for 9.7. If nothing else it means that Tom isn't the only one stuck trying to maintain this. Even if the branch is nothing but a means to generating a patch for 9.7, having it in place makes it a lot easier for other developers that need to to code against it. While I'm promoting heresy... I imagine that this patch doesn't require a catversion bump. Perhaps it would be worth doing a short-cycle major release just to get this in. That might sound insane but since one of the biggest obstacles to upgrading remains dealing with the on-disk format, I don't think users would freak out about it. -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com
Teodor Sigaev <teodor@sigaev.ru> writes:
> I tried to look into patch and I had a question (one for now): why LimitPath
> doesn't contain actual limit/offset value? I saw a lot of subqueries with LIMIT
> 1 which could be transformed into EXISTS subquery.
Oh, yeah, I intended to change that but didn't get to it yet. Consider
it done.
> Me too. I applied the patch and can confirm that 'make test' doesn't fail on
> FreeBSD 10.2. Now I will try to run kind of TPC-H with and without patch.
I do not think the patch will make a lot of performance difference as-is;
its value is more in what it will let us do later. There are a couple of
regression test cases that change plans for the better, but it's sort of
accidental. Those cases look like
select d.* from d left join (select * from b group by b.id, b.c_id) s on d.a = s.id;
and what happens in HEAD is that the subquery chooses a hashagg plan
and then the upper query decides a mergejoin would be a good idea ...
so it has to sort the output of the hashagg. With the patch, what
comes back from the subquery is a Path for the hashagg and a Path
for doing the GROUP BY with Sort/Uniq. The second path is more expensive,
but it survives the add_path tournament because it can produce sorted
output. Then the outer level discovers that it can use that to do its
mergejoin without a separate sort step, and that way is cheaper overall.
So instead of
! -> Sort
! Sort Key: s.id
! -> Subquery Scan on s
! -> HashAggregate
! Group Key: b.id
! -> Seq Scan on b
we get
! -> Group
! Group Key: b.id
! -> Index Scan using b_pkey on b
which is noticeably cheaper, and not just because we got rid of the
Subquery Scan node. So that's nice --- but it's more or less accidental,
because the outer level isn't telling the inner level that this sort order
might be interesting.
Once this infrastructure is in place, I want to look at passing down more
information to recursive subquery_planner calls so that we're not leaving
this kind of optimization to chance. But the patch is big enough already,
so that (and a lot of other things) are getting left for later.
regards, tom lane
On Tue, Mar 1, 2016 at 2:30 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > There are a couple of > regression test cases that change plans for the better, but it's sort of > accidental. Those cases look like > > select d.* from d left join (select * from b group by b.id, b.c_id) s > on d.a = s.id; > > and what happens in HEAD is that the subquery chooses a hashagg plan > and then the upper query decides a mergejoin would be a good idea ... > so it has to sort the output of the hashagg. With the patch, what > comes back from the subquery is a Path for the hashagg and a Path > for doing the GROUP BY with Sort/Uniq. The second path is more expensive, > but it survives the add_path tournament because it can produce sorted > output. Then the outer level discovers that it can use that to do its > mergejoin without a separate sort step, and that way is cheaper overall. This doesn't sound accidental at all. It sounds like a perfect example of exactly the benefits of this approach. I read through the patch just to get an idea what's changing. But obviously that's not going to actually turn up anything surprising. (Actually the first hunk in the patch kind of surprised me. Do we dump node trees with -> notation currently? I thought they normally all looked like sexpressions.) -- greg
Greg Stark <stark@mit.edu> writes:
> On Tue, Mar 1, 2016 at 2:30 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> There are a couple of
>> regression test cases that change plans for the better, but it's sort of
>> accidental. Those cases look like
>>
>> select d.* from d left join (select * from b group by b.id, b.c_id) s
>> on d.a = s.id;
>>
>> and what happens in HEAD is that the subquery chooses a hashagg plan
>> and then the upper query decides a mergejoin would be a good idea ...
>> so it has to sort the output of the hashagg. With the patch, what
>> comes back from the subquery is a Path for the hashagg and a Path
>> for doing the GROUP BY with Sort/Uniq. The second path is more expensive,
>> but it survives the add_path tournament because it can produce sorted
>> output. Then the outer level discovers that it can use that to do its
>> mergejoin without a separate sort step, and that way is cheaper overall.
> This doesn't sound accidental at all. It sounds like a perfect example
> of exactly the benefits of this approach.
Well, my point is that no such path would have been generated if the
subquery hadn't had an internal reason to consider sorting on b.id.
The "accidental" part of this is that the subquery's GROUP BY key
matches what the outer query needs as a mergejoin key.
> (Actually the first hunk in the patch kind of surprised me. Do we dump
> node trees with -> notation currently? I thought they normally all
> looked like sexpressions.)
I chose in 19a541143 to not make PathTarget be a subclass of Node,
so that's kind of forced --- we can't print it by recursing to
_outNode(). We could change that but I'm not sure it would be an
improvement. The restarget fields are embedded in RelOptInfo, not
sub-nodes of it, so pretending that they're independent nodes seems
a bit phony in its own way. I'm not wedded to that reasoning though;
if people are more concerned about what pprint() output looks like,
we can change it. Or we could make restarget actually be a subnode,
at the cost of one more palloc per RelOptInfo.
regards, tom lane
> I do not think the patch will make a lot of performance difference as-is; > its value is more in what it will let us do later. There are a couple of Yep, for now on my notebook (best from 5 tries): % pgbench -i -s 3000 % pgbench -s 3000 -c 4 -j 4 -P 1 -T 60 HEAD 569 tps patched 542 tps % pgbench -s 3000 -c 4 -j 4 -P 1 -T 60 -S HEAD 9500 tps patched 9458 tps Looks close to measurement error, but may be explained increased amount of work for planning. Including, may be, more complicated path tree. > this kind of optimization to chance. But the patch is big enough already, > so that (and a lot of other things) are getting left for later. Agree -- Teodor Sigaev E-mail: teodor@sigaev.ru WWW: http://www.sigaev.ru/
Teodor Sigaev <teodor@sigaev.ru> writes:
>> I do not think the patch will make a lot of performance difference as-is;
>> its value is more in what it will let us do later. There are a couple of
> Yep, for now on my notebook (best from 5 tries):
> % pgbench -i -s 3000
> % pgbench -s 3000 -c 4 -j 4 -P 1 -T 60
> HEAD 569 tps
> patched 542 tps
> % pgbench -s 3000 -c 4 -j 4 -P 1 -T 60 -S
> HEAD 9500 tps
> patched 9458 tps
> Looks close to measurement error, but may be explained increased amount of work
> for planning. Including, may be, more complicated path tree.
I think the default pgbench queries are too simple to have any possible
benefit from this patch. It does look like you're seeing some extra
planning time, which I think is likely due to redundant construction
of PathTargets. The new function set_pathtarget_cost_width() is not
very cheap, and in order to minimize the delta in this patch I did
not worry much about avoiding duplicate calls of it. That's another
thing in a long list of things to do later ;-). There might be other
pain points I haven't recognized yet.
regards, tom lane
On Tue, Mar 1, 2016 at 10:22 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Teodor Sigaev <teodor@sigaev.ru> writes: >>> I do not think the patch will make a lot of performance difference as-is; >>> its value is more in what it will let us do later. There are a couple of > >> Yep, for now on my notebook (best from 5 tries): >> % pgbench -i -s 3000 >> % pgbench -s 3000 -c 4 -j 4 -P 1 -T 60 >> HEAD 569 tps >> patched 542 tps >> % pgbench -s 3000 -c 4 -j 4 -P 1 -T 60 -S >> HEAD 9500 tps >> patched 9458 tps > >> Looks close to measurement error, but may be explained increased amount of work >> for planning. Including, may be, more complicated path tree. > > I think the default pgbench queries are too simple to have any possible > benefit from this patch. It does look like you're seeing some extra > planning time, which I think is likely due to redundant construction > of PathTargets. The new function set_pathtarget_cost_width() is not > very cheap, and in order to minimize the delta in this patch I did > not worry much about avoiding duplicate calls of it. That's another > thing in a long list of things to do later ;-). There might be other > pain points I haven't recognized yet. Yikes. The read-only test is an 0.5% hit which isn't great, but the read-write test is about 5% which I think is clearly not OK. What's your plan for doing something about that? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2 March 2016 at 13:47, Robert Haas <robertmhaas@gmail.com> wrote:
--
On Tue, Mar 1, 2016 at 10:22 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> Teodor Sigaev <teodor@sigaev.ru> writes:
>>> I do not think the patch will make a lot of performance difference as-is;
>>> its value is more in what it will let us do later. There are a couple of
>
>> Yep, for now on my notebook (best from 5 tries):
>> % pgbench -i -s 3000
>> % pgbench -s 3000 -c 4 -j 4 -P 1 -T 60
>> HEAD 569 tps
>> patched 542 tps
>> % pgbench -s 3000 -c 4 -j 4 -P 1 -T 60 -S
>> HEAD 9500 tps
>> patched 9458 tps
>
>> Looks close to measurement error, but may be explained increased amount of work
>> for planning. Including, may be, more complicated path tree.
>
> I think the default pgbench queries are too simple to have any possible
> benefit from this patch. It does look like you're seeing some extra
> planning time, which I think is likely due to redundant construction
> of PathTargets. The new function set_pathtarget_cost_width() is not
> very cheap, and in order to minimize the delta in this patch I did
> not worry much about avoiding duplicate calls of it. That's another
> thing in a long list of things to do later ;-). There might be other
> pain points I haven't recognized yet.
Yikes. The read-only test is an 0.5% hit which isn't great, but the
read-write test is about 5% which I think is clearly not OK. What's
your plan for doing something about that?
Whether artefact of test, or real problem, clearly something fixable.
ISTM that we are clearly "going for it"; everybody agrees we should apply the patch now.
The longer we hold off on applying it, the longer we wait for dependent changes.
My vote is apply it early (i.e. now!) and clean up as we go.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Robert Haas <robertmhaas@gmail.com> writes:
> On Tue, Mar 1, 2016 at 10:22 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> I think the default pgbench queries are too simple to have any possible
>> benefit from this patch. It does look like you're seeing some extra
>> planning time, which I think is likely due to redundant construction
>> of PathTargets. The new function set_pathtarget_cost_width() is not
>> very cheap, and in order to minimize the delta in this patch I did
>> not worry much about avoiding duplicate calls of it. That's another
>> thing in a long list of things to do later ;-). There might be other
>> pain points I haven't recognized yet.
> Yikes. The read-only test is an 0.5% hit which isn't great, but the
> read-write test is about 5% which I think is clearly not OK. What's
> your plan for doing something about that?
I do plan to take a look at it. Obviously, anything that *does* benefit
from this patch is going to see some planning slowdown as a consequence
of considering more Paths. But ideally, a query that has no grouping/
aggregation/later steps wouldn't see any difference. I think we can
get to that --- but I'd rather not complicate v1 with the hacks that
will probably be required.
(My first thought about how to fix that is to not force
set_pathtarget_cost_width to be done immediately on PathTarget
construction, but make it a decouplable step. I believe that
set_pathtarget_cost_width is only expensive if it's run before
query_planner runs, and we can probably finagle things so that we do not
really care about the cost/width attached to targets made before that.
But this all depends on profiling that I've not done yet...)
regards, tom lane
Simon Riggs wrote: > ISTM that we are clearly "going for it"; everybody agrees we should apply > the patch now. > > The longer we hold off on applying it, the longer we wait for dependent > changes. Agreed -- we need this in tree as soon as realistically possible. There is a a bit a problem here, because this patch conflicts heavily with at least one other patch that's been in the queue for a long time, which is Kommi/Rowley's patch for parallel aggregation; the more we delay applying this one, the worse the deadlines for that one. I assume they are hard at work updating that patch to apply on top of Tom's patch. It's not realistic to expect that we would apply any further planner changes before this one is in. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Alvaro Herrera <alvherre@2ndquadrant.com> writes:
> Agreed -- we need this in tree as soon as realistically possible.
> There is a a bit a problem here, because this patch conflicts heavily
> with at least one other patch that's been in the queue for a long time,
> which is Kommi/Rowley's patch for parallel aggregation; the more we
> delay applying this one, the worse the deadlines for that one.
> I assume they are hard at work updating that patch to apply on top of
> Tom's patch. It's not realistic to expect that we would apply any
> further planner changes before this one is in.
I don't think it's quite that bad: the patch doesn't touch scan/join
planning very much, so for instance I doubt that the pending unique-joins
patch is completely broken. But yeah, anything having anything to do
with planning of grouping/aggregation or later stages is going to need
major revision to play with this.
regards, tom lane
Teodor Sigaev <teodor@sigaev.ru> writes:
> Yep, for now on my notebook (best from 5 tries):
> % pgbench -i -s 3000
> % pgbench -s 3000 -c 4 -j 4 -P 1 -T 60
> HEAD 569 tps
> patched 542 tps
> % pgbench -s 3000 -c 4 -j 4 -P 1 -T 60 -S
> HEAD 9500 tps
> patched 9458 tps
> Looks close to measurement error, but may be explained increased amount
> of work for planning. Including, may be, more complicated path tree.
Hmmm ... I'm now wondering about the "measurement error" theory.
I tried to repeat this measurement locally, focusing on the select-only
number since that should have a higher ratio of planning time to
execution.
Test setup:
cassert-off build
pgbench -i -s 100
sudo cpupower frequency-set --governor performance
repeat 3 times: pgbench -c 4 -j 4 -P 5 -T 60 -S
HEAD:
tps = 32508.217002 (excluding connections establishing)
tps = 33081.402766
tps = 32520.859913
average of 3: 32703 tps
WITH PATCH:
tps = 32815.922160 (excluding connections establishing)
tps = 33312.149718
tps = 32784.527489
average of 3: 32970 tps
(Hardware: dual quad-core Xeon E5-2609, running current RHEL6)
So I see no evidence for a slowdown on pgbench's SELECT queries.
Anybody else want to check performance on simple scan/join queries?
regards, tom lane
On 3 March 2016 at 04:29, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > Simon Riggs wrote: > >> ISTM that we are clearly "going for it"; everybody agrees we should apply >> the patch now. >> >> The longer we hold off on applying it, the longer we wait for dependent >> changes. > > Agreed -- we need this in tree as soon as realistically possible. > > There is a a bit a problem here, because this patch conflicts heavily > with at least one other patch that's been in the queue for a long time, > which is Kommi/Rowley's patch for parallel aggregation; the more we > delay applying this one, the worse the deadlines for that one. > > I assume they are hard at work updating that patch to apply on top of > Tom's patch. It's not realistic to expect that we would apply any > further planner changes before this one is in. I agree that it would be good to get this in as soon as possible. I'm currently very close to being done with writing Parallel Aggregate on top of the upper planner changes. So far this version is much cleaner as there's less cruft added compared with the other version, of which would need to be removed again after the upper planner changes are in anyway. Putting parallel aggregate in first would be asking Tom to re-invent parallel aggregate when he rebases the upper planner stuff on the new master branch, which makes very little sense. So I agree that it would be nice to get the upper planner changes in first, but soon! not at the end of March 'fest, as doing so would most likely kill parallel aggregate for 9.6, and I kinda think that would be silly as (I think) it's pretty much the biggest missing piece of the parallel query set. -- David Rowley http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
David Rowley <david.rowley@2ndquadrant.com> writes:
> I agree that it would be good to get this in as soon as possible. I'm
> currently very close to being done with writing Parallel Aggregate on
> top of the upper planner changes. So far this version is much cleaner
> as there's less cruft added compared with the other version,
Cool! If you come across any points where it seems like it could be
done better or more easily, that would be tremendously valuable feedback
at this stage.
regards, tom lane
On 3 March 2016 at 18:04, Tom Lane <tgl@sss.pgh.pa.us> wrote: > David Rowley <david.rowley@2ndquadrant.com> writes: >> I agree that it would be good to get this in as soon as possible. I'm >> currently very close to being done with writing Parallel Aggregate on >> top of the upper planner changes. So far this version is much cleaner >> as there's less cruft added compared with the other version, > > Cool! If you come across any points where it seems like it could be > done better or more easily, that would be tremendously valuable feedback > at this stage. Well since you mention it, I started on hash grouping and it was rather simple and clean as in create_agg_path() I just created a chain of the required paths and let create_plan() recursively build the Finalize Aggregate -> Gather -> Partial Aggregate -> Seq Scan plan. That was rather simple, and actually very nice when compared to how things are handled in today's grouping planner. When it comes to Group Aggregate I notice that you're using a RollupPath rather than an AggPath even when there's no grouping sets. This also means that create_agg_path() is only ever used for the AGG_HASHED strategy, even though the 'strategy' is passed as a parameter to that function, so it seemed prudent to me, to make sure all strategies are handled properly there. My gripe is that I've added the required code to build the parallel group aggregate to create_agg_path() already, but since Group Aggregate uses the RollupPath I'm forced to add code in create_rollup_plan() which manually stacks up Plan nodes rather than just dealing with Paths and create_plan() and its recursive call magic. I can't quite see any blocker for not doing this, so would you object to separating out the treatment of Group Aggregate and Grouping Sets in create_grouping_paths() ? I think it would require less code overall. -- David Rowley http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 3 March 2016 at 22:57, David Rowley <david.rowley@2ndquadrant.com> wrote: > On 3 March 2016 at 18:04, Tom Lane <tgl@sss.pgh.pa.us> wrote: >> If you come across any points where it seems like it could be >> done better or more easily, that would be tremendously valuable feedback >> at this stage. > > Well since you mention it, I started on hash grouping and it was > rather simple and clean as in create_agg_path() I just created a chain > of the required paths and let create_plan() recursively build the > Finalize Aggregate -> Gather -> Partial Aggregate -> Seq Scan plan. > That was rather simple, and actually very nice when compared to how > things are handled in today's grouping planner. When it comes to Group > Aggregate I notice that you're using a RollupPath rather than an > AggPath even when there's no grouping sets. This also means that > create_agg_path() is only ever used for the AGG_HASHED strategy, even > though the 'strategy' is passed as a parameter to that function, so it > seemed prudent to me, to make sure all strategies are handled properly > there. > > My gripe is that I've added the required code to build the parallel > group aggregate to create_agg_path() already, but since Group > Aggregate uses the RollupPath I'm forced to add code in > create_rollup_plan() which manually stacks up Plan nodes rather than > just dealing with Paths and create_plan() and its recursive call > magic. > > I can't quite see any blocker for not doing this, so would you object > to separating out the treatment of Group Aggregate and Grouping Sets > in create_grouping_paths() ? I think it would require less code > overall. Actually I might have jumped the gun a little here with my complaint. I think it does not matter about this as I've just coded Parallel Group Aggregate part to reuse create_agg_path(), but left the non-parallel version to make use of create_rollup_path(). I don't think I want to go to the trouble of parallel grouping sets at this stage anyway. -- David Rowley http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
> So I see no evidence for a slowdown on pgbench's SELECT queries. > Anybody else want to check performance on simple scan/join queries? I did your tests with configure --enable-depend and pgbench -i -s 100 and slightly tweaked postgresql.conf, on notebook with CPU i7-3520M (2 cores + 2 HT), FreeBSD 10.2. pgbench -c 4 -j 4 -P 1 -T 60 -S HEAD 35834 tps avg (35825/35828/35808/35844/35865) Patched HEAD 35529 tps avg (35516/35561/35527/35534/35510) ~1% slowdown. I can live with that. -- Teodor Sigaev E-mail: teodor@sigaev.ru WWW: http://www.sigaev.ru/
David Rowley <david.rowley@2ndquadrant.com> writes:
> My gripe is that I've added the required code to build the parallel
> group aggregate to create_agg_path() already, but since Group
> Aggregate uses the RollupPath I'm forced to add code in
> create_rollup_plan() which manually stacks up Plan nodes rather than
> just dealing with Paths and create_plan() and its recursive call
> magic.
Yeah, RollupPath was something I did to be expeditious rather than
something I'm particularly in love with. It's OK for a first version,
I think, but we'd need to refactor it if we were to consider more than
one implementation strategy for a rollup. Also it's pretty ugly that
the code makes a RollupPath even when a basic AggPath is what is meant;
that's a leftover from the fact that current HEAD goes through
build_grouping_chain() even for simple aggregation without grouping sets.
One point to consider is that we don't want the create_foo_path stage
to do much more than what's necessary to get a cost/rows estimate.
So in general, postponing as much work as possible to createplan.c
is a good thing. But we don't want the Path representation to leave
any interesting planning choices implicit.
My general feeling about this is that I don't want it to be a blocker
for getting the basic patch in, but I'll happily consider further
refactoring of individual path types once we're over that hump.
If you wanted to start on a follow-on patch to deal with this particular
issue, be my guest.
regards, tom lane
On Sun, Feb 28, 2016 at 3:03 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I'm pretty pleased with the way this turned out. grouping_planner() is > about half the length it was before, and much more straightforward IMO. > planagg.c no longer seems like a complete hack; it's a reasonable > prototype for injecting nontraditional implementation paths into > aggregation or other late planner stages, and grouping_planner() doesn't > need to know about it. Thanks for working on this. Some review comments: - I think all of the new path creation functions should bubble up parallel_degree from their subpath. It's fine for LockRows to use 0 for now, because we have no hope of supporting write operations in parallel mode any time soon, but it's one less thing to change later. The others should really all use the subpath's parallel degree. Actually, they should use the subpath's parallel degree or maybe a larger number if they add a lot of CPU work to the query, but don't have any principled way to model that right now, so just copying the value is probably as good as we're going to do for the moment. - RollupPath seems like a poor choice of name, if nothing else. You would expect that it would be related to GROUP BY ROLLUP() but of course that's really the same thing as GROUP BY GROUPING SETS () or GROUP BY CUBE (), and the fundamental operation is actually GROUPING SETS, not ROLLUP. - It's not entirely related to this patch, but I'm starting to wonder if we've made the wrong bet about target lists. It seems to me that there's a huge difference between a projection which simply throws away columns we don't need and one which actually computes something, and maybe those cases ought to be treated differently instead of saying "well, it's a target list". It strikes me that there are probably execution-time optimizations that are possible in the former case, and maybe a more compact representation of the projection operation as well. I can't shake the feeling that our extensive use of lists can't be the best thing ever for performance. - A related point that is more connected to this patch is that you've added 13 (!) new calls to disuse_physical_tlist, and 8 of those are marked with /* XXX hack: need original tlist with sortgroupref marking */. I don't quite understand what's going on there. I think if we're going to be stuck with that hack we at least need some comments explaining what is going on there. What has caused us to suddenly need these calls when we didn't before, and why these places and not some others? - For SortPath, you mention that the SortGroupClauses representation isn't currently used. It's not clear to me that it ever would be; what would be the case where that might be useful? At any rate, I'd be inclined to rip it out for now; you can always put it back later. - create_distinct_paths() disables the hash path if it seems like it would exceed work_mem, unless the sort path isn't viable. But there's something that feels a bit uncomfortable about this. Suppose the sort path isn't viable but some other kind of future path is viable. It seems like it would be better to restructure this a bit so that the decision about whether to add the hash path is based on whether there are any other paths in the rel when we reach the bottom of the function. create_grouping_paths() has a similar issue. In general, and I'm sure this is not a huge surprise, most of this looks very good to me. I think the design is sound and that, if the performance is OK, we ought to move forward with it. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> Thanks for working on this. Some review comments:
> - I think all of the new path creation functions should bubble up
> parallel_degree from their subpath.
Ah, thanks, I didn't have any clue how to set that (though in my defense,
the documentation about it is next to nonexistent). Just to confirm,
I assume the rules are:
* parallel_aware: indicates whether the plan node itself has any
parallelism behavior
* parallel_safe: indicates that the entire plan tree rooted at this
node is safe to execute in a parallel worker
* parallel_degree: indicates number of parallel threads potentially
useful for this plan tree (0 if not parallel-safe)
This leads me to the conclusion that all these new node types should
set parallel_aware to false and copy up the other two fields from the
child, except for LockRows and ModifyTable which should set them all
to false/0. Correct? If so, I'll go fix.
> - RollupPath seems like a poor choice of name, if nothing else. You
> would expect that it would be related to GROUP BY ROLLUP() but of
> course that's really the same thing as GROUP BY GROUPING SETS () or
> GROUP BY CUBE (), and the fundamental operation is actually GROUPING
> SETS, not ROLLUP.
As I noted to David, that thing seems to me to be in need of refactoring,
but I'd just as soon leave untangling the grouping-sets mess for later.
I don't mind substituting a different name if you have a better idea,
but don't really want to do more work than that right now.
> - It's not entirely related to this patch, but I'm starting to wonder
> if we've made the wrong bet about target lists. It seems to me that
> there's a huge difference between a projection which simply throws
> away columns we don't need and one which actually computes something,
> and maybe those cases ought to be treated differently instead of
> saying "well, it's a target list". It strikes me that there are
> probably execution-time optimizations that are possible in the former
> case, and maybe a more compact representation of the projection
> operation as well. I can't shake the feeling that our extensive use
> of lists can't be the best thing ever for performance.
We do already have the "physical tlist" optimization. I agree that
there's more work to be done here, but again would rather leave that
to a later patch.
> - A related point that is more connected to this patch is that you've
> added 13 (!) new calls to disuse_physical_tlist, and 8 of those are
> marked with /* XXX hack: need original tlist with sortgroupref marking
> */. I don't quite understand what's going on there. I think if we're
> going to be stuck with that hack we at least need some comments
> explaining what is going on there. What has caused us to suddenly
> need these calls when we didn't before, and why these places and not
> some others?
Yeah, that's a hack to get things working. The problem is that these node
types need to be able to identify sort/group columns in their inputs, but
if the child has switched to a "physical tlist" then the ressortgroupref
marking isn't there, and indeed the needed column might not be there at
all if it's a computed expression not a Var. So what I did for the moment
was to force the inputs back to their nominal tlists. In the old code we
didn't have this problem because none of the upper-level plan node types
could see a physical tlist unless make_subplanTargetList had allowed it,
and then we applied locate_grouping_columns() to re-identify the grouping
columns. That logic probably needs to be transposed into createplan.c,
but I've not taken the time yet to figure out exactly how. I don't know
if it's reasonable to do that separately from rethinking how the whole
disuse_physical_tlist thing works.
> - For SortPath, you mention that the SortGroupClauses representation
> isn't currently used. It's not clear to me that it ever would be;
> what would be the case where that might be useful? At any rate, I'd
> be inclined to rip it out for now; you can always put it back later.
Yeah, I was dithering about that. It seems like createplan.c now has
a few too many ways to identify sort/group columns, and I was hoping
to consolidate them somehow. That might lead to wanting to use
SortGroupClauses not PathKeys in some cases. But until that's worked
out, I agree the extra field is useless and we can just drop it.
> - create_distinct_paths() disables the hash path if it seems like it
> would exceed work_mem, unless the sort path isn't viable. But there's
> something that feels a bit uncomfortable about this. Suppose the sort
> path isn't viable but some other kind of future path is viable. It
> seems like it would be better to restructure this a bit so that the
> decision about whether to add the hash path is based on whether there
> are any other paths in the rel when we reach the bottom of the
> function. create_grouping_paths() has a similar issue.
OK, I'll take a look. Quite a lot of these functions can probably stand
more local rearrangements; I've been mainly concerned about getting the
overall structure right.
(BTW, I am also suspicious that there's now dead code in places, but I've
not gone looking for that either. There is a lot of rather boring mop-up
to be done, which I left out of the v1 patch mostly to keep it from being
even more unreviewably huge than it had to be.)
> In general, and I'm sure this is not a huge surprise, most of this
> looks very good to me. I think the design is sound and that, if the
> performance is OK, we ought to move forward with it.
Thanks. As I told Teodor last night, I can't reproduce a performance
issue here with pgbench-style queries. Do you have any thoughts about
how we might satisfy ourselves whether there is or isn't a performance
problem?
regards, tom lane
On Thu, Mar 3, 2016 at 2:19 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> Thanks for working on this. Some review comments: > >> - I think all of the new path creation functions should bubble up >> parallel_degree from their subpath. > > Ah, thanks, I didn't have any clue how to set that (though in my defense, > the documentation about it is next to nonexistent). Just to confirm, > I assume the rules are: > > * parallel_aware: indicates whether the plan node itself has any > parallelism behavior > > * parallel_safe: indicates that the entire plan tree rooted at this > node is safe to execute in a parallel worker > > * parallel_degree: indicates number of parallel threads potentially > useful for this plan tree (0 if not parallel-safe) Right. > This leads me to the conclusion that all these new node types should > set parallel_aware to false and copy up the other two fields from the > child, except for LockRows and ModifyTable which should set them all > to false/0. Correct? If so, I'll go fix. Well, I'd probably bubble it up regardless. The fact that the overall plan writes data will cause everything in the plan to have parallel_safe = false and parallel_degree = 0, so you'll get the same outcome either way. However, that way, if writes eventually become safe, then this won't need adjusting. But it doesn't really matter much; feel free to do it as you say if you prefer. >> - RollupPath seems like a poor choice of name, if nothing else. You >> would expect that it would be related to GROUP BY ROLLUP() but of >> course that's really the same thing as GROUP BY GROUPING SETS () or >> GROUP BY CUBE (), and the fundamental operation is actually GROUPING >> SETS, not ROLLUP. > > As I noted to David, that thing seems to me to be in need of refactoring, > but I'd just as soon leave untangling the grouping-sets mess for later. > I don't mind substituting a different name if you have a better idea, > but don't really want to do more work than that right now. Seems reasonable. GroupingSetsPath? MultipleGroupingPath? RepeatedGroupingPath? >> - A related point that is more connected to this patch is that you've >> added 13 (!) new calls to disuse_physical_tlist, and 8 of those are >> marked with /* XXX hack: need original tlist with sortgroupref marking >> */. I don't quite understand what's going on there. I think if we're >> going to be stuck with that hack we at least need some comments >> explaining what is going on there. What has caused us to suddenly >> need these calls when we didn't before, and why these places and not >> some others? > > Yeah, that's a hack to get things working. The problem is that these node > types need to be able to identify sort/group columns in their inputs, but > if the child has switched to a "physical tlist" then the ressortgroupref > marking isn't there, and indeed the needed column might not be there at > all if it's a computed expression not a Var. So what I did for the moment > was to force the inputs back to their nominal tlists. In the old code we > didn't have this problem because none of the upper-level plan node types > could see a physical tlist unless make_subplanTargetList had allowed it, > and then we applied locate_grouping_columns() to re-identify the grouping > columns. That logic probably needs to be transposed into createplan.c, > but I've not taken the time yet to figure out exactly how. I don't know > if it's reasonable to do that separately from rethinking how the whole > disuse_physical_tlist thing works. I don't know either, but it doesn't seem good to let this linger too long. >> - For SortPath, you mention that the SortGroupClauses representation >> isn't currently used. It's not clear to me that it ever would be; >> what would be the case where that might be useful? At any rate, I'd >> be inclined to rip it out for now; you can always put it back later. > > Yeah, I was dithering about that. It seems like createplan.c now has > a few too many ways to identify sort/group columns, and I was hoping > to consolidate them somehow. That might lead to wanting to use > SortGroupClauses not PathKeys in some cases. But until that's worked > out, I agree the extra field is useless and we can just drop it. OK. >> - create_distinct_paths() disables the hash path if it seems like it >> would exceed work_mem, unless the sort path isn't viable. But there's >> something that feels a bit uncomfortable about this. Suppose the sort >> path isn't viable but some other kind of future path is viable. It >> seems like it would be better to restructure this a bit so that the >> decision about whether to add the hash path is based on whether there >> are any other paths in the rel when we reach the bottom of the >> function. create_grouping_paths() has a similar issue. > > OK, I'll take a look. Quite a lot of these functions can probably stand > more local rearrangements; I've been mainly concerned about getting the > overall structure right. Understood, but thanks for looking. > (BTW, I am also suspicious that there's now dead code in places, but I've > not gone looking for that either. There is a lot of rather boring mop-up > to be done, which I left out of the v1 patch mostly to keep it from being > even more unreviewably huge than it had to be.) OK. >> In general, and I'm sure this is not a huge surprise, most of this >> looks very good to me. I think the design is sound and that, if the >> performance is OK, we ought to move forward with it. > > Thanks. As I told Teodor last night, I can't reproduce a performance > issue here with pgbench-style queries. Do you have any thoughts about > how we might satisfy ourselves whether there is or isn't a performance > problem? One idea might be to run a whole bunch of queries and record all of the planning times, and then run them all again and compare somehow. Maybe the regression tests, for example. You'd probably have to average multiple runs, of course. Or maybe extract a small subset of the regression tests representing both simple and complex queries of a variety of types, and compare planning types with and without the patch. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Thu, Mar 3, 2016 at 2:19 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Thanks. As I told Teodor last night, I can't reproduce a performance
>> issue here with pgbench-style queries. Do you have any thoughts about
>> how we might satisfy ourselves whether there is or isn't a performance
>> problem?
> One idea might be to run a whole bunch of queries and record all of
> the planning times, and then run them all again and compare somehow.
> Maybe the regression tests, for example.
That sounds like something we could do pretty easily, though interpreting
the results might be nontrivial. There will, I expect, be a mix of
queries that do get slower as well as those that don't. As long as the
former are just queries that we hope to get some plan-quality win on,
I think that's an acceptable result ... but we'll need to record enough
data to tell what we're looking at.
For starters, I'll try logging whether the query has setops, grouping,
aggregation, window functions, and try to measure planning time change
in each of those categories.
regards, tom lane
On 4 March 2016 at 09:29, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Mar 3, 2016 at 2:19 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >> This leads me to the conclusion that all these new node types should >> set parallel_aware to false and copy up the other two fields from the >> child, except for LockRows and ModifyTable which should set them all >> to false/0. Correct? If so, I'll go fix. > > Well, I'd probably bubble it up regardless. The fact that the overall > plan writes data will cause everything in the plan to have > parallel_safe = false and parallel_degree = 0, so you'll get the same > outcome either way. However, that way, if writes eventually become > safe, then this won't need adjusting. But it doesn't really matter > much; feel free to do it as you say if you prefer. This would help me too. I hit a problem with this when adding Group Parallel Aggregate, as the sort path is conditionally added in create_grouping_paths() which causes the parallel_degree for the subpath which is later passed into create_agg_path() to become 0. in create_agg_path() I was using the parallel_degree variable to determine if I should construct a normal serial agg path, or a chain of partial agg -> gather -> final agg paths. To get around the problem I added a parallel_degree parameter to create_agg_path() of which that parameter so far seems to only exist in create_seqscan_path(), which naturally is a bit special as it's a "leaf node" in the path tree. Propagating these would mean I could remove that parameter again. -- David Rowley http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
Hi,
On 03/03/2016 01:10 AM, Tom Lane wrote:
> Hmmm ... I'm now wondering about the "measurement error" theory.
> I tried to repeat this measurement locally, focusing on the select-only
> number since that should have a higher ratio of planning time to
> execution.
>
> Test setup:
> cassert-off build
> pgbench -i -s 100
> sudo cpupower frequency-set --governor performance
>
> repeat 3 times: pgbench -c 4 -j 4 -P 5 -T 60 -S
>
> HEAD:
> tps = 32508.217002 (excluding connections establishing)
> tps = 33081.402766
> tps = 32520.859913
> average of 3: 32703 tps
>
> WITH PATCH:
> tps = 32815.922160 (excluding connections establishing)
> tps = 33312.149718
> tps = 32784.527489
> average of 3: 32970 tps
>
> (Hardware: dual quad-core Xeon E5-2609, running current RHEL6)
>
> So I see no evidence for a slowdown on pgbench's SELECT queries.
> Anybody else want to check performance on simple scan/join queries?
I did a small test today, mostly out of curiosity. And I think that
while the results are a bit noisy, there's a clear slowdown. But it's
extremely small, like ~0.5% for median/average, so I'd say it's negligible.
I used the i5-2500k machine I use for this kind of tests, and I did 30
runs of
pgbench -S -T 60 pgbench
on scale 10 database (analyzed and frozen before), both with and without
the patch applied. FWIW the machine is one of the least noisy ones when
it comes to such benchmarks.
The results look like this:
master patched diff
---------------------------------------
median 16531 16459 -0.4%
average 16526 16473 -0.3%
It's a bit more obvious when doing a scatter plot of the results (after
sorting each time series) with master on x-axis and patched on y-axis.
Ideally, we'd get the data points on a diagonal (no change) or above it
(speedup), but the points are actually below. See the chart attached.
But I do agree this is mostly at the noise level, pretty good for a
first cut that intentionally does not include any hacks. It's definitely
way below the benefits of this patch, +1 to applying this sooner than later.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Вложения
{kind=link}
On Tue, Mar 1, 2016 at 3:02 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Well, my point is that no such path would have been generated if the > subquery hadn't had an internal reason to consider sorting on b.id. > The "accidental" part of this is that the subquery's GROUP BY key > matches what the outer query needs as a mergejoin key. Hm. I can't seem to get it to generate such plans here. This is after disabling hashjoin or else it doesn't want to do a sort at all: postgres=# explain select * from (select * from v group by i) as v1 natural join (select * from v group by i) as v2; QUERY PLAN ---------------------------------------------------------------------------Merge Join (cost=107.04..111.04 rows=200 width=4) Merge Cond: (v.i = v_1.i) -> Sort (cost=53.52..54.02 rows=200 width=4) Sort Key: v.i -> HashAggregate (cost=41.88..43.88 rows=200 width=4) Group Key: v.i -> Seq Scan on v (cost=0.00..35.50rows=2550 width=4) -> Sort (cost=53.52..54.02 rows=200 width=4) Sort Key: v_1.i -> HashAggregate (cost=41.88..43.88 rows=200 width=4) Group Key: v_1.i -> Seq Scan on v v_1 (cost=0.00..35.50rows=2550 width=4) (12 rows) I'm trying to construct a torture case where it generates lots more paths than HEAD. I don't think a percent or two on planning time is significant but if there are cases where the planning time increases quickly that would be something to code against. -- greg
OK, here is a version that I think addresses all of the recent comments:
* I refactored the grouping-sets stuff as suggested by Robert and David.
The GroupingSetsPath code is now used *only* when there are grouping sets,
otherwise what you get is a plain AGG_SORTED AggPath. This allowed
removal of a boatload of weird corner cases in the GroupingSets code path,
so it was a good change. (Fundamentally, that's cleaning up some
questionable coding in the grouping sets patch rather than fixing anything
directly related to pathification, but I like the code better now.)
* I refactored the handling of targetlists in createplan.c. After some
reflection I decided that the disuse_physical_tlist callers fell into
three separate categories: those that actually needed the exact requested
tlist to be returned, those that wanted non-bloated tuples because they
were going to put them into sort or hash storage, and those that needed
grouping columns to be properly labeled. The new approach is to pass down
a "flags" word that specifies which if any of these cases apply at a
specific plan level. use_physical_tlist now always makes the right
decision to start with, and disuse_physical_tlist is gone entirely, which
should make things a bit faster since we won't uselessly construct and
discard physical tlists. The missing logic from make_subplanTargetList
and locate_grouping_columns is reincarnated in the physical-tlist code.
* Added explicit limit/offset fields to LimitPath, as requested by Teodor.
* Removed SortPath.sortgroupclauses.
* Fixed handling of parallel-query fields in new path node types.
(BTW, I found what seemed to be a couple of pre-existing bugs of
the same kind, eg create_mergejoin_path was different from the
other two kinds of join as to setting parallel_degree.)
What remains to be done, IMV:
* Performance testing as per yesterday's discussion.
* Debug support in outfuncs.c and print_path() for new node types.
* Clean up unfinished work on function header comments.
* Write some documentation about how FDWs might use this.
I'll work on the performance testing next. Barring unsatisfactory
results from that, I think this could be committable in a couple
of days.
regards, tom lane
Вложения
On Fri, Mar 4, 2016 at 11:31 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>
> OK, here is a version that I think addresses all of the recent comments:
>
> * Fixed handling of parallel-query fields in new path node types.
> (BTW, I found what seemed to be a couple of pre-existing bugs of
> the same kind, eg create_mergejoin_path was different from the
> other two kinds of join as to setting parallel_degree.)
>
I think the reason for keeping parallel_degree as zero for mergejoin path is that currently it can't participate in parallelism.
>
> OK, here is a version that I think addresses all of the recent comments:
>
> * Fixed handling of parallel-query fields in new path node types.
> (BTW, I found what seemed to be a couple of pre-existing bugs of
> the same kind, eg create_mergejoin_path was different from the
> other two kinds of join as to setting parallel_degree.)
>
I think the reason for keeping parallel_degree as zero for mergejoin path is that currently it can't participate in parallelism.
*************** create_unique_path(PlannerInfo *root, Re
*** 1440,1446 ****
pathnode->path.param_info = subpath-
>param_info;
pathnode->path.parallel_aware = false;
pathnode->path.parallel_safe = subpath->parallel_safe;
!
pathnode->path.parallel_degree = 0;
/*
* Assume the output is unsorted, since we don't necessarily
have pathkeys
--- 1445,1451 ----
pathnode->path.param_info = subpath->param_info;
pathnode-
>path.parallel_aware = false;
pathnode->path.parallel_safe = subpath->parallel_safe;
! pathnode-
>path.parallel_degree = subpath->parallel_degree;
Similar to reason for merge join path, I think this should also be set to 0.
Similarly for LimitPath, parallel_degree should be set to 0.
+ RecursiveUnionPath *
+ create_recursiveunion_path(PlannerInfo *root,
+ RelOptInfo *rel,
+ Path *leftpath,
+ Path *rightpath,
+ PathTarget *target,
+ List *distinctList,
+ int wtParam,
+ double numGroups)
+ {
+ RecursiveUnionPath *pathnode = makeNode(RecursiveUnionPath);
+
+ pathnode->path.pathtype = T_RecursiveUnion;
+ pathnode->path.parent = rel;
+ pathnode->path.pathtarget = target;
+ /* For now, assume we are above any joins, so no parameterization */
+ pathnode->path.param_info = NULL;
+ pathnode->path.parallel_aware = false;
+ pathnode->path.parallel_safe =
+ leftpath->parallel_safe && rightpath->parallel_safe;
I think here we should use rel->consider_parallel to set parallel_safe as is done in create_mergejoin_path.
+ * It's only needed atop a node that doesn't support projection
"needed atop a node", seems unclear to me, typo?
On Sat, Mar 5, 2016 at 4:51 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Fri, Mar 4, 2016 at 11:31 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> >
> > OK, here is a version that I think addresses all of the recent comments:
> >
> > * Fixed handling of parallel-query fields in new path node types.
> > (BTW, I found what seemed to be a couple of pre-existing bugs of
> > the same kind, eg create_mergejoin_path was different from the
> > other two kinds of join as to setting parallel_degree.)
> >
>
> I think the reason for keeping parallel_degree as zero for mergejoin path is that currently it can't participate in parallelism.
>
>
> *************** create_unique_path(PlannerInfo *root, Re
> *** 1440,1446 ****
> pathnode->path.param_info = subpath-
> >param_info;
> pathnode->path.parallel_aware = false;
> pathnode->path.parallel_safe = subpath->parallel_safe;
> !
> pathnode->path.parallel_degree = 0;
>
> /*
> * Assume the output is unsorted, since we don't necessarily
> have pathkeys
> --- 1445,1451 ----
> pathnode->path.param_info = subpath->param_info;
> pathnode-
> >path.parallel_aware = false;
> pathnode->path.parallel_safe = subpath->parallel_safe;
> ! pathnode-
> >path.parallel_degree = subpath->parallel_degree;
>
> Similar to reason for merge join path, I think this should also be set to 0.
>
> Similarly for LimitPath, parallel_degree should be set to 0.
>
>
> On Fri, Mar 4, 2016 at 11:31 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> >
> > OK, here is a version that I think addresses all of the recent comments:
> >
> > * Fixed handling of parallel-query fields in new path node types.
> > (BTW, I found what seemed to be a couple of pre-existing bugs of
> > the same kind, eg create_mergejoin_path was different from the
> > other two kinds of join as to setting parallel_degree.)
> >
>
> I think the reason for keeping parallel_degree as zero for mergejoin path is that currently it can't participate in parallelism.
>
>
> *************** create_unique_path(PlannerInfo *root, Re
> *** 1440,1446 ****
> pathnode->path.param_info = subpath-
> >param_info;
> pathnode->path.parallel_aware = false;
> pathnode->path.parallel_safe = subpath->parallel_safe;
> !
> pathnode->path.parallel_degree = 0;
>
> /*
> * Assume the output is unsorted, since we don't necessarily
> have pathkeys
> --- 1445,1451 ----
> pathnode->path.param_info = subpath->param_info;
> pathnode-
> >path.parallel_aware = false;
> pathnode->path.parallel_safe = subpath->parallel_safe;
> ! pathnode-
> >path.parallel_degree = subpath->parallel_degree;
>
> Similar to reason for merge join path, I think this should also be set to 0.
>
> Similarly for LimitPath, parallel_degree should be set to 0.
>
Oops, It seems Robert has made comment upthread that we should set parallel_degree from subpath except for write paths, so I think the above comment can be ignored.
Amit Kapila <amit.kapila16@gmail.com> writes:
> On Fri, Mar 4, 2016 at 11:31 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> (BTW, I found what seemed to be a couple of pre-existing bugs of
>> the same kind, eg create_mergejoin_path was different from the
>> other two kinds of join as to setting parallel_degree.)
> I think the reason for keeping parallel_degree as zero for mergejoin path
> is that currently it can't participate in parallelism.
Is there some reason why hash and nestloop are safe but merge isn't?
>> + RecursiveUnionPath *
>> + create_recursiveunion_path(PlannerInfo *root,
>> + ...
>> + pathnode->path.parallel_safe =
>> + leftpath->parallel_safe && rightpath->parallel_safe;
> I think here we should use rel->consider_parallel to set parallel_safe as
> is done in create_mergejoin_path.
Well, the "rel" is going to be an upperrel that will have been
manufactured by fetch_upper_rel, and it will contain no useful
information about parallelism, so I'm not real sure what that
would buy.
This does bring up what seems to me probably a pre-existing bug in
the parallel query planning stuff: what about parallel-safe vs
parallel-unsafe functions in join quals, or other expressions that
have to be evaluated at places above the scan level? I would expect
to see upper path nodes needing to account for parallel-safety
of the specific expressions they need to execute. However, the
existing join path node types don't have any provision for this,
so I did not feel that it was incumbent on me to fix it for the
path node types I'm adding.
> + * It's only needed atop a node that doesn't support projection
> "needed atop a node", seems unclear to me, typo?
Seems perfectly good English to me.
regards, tom lane
I wrote:
> Robert Haas <robertmhaas@gmail.com> writes:
>> One idea might be to run a whole bunch of queries and record all of
>> the planning times, and then run them all again and compare somehow.
>> Maybe the regression tests, for example.
> That sounds like something we could do pretty easily, though interpreting
> the results might be nontrivial.
I spent some time on this project. I modified the code to log the runtime
of standard_planner along with decompiled text of the passed-in query
tree. I then ran the regression tests ten times with cassert-off builds
of both current HEAD and HEAD+pathification patch, and grouped all the
numbers for log entries with identical texts. (FYI, there are around
10000 distinguishable queries in the current tests, most planned only
once or twice, but some as many as 2900 times.) I had intended to look
at the averages within each group, but that was awfully noisy; I ended up
looking at the minimum times, after discarding a few groups with
particularly awful standard deviations. I theorize that a substantial
part of the variation in the runtime depends on whether catalog entries
consulted by the planner have been sucked into syscache or not, and thus
that using the minimum is a reasonable way to eliminate cache-loading
effects, which surely ought not be considered in this comparison.
Here is a scatter plot, on log axes, of planning times in milliseconds
with HEAD (x axis) vs those with patch (y axis):
The most noticeable thing about that is that the worst percentage-wise
cases appear near the bottom end of the range. And indeed inspection
of individual entries showed that trivial cases like
SELECT (ROW(1, 2) < ROW(1, 3)) AS "true"
were hurting the most percentage-wise. After some study I decided that
the only thing that could explain that was the two rounds of
construct-an-upper-rel-and-add-paths-to-it happening in grouping_planner.
I was able to get rid of one of them by discarding the notion of
UPPERREL_INITIAL altogether, and instead having the code apply the desired
tlist in-place, like this:
sub_target = make_subplanTargetList(root, tlist,
&groupColIdx);
/*
* Forcibly apply that tlist to all the Paths for the scan/join rel.
*
* In principle we should re-run set_cheapest() here to identify the
* cheapest path, but it seems unlikely that adding the same tlist
* eval costs to all the paths would change that, so we don't bother.
* Instead, just assume that the cheapest-startup and cheapest-total
* paths remain so. (There should be no parameterized paths anymore,
* so we needn't worry about updating cheapest_parameterized_paths.)
*/
foreach(lc, current_rel->pathlist)
{
Path *subpath = (Path *) lfirst(lc);
Path *path;
Assert(subpath->param_info == NULL);
path = apply_projection_to_path(root, current_rel,
subpath, sub_target);
/* If we had to add a Result, path is different from subpath */
if (path != subpath)
{
lfirst(lc) = path;
if (subpath == current_rel->cheapest_startup_path)
current_rel->cheapest_startup_path = path;
if (subpath == current_rel->cheapest_total_path)
current_rel->cheapest_total_path = path;
}
}
With that fixed, the scatter plot looks like:
There might be some other things we could do to provide a fast-path for
particularly trivial cases. But on the whole I think this plot shows that
there's no systematic problem, and indeed not really a lot of change at
all.
I won't bother to repost the modified patch right now, but will spend some
time filling in the missing pieces first.
regards, tom lane
Вложения
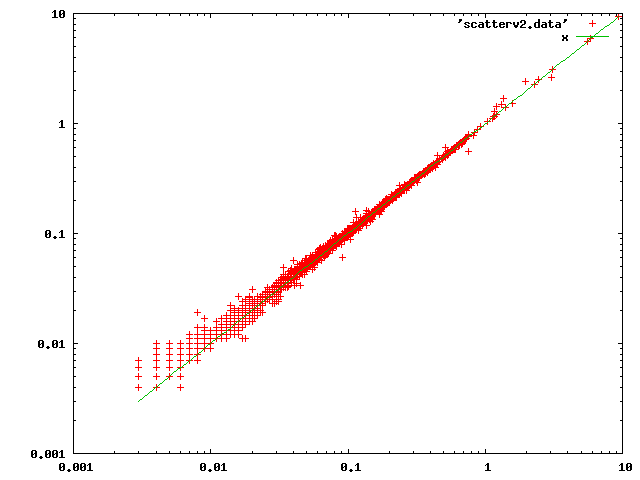{kind=link}
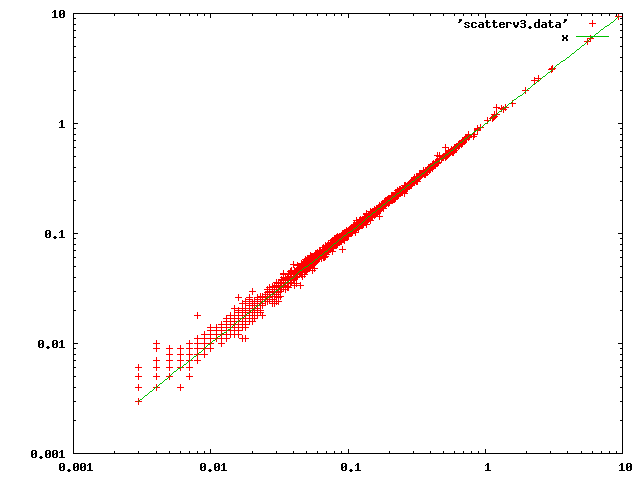{kind=link}
On Sat, Mar 5, 2016 at 6:09 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > There might be some other things we could do to provide a fast-path for > particularly trivial cases. But on the whole I think this plot shows that > there's no systematic problem, and indeed not really a lot of change at > all. Amazing data. What query is that lone data point that took 8ms instead of 6ms to plan in both charts (assuming it's the same data point)? -- greg
Greg Stark <stark@mit.edu> writes:
> What query is that lone data point that took 8ms instead of 6ms to
> plan in both charts (assuming it's the same data point)?
Ah, sorry, I should probably have spent a little more time on making those
charts. That thing you're looking at isn't a data point, it's gnuplot
showing what symbol it used for the data from this file.
Here's another one with the axes adjusted to keep the labels away from
the data, and with both sets of data overlaid. This makes it a bit
clearer that the UPPEREL_INITIAL removal moved the distribution slightly
but measurably at the bottom of the time range.
regards, tom lane
Вложения
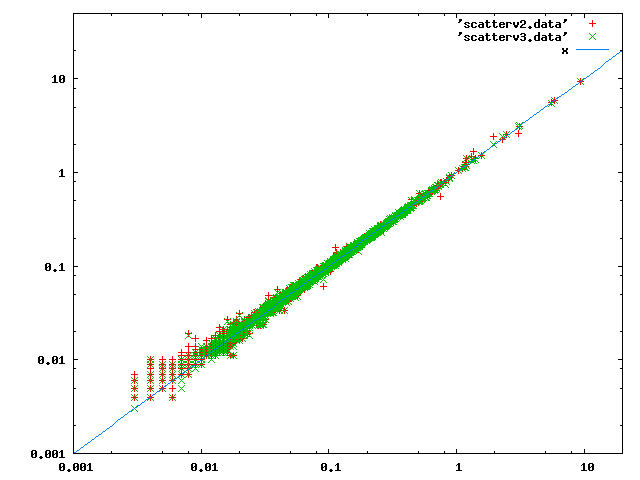{kind=link}
I wrote:
> Amit Kapila <amit.kapila16@gmail.com> writes:
>> I think here we should use rel->consider_parallel to set parallel_safe as
>> is done in create_mergejoin_path.
> Well, the "rel" is going to be an upperrel that will have been
> manufactured by fetch_upper_rel, and it will contain no useful
> information about parallelism, so I'm not real sure what that
> would buy.
Ah, after further study I found where this issue is handled for
joinrels. I think you're probably right that it'd be a good idea
to include rel->consider_parallel when setting parallel_safe in
upper paths. In the short term that will have the effect of
marking all upper paths as parallel-unsafe, but that's at least a
safe default that we can improve later.
regards, tom lane
Attached is a version that addresses today's concerns, and also finishes
filling in the loose ends I'd left before, such as documentation and
outfuncs.c support. I think this is in a committable state now, though
I plan to read through the whole thing again.
regards, tom lane
#application/x-gzip; name="upper-planner-pathification-3.patch.gz" [upper-planner-pathification-3.patch.gz]
/home/tgl/pgsql/upper-planner-pathification-3.patch.gz
I wrote:
> Attached is a version that addresses today's concerns, and also finishes
> filling in the loose ends I'd left before, such as documentation and
> outfuncs.c support. I think this is in a committable state now, though
> I plan to read through the whole thing again.
Sigh, forgot to press the magic button. Let's try that again.
regards, tom lane
Вложения
On Sat, Mar 5, 2016 at 10:11 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>
> Amit Kapila <amit.kapila16@gmail.com> writes:
> > On Fri, Mar 4, 2016 at 11:31 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> >> (BTW, I found what seemed to be a couple of pre-existing bugs of
> >> the same kind, eg create_mergejoin_path was different from the
> >> other two kinds of join as to setting parallel_degree.)
>
> > I think the reason for keeping parallel_degree as zero for mergejoin path
> > is that currently it can't participate in parallelism.
>
> Is there some reason why hash and nestloop are safe but merge isn't?
>
>
> Amit Kapila <amit.kapila16@gmail.com> writes:
> > On Fri, Mar 4, 2016 at 11:31 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> >> (BTW, I found what seemed to be a couple of pre-existing bugs of
> >> the same kind, eg create_mergejoin_path was different from the
> >> other two kinds of join as to setting parallel_degree.)
>
> > I think the reason for keeping parallel_degree as zero for mergejoin path
> > is that currently it can't participate in parallelism.
>
> Is there some reason why hash and nestloop are safe but merge isn't?
>
I think it is because we consider to pushdown hash and nestloop to workers, but not merge join and the reason for not pushing mergejoin is that currently we don't have executor support for same, more work is needed there. I think even if we set parallel_degree as you are doing in patch for merge join is harmless, but ideally there is no need to set it as far as what we support today in terms of parallelism.
Amit Kapila <amit.kapila16@gmail.com> writes:
> On Sat, Mar 5, 2016 at 10:11 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Is there some reason why hash and nestloop are safe but merge isn't?
> I think it is because we consider to pushdown hash and nestloop to workers,
> but not merge join and the reason for not pushing mergejoin is that
> currently we don't have executor support for same, more work is needed
> there.
If that's true, then mergejoin paths ought to be marked parallel-unsafe
explicitly (with a comment as to why), not just silently reduced to degree
zero in a manner that looks more like an oversight than anything
intentional.
I also note that the regression tests pass with this patch and parallel
mode forced, which seems unlikely if allowing a parallel worker to execute
a join works for only two out of the three join types. And checking the
git history for nodeHashjoin.c, nodeHash.c, and nodeNestloop.c shows no
evidence that any of those files have been touched for parallel query,
so it's pretty hard to see a reason why those would work in parallel
queries but nodeMergejoin.c not.
I still say the code as it stands is merely a copy-and-pasteo.
regards, tom lane
On Sun, Mar 6, 2016 at 9:02 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>
> Amit Kapila <amit.kapila16@gmail.com> writes:
> > On Sat, Mar 5, 2016 at 10:11 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> >> Is there some reason why hash and nestloop are safe but merge isn't?
>
> > I think it is because we consider to pushdown hash and nestloop to workers,
> > but not merge join and the reason for not pushing mergejoin is that
> > currently we don't have executor support for same, more work is needed
> > there.
>
> If that's true, then mergejoin paths ought to be marked parallel-unsafe
> explicitly (with a comment as to why), not just silently reduced to degree
> zero in a manner that looks more like an oversight than anything
> intentional.
>
> I also note that the regression tests pass with this patch and parallel
> mode forced, which seems unlikely if allowing a parallel worker to execute
> a join works for only two out of the three join types. And checking the
> git history for nodeHashjoin.c, nodeHash.c, and nodeNestloop.c shows no
> evidence that any of those files have been touched for parallel query,
> so it's pretty hard to see a reason why those would work in parallel
> queries but nodeMergejoin.c not.
>
>
> Amit Kapila <amit.kapila16@gmail.com> writes:
> > On Sat, Mar 5, 2016 at 10:11 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> >> Is there some reason why hash and nestloop are safe but merge isn't?
>
> > I think it is because we consider to pushdown hash and nestloop to workers,
> > but not merge join and the reason for not pushing mergejoin is that
> > currently we don't have executor support for same, more work is needed
> > there.
>
> If that's true, then mergejoin paths ought to be marked parallel-unsafe
> explicitly (with a comment as to why), not just silently reduced to degree
> zero in a manner that looks more like an oversight than anything
> intentional.
>
> I also note that the regression tests pass with this patch and parallel
> mode forced, which seems unlikely if allowing a parallel worker to execute
> a join works for only two out of the three join types. And checking the
> git history for nodeHashjoin.c, nodeHash.c, and nodeNestloop.c shows no
> evidence that any of those files have been touched for parallel query,
> so it's pretty hard to see a reason why those would work in parallel
> queries but nodeMergejoin.c not.
>
To make hash and nestloop work in parallel queries, we just push those nodes below gather node. Refer code paths match_unsorted_outer()->consider_parallel_nestloop() and hash_inner_and_outer()->try_partial_hashjoin_path(). Once the partial path for hash and nestloop gets generated in above code path, we generate gather path in function add_paths_to_joinrel()->generate_gather_paths(). You won't find the code to generate partial path for merge join.
Amit Kapila <amit.kapila16@gmail.com> writes:
>>>> Is there some reason why hash and nestloop are safe but merge isn't?
> To make hash and nestloop work in parallel queries, we just push those
> nodes below gather node. Refer code
> paths match_unsorted_outer()->consider_parallel_nestloop()
> and hash_inner_and_outer()->try_partial_hashjoin_path().
AFAICS, those are about generating partial paths, which is a completely
different thing from whether a regular path is parallel-safe or not.
(I think, anyway. It would be nice if this stuff were documented better.
It would also likely be a good thing if partial-ness of a path were marked
in the path itself, which does not seem to be the case now. Or at the
very least, it'd be a good thing if create_foo_path and the underlying
costing functions were told it was a partial path, because how the heck
can they generate sane cost numbers without that knowledge?)
regards, tom lane
On Mon, Mar 7, 2016 at 9:13 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>
> Amit Kapila <amit.kapila16@gmail.com> writes:
> >>>> Is there some reason why hash and nestloop are safe but merge isn't?
>
> > To make hash and nestloop work in parallel queries, we just push those
> > nodes below gather node. Refer code
> > paths match_unsorted_outer()->consider_parallel_nestloop()
> > and hash_inner_and_outer()->try_partial_hashjoin_path().
>
> AFAICS, those are about generating partial paths, which is a completely
> different thing from whether a regular path is parallel-safe or not.
>
> Amit Kapila <amit.kapila16@gmail.com> writes:
> >>>> Is there some reason why hash and nestloop are safe but merge isn't?
>
> > To make hash and nestloop work in parallel queries, we just push those
> > nodes below gather node. Refer code
> > paths match_unsorted_outer()->consider_parallel_nestloop()
> > and hash_inner_and_outer()->try_partial_hashjoin_path().
>
> AFAICS, those are about generating partial paths, which is a completely
> different thing from whether a regular path is parallel-safe or not.
>
Okay, but the main point I wanted to convey is that I think setting parallel_degree = 0 in mergejoin path is not necessarily a copy-paste error. If you see the other path generation code like create_index_path(), create_samplescan_path(), etc. there we set parallel_degree to zero even though the parallel-safety is determined based on reloptinfo. And I don't see any use of setting parallel_degree for path which can't be pushed beneath gather (aka can be executed by multiple workers).
Amit Kapila <amit.kapila16@gmail.com> writes:
> On Mon, Mar 7, 2016 at 9:13 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> AFAICS, those are about generating partial paths, which is a completely
>> different thing from whether a regular path is parallel-safe or not.
> Okay, but the main point I wanted to convey is that I think setting
> parallel_degree = 0 in mergejoin path is not necessarily a copy-paste
> error.
Perhaps it was intentional when written, but if Robert's advice is correct
that the new upper-planner path nodes should copy up parallel_degree from
their children, then it cannot be the case that parallel_degree>0 in a
node above the scan level implies that that node type has any special
behavior for parallelism.
I continue to bemoan the lack of documentation about what these fields
mean. As far as I can find, the sum total of the documentation about
this field is
int parallel_degree; /* desired parallel degree; 0 = not parallel */
Last I checked, "degree" meant 1/360'th part of a circle, or some
fraction of the distance between water's freezing and boiling points,
or possibly an award for academic achievement. So I'm not really
going to hold still for any claim that this is self-explanatory.
regards, tom lane
On Sun, Mar 6, 2016 at 9:59 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Perhaps it was intentional when written, but if Robert's advice is correct > that the new upper-planner path nodes should copy up parallel_degree from > their children, then it cannot be the case that parallel_degree>0 in a > node above the scan level implies that that node type has any special > behavior for parallelism. > > I continue to bemoan the lack of documentation about what these fields > mean. As far as I can find, the sum total of the documentation about > this field is > > int parallel_degree; /* desired parallel degree; 0 = not parallel */ While it doesn't particularly relate to parallel joins, I've expressed a general concern about the max_parallel_degree GUC that I think is worth considering again: http://www.postgresql.org/message-id/CAM3SWZRs1mTvrKkAsY1XBShGZXkD6-HNxX3gq7x-p-dz0ZtkMg@mail.gmail.com In summary, I think it's surprising that a max_parallel_degree of 1 doesn't disable parallel workers entirely. -- Peter Geoghegan
Peter Geoghegan <pg@heroku.com> writes:
> In summary, I think it's surprising that a max_parallel_degree of 1
> doesn't disable parallel workers entirely.
Yeah, it's not exactly clear what "1" should mean that's different
from "0", in this case.
regards, tom lane
On Mon, Mar 7, 2016 at 11:52 AM, Peter Geoghegan <pg@heroku.com> wrote:
>
> On Sun, Mar 6, 2016 at 9:59 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> > Perhaps it was intentional when written, but if Robert's advice is correct
> > that the new upper-planner path nodes should copy up parallel_degree from
> > their children, then it cannot be the case that parallel_degree>0 in a
> > node above the scan level implies that that node type has any special
> > behavior for parallelism.
> >
Right.
>
> > I continue to bemoan the lack of documentation about what these fields
> > mean.
>
> On Sun, Mar 6, 2016 at 9:59 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> > Perhaps it was intentional when written, but if Robert's advice is correct
> > that the new upper-planner path nodes should copy up parallel_degree from
> > their children, then it cannot be the case that parallel_degree>0 in a
> > node above the scan level implies that that node type has any special
> > behavior for parallelism.
> >
Right.
>
> > I continue to bemoan the lack of documentation about what these fields
> > mean.
> >
Point taken and if Robert doesn't feel otherwise, I can try to write a patch to explain the newly added fields.
> > As far as I can find, the sum total of the documentation about
> > this field is
> >
> > int parallel_degree; /* desired parallel degree; 0 = not parallel */
>
> While it doesn't particularly relate to parallel joins, I've expressed
> a general concern about the max_parallel_degree GUC that I think is
> worth considering again:
>
> http://www.postgresql.org/message-id/CAM3SWZRs1mTvrKkAsY1XBShGZXkD6-HNxX3gq7x-p-dz0ZtkMg@mail.gmail.com
>
> In summary, I think it's surprising that a max_parallel_degree of 1
> doesn't disable parallel workers entirely.
>
> > this field is
> >
> > int parallel_degree; /* desired parallel degree; 0 = not parallel */
>
> While it doesn't particularly relate to parallel joins, I've expressed
> a general concern about the max_parallel_degree GUC that I think is
> worth considering again:
>
> http://www.postgresql.org/message-id/CAM3SWZRs1mTvrKkAsY1XBShGZXkD6-HNxX3gq7x-p-dz0ZtkMg@mail.gmail.com
>
> In summary, I think it's surprising that a max_parallel_degree of 1
> doesn't disable parallel workers entirely.
>
I have responded on the thread where you have raised that point with my thoughts, discussing it here on a separate point can dilute the purpose of this thread.
On Sun, Mar 6, 2016 at 10:32 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Amit Kapila <amit.kapila16@gmail.com> writes: >> On Sat, Mar 5, 2016 at 10:11 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> Is there some reason why hash and nestloop are safe but merge isn't? > >> I think it is because we consider to pushdown hash and nestloop to workers, >> but not merge join and the reason for not pushing mergejoin is that >> currently we don't have executor support for same, more work is needed >> there. > > If that's true, then mergejoin paths ought to be marked parallel-unsafe > explicitly (with a comment as to why), not just silently reduced to degree > zero in a manner that looks more like an oversight than anything > intentional. > > I also note that the regression tests pass with this patch and parallel > mode forced, which seems unlikely if allowing a parallel worker to execute > a join works for only two out of the three join types. And checking the > git history for nodeHashjoin.c, nodeHash.c, and nodeNestloop.c shows no > evidence that any of those files have been touched for parallel query, > so it's pretty hard to see a reason why those would work in parallel > queries but nodeMergejoin.c not. > > I still say the code as it stands is merely a copy-and-pasteo. I might call it a thinko rather than a copy-and-pasteo, but basically, you are right and Amit is wrong. I feel confident making that statement because I wrote the code, so I think I'm well-positioned to judge whether I did a particular thing on purpose or not. The currently-committed code generates paths where nested loops and hash joins get pushed beneath the Gather node, but does not generate paths where merge joins have been pushed beneath the Gather node. And the reason I didn't try to generate those paths is because I believe they will almost always suck. As of now, what we know how to do is build a partial path for a join by joining a partial path for the outer input rel against an ordinary path for the inner rel. That means that the work of generating the inner rel has to be redone in each worker. That's not a problem if we've got something like a nested loop with a parameterized inner index scan, because that sort of plan redoes all the work for every row anyway. It is a problem for a hash join, but it's not too hard for it to be worthwhile anyway if the build table is small. For a merge join, though, it seems rather unpromising. It's really doubtful that we want each worker to independently sort the inner rel and then have them join their own subset of the outer rel against their own copy of the sort. *Maybe* it could win if the inner path is an index scan, but I wasn't really sure that would come up and be a win often enough to be worth the cost of generating the path. We tend to only use merge joins when both of the relations involved are large, and index-scanning a large relation tends to lose to sorting it. So it just seemed like a dead end. Now, if somebody comes along with a patch to create partial merge join paths and shows that it improves performance on some class of queries I haven't thought about, I am not going to complain. And in the long run, I would like to have a facility to partition both relations on the fly and then have the workers do a merge join per partition. That's one of the two standard algorithms in the literature for parallel join - hash join is the other. I'm quite certain that's an important piece of technology to develop, but it's a huge project unto itself. My priority for 9.6 is to have a user-visible feature that takes the infrastructure that we already have as far as it reasonably can go. Building new infrastructure will have to wait for a future release. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> The currently-committed code generates paths where nested loops and
> hash joins get pushed beneath the Gather node, but does not generate
> paths where merge joins have been pushed beneath the Gather node. And
> the reason I didn't try to generate those paths is because I believe
> they will almost always suck.
That's a perfectly reasonable engineering judgment (and especially so
for a first release). What I'd really like to see documented is how
that conclusion is related, or not, to the rules about how path nodes
should be decorated with parallel_safe, parallel_degree, etc annotations.
The existing documentation is barely adequate to explain what those fields
mean for primitive scan nodes; it's impossible for anyone but you to
know what they are supposed to mean for joins and higher-level nodes.
regards, tom lane
On Mon, Mar 7, 2016 at 3:37 PM, Robert Haas <robertmhaas@gmail.com> wrote: > > The currently-committed code generates paths where nested loops and > hash joins get pushed beneath the Gather node, but does not generate > paths where merge joins have been pushed beneath the Gather node. And > the reason I didn't try to generate those paths is because I believe > they will almost always suck. As of now, what we know how to do is > build a partial path for a join by joining a partial path for the > outer input rel against an ordinary path for the inner rel. That > means that the work of generating the inner rel has to be redone in > each worker. That's not a problem if we've got something like a > nested loop with a parameterized inner index scan, because that sort > of plan redoes all the work for every row anyway. It is a problem for > a hash join, but it's not too hard for it to be worthwhile anyway if > the build table is small. For a merge join, though, it seems rather > unpromising. It's really doubtful that we want each worker to > independently sort the inner rel and then have them join their own > subset of the outer rel against their own copy of the sort. *Maybe* > it could win if the inner path is an index scan, but I wasn't really > sure that would come up and be a win often enough to be worth the cost > of generating the path. We tend to only use merge joins when both of > the relations involved are large, and index-scanning a large relation > tends to lose to sorting it. So it just seemed like a dead end. This is the first message on this subthread that actually gave me a feeling I understood the issue under discussion. It explains the distinction between plans that are parallel-safe and plans that would actually do something different under a parallel worker -- greg
On Mon, Mar 7, 2016 at 11:09 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> The currently-committed code generates paths where nested loops and >> hash joins get pushed beneath the Gather node, but does not generate >> paths where merge joins have been pushed beneath the Gather node. And >> the reason I didn't try to generate those paths is because I believe >> they will almost always suck. > > That's a perfectly reasonable engineering judgment (and especially so > for a first release). What I'd really like to see documented is how > that conclusion is related, or not, to the rules about how path nodes > should be decorated with parallel_safe, parallel_degree, etc annotations. > The existing documentation is barely adequate to explain what those fields > mean for primitive scan nodes; it's impossible for anyone but you to > know what they are supposed to mean for joins and higher-level nodes. It is unrelated, I think. If a path is parallel_safe, that is supposed to mean that, in theory, the plan generated from that path could be executed within a worker without crashing the server, giving wrong answers, or otherwise destroying the world. However, as an optimization, if we've already decided that the query can't ever be parallelized at all, for example because it contains write operations, we don't bother trying to set the parallel_safe flags correctly; they're just all false. Generally, a path is definitely not parallel_safe if it contains a path that is not parallel_safe; if all of the paths under it are parallel_safe, then it is also parallel_safe except when there's some unsafe computation added at the new level -- like an unsafe join qual between two safe relations. If a path is parallel_aware, that means that the plan generated by that path wants to do something different when run in parallel mode. Presumably, the difference will be that the plan will establish some shared state in the dynamic shared memory segment created to service that parallel query. For example, a sequential scan can be parallel_aware, which will allow that sequential scan to be simultaneously executed in multiple processes and return only a subset of the rows in each. A non-parallel_aware sequential scan can still be used in parallel mode; for example, consider this: Gather -> Hash Join -> Parallel Seq Scan -> Hash -> Seq Scan The outer seq scan needs to return each row only once across all workers, but the inner seq scan needs to return every row in every worker. Therefore, the outer seq scan is flagged parallel_aware and displays in the EXPLAIN output as "Parallel Seq Scan", while the inner one is not and does not. parallel_degree is a horrible kludge whose function is to communicate to the Gather node the number of workers for which it should budget. Currently, every parallel plan's leftmost descendent will be a Parallel Seq Scan, and that Parallel Seq Scan will estimate the degree of parallelism that makes sense using a simplistic, bone-headed algorithm based on the size of the table. That then bubbles up the plan tree to the Gather node, which adopts the Parallel Seq Scan's suggestion. I really hope this is going to go away eventually and be replaced by something better. Really, I think we should try to figure out the amount of parallelizable work (CPU, and effective I/O parallelism) that is going to be required per leftmost tuple and compare that to the amount of non-parallelizable work (presumably, the reset of the I/O cost) and use that to judge the optimal parallel degree. But I think that's going to take a lot of work to get right, and it ties into some other issues, like the fact that we estimate a scan of a 1MB table to have the same cost per page as a scan of a 10TB table even though the former should probably be assumed to be fully cached and the latter should probably be assumed not to be cached at all. I think a lot more thought is needed here than I've given it thus far, and one of the things that I'm hoping is that people will test parallel query and actually report the results so that we can accumulate some data on which problems are most important to go fix and, also, what the shape of those fixes might look like. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
I wrote:
>> Attached is a version that addresses today's concerns, and also finishes
>> filling in the loose ends I'd left before, such as documentation and
>> outfuncs.c support. I think this is in a committable state now, though
>> I plan to read through the whole thing again.
The extra read-through located some minor bugs, mainly places where I'd
forgotten to ensure that Path cost info was transposed into the generated
Plan. That would only have the cosmetic effect that EXPLAIN would print
zeroes for estimated costs, and since we only use EXPLAIN COSTS OFF in
the regression tests, no test failures ensued :-(.
I've pushed it now; we'll soon see if the buildfarm finds any problems.
regards, tom lane
On 8 March 2016 at 10:01, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I've pushed it now; we'll soon see if the buildfarm finds any problems. Fantastic! I'm looking forward to all the future optimisation opportunities that this opens up. Thanks for making this happen. -- David Rowley http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
I wrote:
> There might be some other things we could do to provide a fast-path for
> particularly trivial cases.
I wanted to look into that before the code or tests had drifted far enough
to make comparisons dubious. Attached is a simple patch that lets
grouping_planner fall out with a minimum amount of work if the query is
just "SELECT expression(s)", and a couple of scatter plots of regression
test query timing. The first plot compares pre-pathification timing with
HEAD+this patch, and the second compares HEAD with HEAD+this patch.
I had hoped to see more of a benefit, actually, but it seems like this
might be enough of a win to be worth committing. Probably the main
argument against it is that we'd have to remember to maintain the list
of things-to-check-before-using-the-fast-path.
Thoughts?
regards, tom lane
diff --git a/src/backend/optimizer/plan/planner.c b/src/backend/optimizer/plan/planner.c
index 5fc8e5b..151f27f 100644
*** a/src/backend/optimizer/plan/planner.c
--- b/src/backend/optimizer/plan/planner.c
*************** grouping_planner(PlannerInfo *root, bool
*** 1458,1463 ****
--- 1458,1504 ----
parse->sortClause,
tlist);
}
+ else if (parse->rtable == NIL &&
+ parse->commandType == CMD_SELECT &&
+ parse->jointree->quals == NULL &&
+ !parse->hasAggs && !parse->hasWindowFuncs &&
+ parse->groupClause == NIL && parse->groupingSets == NIL &&
+ !root->hasHavingQual &&
+ parse->distinctClause == NIL &&
+ parse->sortClause == NIL &&
+ parse->limitOffset == NULL && parse->limitCount == NULL)
+ {
+ /*
+ * Trivial "SELECT expression(s)" query. This case would be handled
+ * correctly by the code below, but it comes up often enough to be
+ * worth having a simplified fast-path for. Need only create a Result
+ * path with the desired targetlist and shove it into the final rel.
+ */
+ Path *path;
+ double tlist_rows;
+
+ /* Need not bother with preprocess_targetlist in a SELECT */
+ root->processed_tlist = tlist;
+
+ final_rel = fetch_upper_rel(root, UPPERREL_FINAL, NULL);
+
+ path = (Path *) create_result_path(final_rel,
+ create_pathtarget(root, tlist),
+ NIL);
+
+ /* We do take the trouble to fix the rows estimate for SRFs, though */
+ tlist_rows = tlist_returns_set_rows(tlist);
+ if (tlist_rows > 1)
+ {
+ path->total_cost += path->rows * (tlist_rows - 1) *
+ cpu_tuple_cost / 2;
+ path->rows *= tlist_rows;
+ }
+
+ add_path(final_rel, path);
+
+ return;
+ }
else
{
/* No set operations, do regular planning */
Вложения
{kind=link}
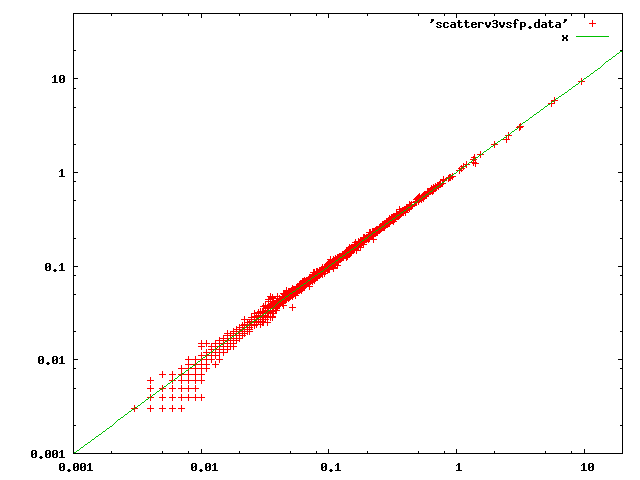{kind=link}
Hi, Tom!
I have a question about Sort path. AFAICS this question wasn't mentioned in the upthread discussion.
We're producing Sort plans in two ways: from explicit Sort paths, and from other paths which implicitly assumes sorting (like MergeJoin path).
Would it be better to produce Sort plan only from explicit Sort path? Thus, MergeJoin path would add explicit children Sort paths. That would be more unified way.
I ask about this from point of view of my "Partial Sort" patch. The absence of implicit sorts would help to make this patch more simple and clean.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Tue, Mar 8, 2016 at 2:31 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>
> I wrote:
> >> Attached is a version that addresses today's concerns, and also finishes
> >> filling in the loose ends I'd left before, such as documentation and
> >> outfuncs.c support. I think this is in a committable state now, though
> >> I plan to read through the whole thing again.
>
> The extra read-through located some minor bugs, mainly places where I'd
> forgotten to ensure that Path cost info was transposed into the generated
> Plan. That would only have the cosmetic effect that EXPLAIN would print
> zeroes for estimated costs, and since we only use EXPLAIN COSTS OFF in
> the regression tests, no test failures ensued :-(.
>
> I've pushed it now; we'll soon see if the buildfarm finds any problems.
>
>
> I wrote:
> >> Attached is a version that addresses today's concerns, and also finishes
> >> filling in the loose ends I'd left before, such as documentation and
> >> outfuncs.c support. I think this is in a committable state now, though
> >> I plan to read through the whole thing again.
>
> The extra read-through located some minor bugs, mainly places where I'd
> forgotten to ensure that Path cost info was transposed into the generated
> Plan. That would only have the cosmetic effect that EXPLAIN would print
> zeroes for estimated costs, and since we only use EXPLAIN COSTS OFF in
> the regression tests, no test failures ensued :-(.
>
> I've pushed it now; we'll soon see if the buildfarm finds any problems.
>
On latest commit-51c0f63e, I am seeing some issues w.r.t parallel query. Consider a below case:
create table t1(c1 int, c2 char(1000));
insert into t1 values(generate_series(1,300000),'aaaa');
analyze t1;
set max_parallel_degree=2;
postgres=# explain select c1, count(c1) from t1 where c1 < 1000 group by c1;
ERROR: ORDER/GROUP BY expression not found in targetlist
Without setting max_parallel_degree, it works fine and generate the appropriate results. Here the issue seems to be that the code in grouping_planner doesn't apply the required PathTarget to Path below Gather Path due to which when we generate target list for scan plan, it misses the required information which in this case is sortgrouprefs and the same target list is then propagated for upper nodes which eventually leads to the above mentioned failure. Due to same reason, if the target list contains some expression, it will give wrong results when parallel query is used. I could see below ways to solve this issue.
Approach-1
-----------------
First way to solve this issue is to jam the PathTarget for partial paths similar to what we are doing for Paths and I have verified that resolves the issue, the patch for same is attached with this mail. However, it won't work as-is, because this will make target lists pushed to workers as we have applied them below Gather Path which we don't want if the target list has any parallel unsafe functions. To make this approach work, we need to ensure that we jam the PathTarget for partial paths (or generate a projection) only if they contain parallel-safe expressions. Now while creating Gather Plan (create_gather_plan()), we need to ensure in some way that if path below doesn't generate the required tlist, then it should generate it's own tlist rather than using it from subplan.
Approach-2
------------------
Always generate a tlist in Gather plan as we do for many other cases. I think this approach will also resolve the issue but haven't tried yet.
Approach-1 has a benefit that it can allow to push target lists to workers which will result in speed-up of parallel queries especially for cases when target list contain costly expressions, so I am slightly inclined to follow that even though that looks more work.
Thoughts?
Вложения
Alexander Korotkov <a.korotkov@postgrespro.ru> writes:
> I have a question about Sort path. AFAICS this question wasn't mentioned in
> the upthread discussion.
> We're producing Sort plans in two ways: from explicit Sort paths, and from
> other paths which implicitly assumes sorting (like MergeJoin path).
> Would it be better to produce Sort plan only from explicit Sort path? Thus,
> MergeJoin path would add explicit children Sort paths. That would be more
> unified way.
Meh. I think the only real effect that would have is to make it slower to
build MergeJoin paths (and in a typical join problem, we build a lot of
those). The entire point of the Path/Plan distinction is to postpone
until createplan.c any work that's not necessary to arrive at a cost
estimate. So the way MergeJoinPath works now seems fine to me.
> I ask about this from point of view of my "Partial Sort" patch. The absence
> of implicit sorts would help to make this patch more simple and clean.
There are other implicit sorts besides those. Admittedly, the efficiency
argument for not making the sort explicit in UniquePath or MergeAppendPath
is a lot weaker than it is for MergeJoin, just because those are less
common path types. But getting rid of the behavior entirely would be
a lot of work, and I'm not convinced it'd be an improvement.
regards, tom lane
Amit Kapila <amit.kapila16@gmail.com> writes:
> On latest commit-51c0f63e, I am seeing some issues w.r.t parallel query.
> Consider a below case:
> create table t1(c1 int, c2 char(1000));
> insert into t1 values(generate_series(1,300000),'aaaa');
> analyze t1;
> set max_parallel_degree=2;
> postgres=# explain select c1, count(c1) from t1 where c1 < 1000 group by c1;
> ERROR: ORDER/GROUP BY expression not found in targetlist
Hm. That does not speak well for the coverage of the "run the regression
tests with force_parallel_mode enabled" testing approach.
> Without setting max_parallel_degree, it works fine and generate the
> appropriate results. Here the issue seems to be that the code in
> grouping_planner doesn't apply the required PathTarget to Path below Gather
> Path due to which when we generate target list for scan plan,
Yeah, fixed. I had assumed that the existing coding in create_gather_plan
was OK, because it looked like it was right for a non-projecting node.
But actually Gather can project (why though?), so it's not right.
> Approach-2
> ------------------
> Always generate a tlist in Gather plan as we do for many other cases. I
> think this approach will also resolve the issue but haven't tried yet.
I think this is the correct fix.
regards, tom lane
Tom Lane wrote: > Amit Kapila <amit.kapila16@gmail.com> writes: > > Without setting max_parallel_degree, it works fine and generate the > > appropriate results. Here the issue seems to be that the code in > > grouping_planner doesn't apply the required PathTarget to Path below Gather > > Path due to which when we generate target list for scan plan, > > Yeah, fixed. I had assumed that the existing coding in create_gather_plan > was OK, because it looked like it was right for a non-projecting node. > But actually Gather can project (why though?), so it's not right. This looks related: https://www.postgresql.org/message-id/CA%2BTgmoai9Ruhwk61110rY4cNAzoO6npsFEOaEKjM7Zz8i3evHg%40mail.gmail.com -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Mar 9, 2016 at 12:07 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > Tom Lane wrote: >> Amit Kapila <amit.kapila16@gmail.com> writes: > >> > Without setting max_parallel_degree, it works fine and generate the >> > appropriate results. Here the issue seems to be that the code in >> > grouping_planner doesn't apply the required PathTarget to Path below Gather >> > Path due to which when we generate target list for scan plan, >> >> Yeah, fixed. I had assumed that the existing coding in create_gather_plan >> was OK, because it looked like it was right for a non-projecting node. >> But actually Gather can project (why though?), so it's not right. > > This looks related: > https://www.postgresql.org/message-id/CA%2BTgmoai9Ruhwk61110rY4cNAzoO6npsFEOaEKjM7Zz8i3evHg%40mail.gmail.com I actually wrote a patch for this: http://www.postgresql.org/message-id/CA+TgmoaqWH8W35c7pssuufxOO=AxNEQEN4da_BkeQaA3SE33QQ@mail.gmail.com I assume it no longer applies :-( but I think it would be good to get this into 9.6. It's a pretty simple optimization with a lot to recommend it. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Alvaro Herrera <alvherre@2ndquadrant.com> writes: > Tom Lane wrote: >> Yeah, fixed. I had assumed that the existing coding in create_gather_plan >> was OK, because it looked like it was right for a non-projecting node. >> But actually Gather can project (why though?), so it's not right. > This looks related: > https://www.postgresql.org/message-id/CA%2BTgmoai9Ruhwk61110rY4cNAzoO6npsFEOaEKjM7Zz8i3evHg%40mail.gmail.com Ah, thanks for remembering that thread; I'd forgotten it. Gather is a bit weird, because although it can project (and needs to, per the example of needing to compute a non-parallel-safe function), you would rather push down as much work as possible to the child node; and doing so is semantically OK for parallel-safe functions. (Pushing functions down past a Sort node, for a counterexample, is not so OK if you are concerned about function evaluation order, or even number of executions.) In the current code structure it would perhaps be reasonable to teach apply_projection_to_path about that --- although this would require logic to separate parallel-safe and non-parallel-safe subexpressions, which doesn't quite seem like something apply_projection_to_path should be doing. This seems rather closely related to the discussion around Konstantin Knizhnik's patch to delay function evaluations to after the ORDER BY sort when possible/useful. What I think that patch should be doing is for grouping_planner (or subroutines thereof) to classify tlist items as volatile or expensive or not and generate pre-sort and post-sort targetlists appropriately. That's okay for a top-level feature like ORDER BY, but it doesn't work for Gather which can appear much further down in the plan. So maybe apply_projection_to_path is the only feasible place. regards, tom lane
On Wed, Mar 9, 2016 at 12:33 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Alvaro Herrera <alvherre@2ndquadrant.com> writes: >> Tom Lane wrote: >>> Yeah, fixed. I had assumed that the existing coding in create_gather_plan >>> was OK, because it looked like it was right for a non-projecting node. >>> But actually Gather can project (why though?), so it's not right. > >> This looks related: >> https://www.postgresql.org/message-id/CA%2BTgmoai9Ruhwk61110rY4cNAzoO6npsFEOaEKjM7Zz8i3evHg%40mail.gmail.com > > Ah, thanks for remembering that thread; I'd forgotten it. > > Gather is a bit weird, because although it can project (and needs to, > per the example of needing to compute a non-parallel-safe function), > you would rather push down as much work as possible to the child node; > and doing so is semantically OK for parallel-safe functions. (Pushing > functions down past a Sort node, for a counterexample, is not so OK > if you are concerned about function evaluation order, or even number > of executions.) > > In the current code structure it would perhaps be reasonable to teach > apply_projection_to_path about that --- although this would require > logic to separate parallel-safe and non-parallel-safe subexpressions, > which doesn't quite seem like something apply_projection_to_path > should be doing. I think for v1 it would be fine to make this all-or-nothing; that's what I had in mind to do. That is, if the entire tlist is parallel-safe, push it all down. If not, let the workers just return the necessary Vars and have Gather compute the final tlist. Now, obviously one could do better. If the tlist contains several expensive functions that are parallel-safe and one inexpensive function that isn't, you'd obviously prefer to compute the parallel-safe stuff in the workers and just compute the one inexpensive thing in the leader. But that's significantly more complicated and I'm not sure it's worth spending a lot of time getting it right just now. Not that I'm complaining if you feel the urge. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Mar 9, 2016 at 5:47 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
Alexander Korotkov <a.korotkov@postgrespro.ru> writes:
> I have a question about Sort path. AFAICS this question wasn't mentioned in
> the upthread discussion.
> We're producing Sort plans in two ways: from explicit Sort paths, and from
> other paths which implicitly assumes sorting (like MergeJoin path).
> Would it be better to produce Sort plan only from explicit Sort path? Thus,
> MergeJoin path would add explicit children Sort paths. That would be more
> unified way.
Meh. I think the only real effect that would have is to make it slower to
build MergeJoin paths (and in a typical join problem, we build a lot of
those). The entire point of the Path/Plan distinction is to postpone
until createplan.c any work that's not necessary to arrive at a cost
estimate. So the way MergeJoinPath works now seems fine to me.
> I ask about this from point of view of my "Partial Sort" patch. The absence
> of implicit sorts would help to make this patch more simple and clean.
There are other implicit sorts besides those. Admittedly, the efficiency
argument for not making the sort explicit in UniquePath or MergeAppendPath
is a lot weaker than it is for MergeJoin, just because those are less
common path types. But getting rid of the behavior entirely would be
a lot of work, and I'm not convinced it'd be an improvement.
Thank you for the explanation. I'll try to rebase "Partial Sort" leaving this situation as is.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Hi Tom, On 2016-02-28 15:03:28 -0500, Tom Lane wrote: > diff --git a/src/include/optimizer/planmain.h b/src/include/optimizer/planmain.h > index eaa642b..cd7338a 100644 > *** a/src/include/optimizer/planmain.h > --- b/src/include/optimizer/planmain.h > *************** extern RelOptInfo *query_planner(Planner > *** 43,102 **** > * prototypes for plan/planagg.c > */ > extern void preprocess_minmax_aggregates(PlannerInfo *root, List *tlist); > - extern Plan *optimize_minmax_aggregates(PlannerInfo *root, List *tlist, > - const AggClauseCosts *aggcosts, Path *best_path); > > /* > * prototypes for plan/createplan.c > */ > extern Plan *create_plan(PlannerInfo *root, Path *best_path); > - extern SubqueryScan *make_subqueryscan(List *qptlist, List *qpqual, > - Index scanrelid, Plan *subplan); > extern ForeignScan *make_foreignscan(List *qptlist, List *qpqual, > Index scanrelid, List *fdw_exprs, List *fdw_private, > List *fdw_scan_tlist, List *fdw_recheck_quals, > Plan *outer_plan); > - extern Append *make_append(List *appendplans, List *tlist); > - extern RecursiveUnion *make_recursive_union(List *tlist, > - Plan *lefttree, Plan *righttree, int wtParam, > - List *distinctList, long numGroups); > - extern Sort *make_sort_from_pathkeys(PlannerInfo *root, Plan *lefttree, > - List *pathkeys, double limit_tuples); > - extern Sort *make_sort_from_sortclauses(PlannerInfo *root, List *sortcls, > - Plan *lefttree); > - extern Sort *make_sort_from_groupcols(PlannerInfo *root, List *groupcls, > - AttrNumber *grpColIdx, Plan *lefttree); > - extern Agg *make_agg(PlannerInfo *root, List *tlist, List *qual, > - AggStrategy aggstrategy, const AggClauseCosts *aggcosts, > - int numGroupCols, AttrNumber *grpColIdx, Oid *grpOperators, > - List *groupingSets, long numGroups, bool combineStates, > - bool finalizeAggs, Plan *lefttree); > - extern WindowAgg *make_windowagg(PlannerInfo *root, List *tlist, > - List *windowFuncs, Index winref, > - int partNumCols, AttrNumber *partColIdx, Oid *partOperators, > - int ordNumCols, AttrNumber *ordColIdx, Oid *ordOperators, > - int frameOptions, Node *startOffset, Node *endOffset, > - Plan *lefttree); > - extern Group *make_group(PlannerInfo *root, List *tlist, List *qual, > - int numGroupCols, AttrNumber *grpColIdx, Oid *grpOperators, > - double numGroups, > - Plan *lefttree); > extern Plan *materialize_finished_plan(Plan *subplan); > ! extern Unique *make_unique(Plan *lefttree, List *distinctList); > ! extern LockRows *make_lockrows(Plan *lefttree, List *rowMarks, int epqParam); > ! extern Limit *make_limit(Plan *lefttree, Node *limitOffset, Node *limitCount, > ! int64 offset_est, int64 count_est); > ! extern SetOp *make_setop(SetOpCmd cmd, SetOpStrategy strategy, Plan *lefttree, > ! List *distinctList, AttrNumber flagColIdx, int firstFlag, > ! long numGroups, double outputRows); > ! extern Result *make_result(PlannerInfo *root, List *tlist, > ! Node *resconstantqual, Plan *subplan); > ! extern ModifyTable *make_modifytable(PlannerInfo *root, > ! CmdType operation, bool canSetTag, > ! Index nominalRelation, > ! List *resultRelations, List *subplans, > ! List *withCheckOptionLists, List *returningLists, > ! List *rowMarks, OnConflictExpr *onconflict, int epqParam); > extern bool is_projection_capable_plan(Plan *plan); I see that you made a lot of formerly externally visible make_* routines static. The Citus extension (which will be open source in a few days) uses several of these (make_agg, make_sort_from_sortclauses, make_limit at least). Can we please re-consider making these static? It's fine if their parameter list changes from release to release, that's easy enough to adjust to, and it's easily visible. But having to copy all of these into extension code is more than a bit painful; especially make_sort_from_sortclauses. Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes:
> I see that you made a lot of formerly externally visible make_* routines
> static. The Citus extension (which will be open source in a few days)
> uses several of these (make_agg, make_sort_from_sortclauses, make_limit
> at least).
> Can we please re-consider making these static?
That was intentional: in my opinion, nothing outside createplan.c ought
to be making Plan nodes anymore. The expectation is that you make a
Path describing what you want. Can you explain why, in the new planner
structure, it would be sane to have external callers of these functions?
regards, tom lane
On 2016-03-10 13:48:31 -0500, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > I see that you made a lot of formerly externally visible make_* routines > > static. The Citus extension (which will be open source in a few days) > > uses several of these (make_agg, make_sort_from_sortclauses, make_limit > > at least). > > > Can we please re-consider making these static? > > That was intentional: in my opinion, nothing outside createplan.c ought > to be making Plan nodes anymore. The expectation is that you make a > Path describing what you want. Can you explain why, in the new planner > structure, it would be sane to have external callers of these functions? In Citus' case a full PlannedStmt is generated on the master node, to combine the data generated on worker nodes (where the bog standard postgres planner is used). It's not the only way to do things, but I don't see why the approach would be entirely invalidated by the pathification work. We do provide the planner_hook, so restricting the toolbox for that to do something useful, doesn't seem like a necessarily good idea. - Andres
Andres Freund <andres@anarazel.de> writes:
> On 2016-03-10 13:48:31 -0500, Tom Lane wrote:
>> That was intentional: in my opinion, nothing outside createplan.c ought
>> to be making Plan nodes anymore. The expectation is that you make a
>> Path describing what you want. Can you explain why, in the new planner
>> structure, it would be sane to have external callers of these functions?
> In Citus' case a full PlannedStmt is generated on the master node, to
> combine the data generated on worker nodes (where the bog standard
> postgres planner is used). It's not the only way to do things, but I
> don't see why the approach would be entirely invalidated by the
> pathification work.
I don't deny that you *could* continue to do things that way, but
I dispute that it's a good idea. Why can't you generate a Path tree
and then ask create_plan() to convert it? Otherwise you're buying
into knowing a whole lot about the internals of createplan.c, and having
to track changes therein.
regards, tom lane
On 2016-03-10 14:16:03 -0500, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > In Citus' case a full PlannedStmt is generated on the master node, to > > combine the data generated on worker nodes (where the bog standard > > postgres planner is used). It's not the only way to do things, but I > > don't see why the approach would be entirely invalidated by the > > pathification work. > > I don't deny that you *could* continue to do things that way, but > I dispute that it's a good idea. Why can't you generate a Path tree > and then ask create_plan() to convert it? Primarily because create_plan(), and/or its children, have to know about what you're doing; you can hide some, but not all, things below CustomScan nodes. Secondarily, as an extension you will often have to support several major versions. ISTM, that there's good enough reasons to go either way; I don't see what we're gaining by making these private. That just encourages copy-paste coding. Andres
On Thu, Mar 10, 2016 at 2:41 PM, Andres Freund <andres@anarazel.de> wrote: > ISTM, that there's good enough reasons to go either way; I don't see > what we're gaining by making these private. That just encourages > copy-paste coding. +1. Frustrating Citus's attempt to open-source their stuff is not in the project's interest. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Mar 10, 2016 at 11:45 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Mar 10, 2016 at 2:41 PM, Andres Freund <andres@anarazel.de> wrote: >> ISTM, that there's good enough reasons to go either way; I don't see >> what we're gaining by making these private. That just encourages >> copy-paste coding. > > +1. Frustrating Citus's attempt to open-source their stuff is not in > the project's interest. I agree. -- Peter Geoghegan
Andres Freund <andres@anarazel.de> writes:
> On 2016-03-10 14:16:03 -0500, Tom Lane wrote:
>> I don't deny that you *could* continue to do things that way, but
>> I dispute that it's a good idea. Why can't you generate a Path tree
>> and then ask create_plan() to convert it?
> Primarily because create_plan(), and/or its children, have to know about
> what you're doing; you can hide some, but not all, things below
> CustomScan nodes.
And which of those things does e.g. setrefs.c not need to know about?
> ISTM, that there's good enough reasons to go either way; I don't see
> what we're gaining by making these private. That just encourages
> copy-paste coding.
What it encourages is having module boundaries that actually mean
something, as well as code that can be refactored without having
to worry about which extensions will complain about it.
I will yield on this point because it's not worth my time to argue about
it, but I continue to say that it's a bad decision you will regret.
Which functions did you need exactly? I'm not exporting more than
I have to.
regards, tom lane
On Thu, Mar 10, 2016 at 8:45 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Thu, Mar 10, 2016 at 2:41 PM, Andres Freund <andres@anarazel.de> wrote:
> ISTM, that there's good enough reasons to go either way; I don't see
> what we're gaining by making these private. That just encourages
> copy-paste coding.
+1. Frustrating Citus's attempt to open-source their stuff is not in
the project's interest.
Agreed. And it's not like we're very restrictive with this in a lot of other parts of the code. While we shouldn't go out of our way for forks/extensions, this seems like a very reasonable tradeoff.
Hi, On 2016-03-10 15:03:41 -0500, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > Primarily because create_plan(), and/or its children, have to know about > > what you're doing; you can hide some, but not all, things below > > CustomScan nodes. > > And which of those things does e.g. setrefs.c not need to know about? For CustomScans? You can mostly get by with ->custom_exprs. > > ISTM, that there's good enough reasons to go either way; I don't see > > what we're gaining by making these private. That just encourages > > copy-paste coding. > > What it encourages is having module boundaries that actually mean > something, as well as code that can be refactored without having > to worry about which extensions will complain about it. I personally think it's entirely fine to break extensions if it's adding or removing a few parameters or somesuch. That's easy enough fixed. > I will yield on this point because it's not worth my time to argue about > it, but I continue to say that it's a bad decision you will regret. FWIW, I do agree that it'd be much nicer to use the new API; the biggest user in Citus should be able to work with that. But it's not that easy to do that and still support postgres 9.4/9.5. > Which functions did you need exactly? I'm not exporting more than > I have to. I'll try to do the port tomorrow; to make sure I have the definitive list. Afaics it's just make_seqscan, make_sort_from_sortclauses, make_limit, make_agg. I'd not however be surprised if other extensions also use some of these. Would you rather add back the exports or should I? Greetings, Andres
Andres Freund <andres@anarazel.de> writes:
> On 2016-03-10 15:03:41 -0500, Tom Lane wrote:
>> What it encourages is having module boundaries that actually mean
>> something, as well as code that can be refactored without having
>> to worry about which extensions will complain about it.
> I personally think it's entirely fine to break extensions if it's adding
> or removing a few parameters or somesuch. That's easy enough fixed.
I don't want to promise that the *behavior* of those functions remains
stable. As an example, none of them any longer do any internal cost
calculations, which is a change that doesn't directly show in their
argument lists but will break extensions just as surely (and more
silently) as an argument-list change would do. And no, that change
is NOT going to get undone.
> Would you rather add back the exports or should I?
I'll do it ... just send me the list.
regards, tom lane
On 2016-03-10 23:38:14 -0500, Tom Lane wrote: > > Would you rather add back the exports or should I? > > I'll do it ... just send me the list. After exporting make_agg, make_limit, make_sort_from_sortclauses and making some trivial adjustments due to the pull_var_clause changes change, Citus' tests pass on 9.6, bar some noise. Pathification made some plans switch from hash-agg to sort-agg, and the other way round; but that's obviously ok. Thanks, Andres
Andres Freund <andres@anarazel.de> writes:
> On 2016-03-10 23:38:14 -0500, Tom Lane wrote:
>> I'll do it ... just send me the list.
> After exporting make_agg, make_limit, make_sort_from_sortclauses and
> making some trivial adjustments due to the pull_var_clause changes
> change, Citus' tests pass on 9.6, bar some noise.
OK, done.
> Pathification made
> some plans switch from hash-agg to sort-agg, and the other way round;
> but that's obviously ok.
I wonder whether that's pathification per se. Of the three core
regression test EXPLAINs that changed in the pathification commit,
two actually were a case of finding better plans. The other one
was a random-looking swap between two plans with near-identical
costs. When I looked into it, I found that the reason the planner
liked the new plan better was that it was parallel-safe; add_path()
saw the costs as fuzzily equal and allowed parallel-safe to be the
determining factor in the choice. The old code hadn't done that
because the hard-wired cost comparisons in grouping_planner() never
took parallel-safety into account. But I'd call that a parallelism
change, not a pathification change; it would certainly have appeared
to be that if the patches had gone in in the opposite order.
regards, tom lane
On 2016-03-12 12:22:01 -0500, Tom Lane wrote: > Andres Freund <andres@anarazel.de> writes: > > On 2016-03-10 23:38:14 -0500, Tom Lane wrote: > >> I'll do it ... just send me the list. > > > After exporting make_agg, make_limit, make_sort_from_sortclauses and > > making some trivial adjustments due to the pull_var_clause changes > > change, Citus' tests pass on 9.6, bar some noise. > > OK, done. Thanks. > > Pathification made > > some plans switch from hash-agg to sort-agg, and the other way round; > > but that's obviously ok. > > I wonder whether that's pathification per se. If you're interested enough, I've uploaded a dump of the schema relevant table to http://anarazel.de/t/lineitem_95_96_plan.dump.gz the affected query is (after ANALYZE lineitem_102009) EXPLAIN SELECT l_quantity, count(*) AS count, sum(l_extendedprice) AS avg, count(l_extendedprice) AS avg, array_agg(l_orderkey)AS array_agg FROM lineitem_102009 lineitem WHERE ((l_quantity < '5'::numeric) AND (l_orderkey > 5500) AND (l_orderkey < 9500)) GROUP BY l_quantity; =# SELECT version(); ┌──────────────────────────────────────────────────────────────────────────────────────────────────────────┐ │ version │ ├──────────────────────────────────────────────────────────────────────────────────────────────────────────┤ │ PostgreSQL 9.5.1 on x86_64-pc-linux-gnu, compiled by gcc-5.real (Debian 5.3.1-10) 5.3.1 20160224, 64-bit │ └──────────────────────────────────────────────────────────────────────────────────────────────────────────┘ (1 row) =# SELECT l_quantity, count(*) AS count, sum(l_extendedprice) AS avg, count(l_extendedprice) AS avg, array_agg(l_orderkey)AS array_agg FROM lineitem_102009 lineitem WHERE ((l_quantity < '5'::numeric) AND (l_orderkey > 5500)AND (l_orderkey < 9500)) GROUP BY l_quantity; ┌────────────┬───────┬──────────┬─────┬────────────────────────────────────────────────┐ │ l_quantity │ count │ avg │ avg │ array_agg │ ├────────────┼───────┼──────────┼─────┼────────────────────────────────────────────────┤ │ 1.00 │ 9 │ 13044.06 │ 9 │ {8997,9026,9158,9184,9220,9222,9348,9383,9476} │ │ 4.00 │ 7 │ 40868.84 │ 7 │ {9091,9120,9281,9347,9382,9440,9473} │ │ 2.00 │ 8 │ 26072.02 │ 8 │ {9030,9058,9123,9124,9188,9344,9441,9476} │ │ 3.00 │ 9 │ 39925.32 │ 9 │ {9124,9157,9184,9223,9254,9349,9414,9475,9477} │ └────────────┴───────┴──────────┴─────┴────────────────────────────────────────────────┘ (4 rows) Time: 0.906 ms =# EXPLAIN SELECT l_quantity, count(*) AS count, sum(l_extendedprice) AS avg, count(l_extendedprice) AS avg, array_agg(l_orderkey)AS array_agg FROM lineitem_102009 lineitem WHERE ((l_quantity < '5'::numeric) AND (l_orderkey > 5500)AND (l_orderkey < 9500)) GROUP BY l_quantity; ┌────────────────────────────────────────────────────────────────────────────────────────────┐ │ QUERY PLAN │ ├────────────────────────────────────────────────────────────────────────────────────────────┤ │ HashAggregate (cost=137.91..137.93 rows=1 width=21) │ │ Group Key: l_quantity │ │ -> Bitmap Heap Scan on lineitem_102009 lineitem (cost=13.07..137.44 rows=38 width=21) │ │ Recheck Cond: ((l_orderkey > 5500) AND (l_orderkey < 9500)) │ │ Filter: (l_quantity < '5'::numeric) │ │ -> Bitmap Index Scan on lineitem_pkey_102009 (cost=0.00..13.06 rows=478 width=0) │ │ Index Cond: ((l_orderkey > 5500) AND (l_orderkey < 9500)) │ └──────────────────────────────────────────────────────────────────────────────────────── vs. =# SELECT version(); ┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── │ version ├─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── │ PostgreSQL 9.6devel on x86_64-pc-linux-gnu, compiled by gcc-6.real (Debian 6-20160228-1) 6.0.0 20160228 (experimental)[trunk revision └─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── (1 row) =# SELECT l_quantity, count(*) AS count, sum(l_extendedprice) AS avg, count(l_extendedprice) AS avg, array_agg(l_orderkey)AS array_agg FROM lineitem_102009 lineitem WHERE ((l_quantity < '5'::numeric) AND (l_orderkey > 5500)AND (l_orderkey < 9500)) GROUP BY l_quantity; ┌────────────┬───────┬──────────┬─────┬────────────────────────────────────────────────┐ │ l_quantity │ count │ avg │ avg │ array_agg │ ├────────────┼───────┼──────────┼─────┼────────────────────────────────────────────────┤ │ 1.00 │ 9 │ 13044.06 │ 9 │ {9476,9158,9184,9383,9026,9220,9222,8997,9348} │ │ 2.00 │ 8 │ 26072.02 │ 8 │ {9124,9344,9441,9123,9476,9030,9058,9188} │ │ 3.00 │ 9 │ 39925.32 │ 9 │ {9477,9124,9157,9184,9223,9254,9349,9414,9475} │ │ 4.00 │ 7 │ 40868.84 │ 7 │ {9440,9347,9473,9091,9281,9382,9120} │ └────────────┴───────┴──────────┴─────┴────────────────────────────────────────────────┘ (4 rows) =# EXPLAIN SELECT l_quantity, count(*) AS count, sum(l_extendedprice) AS avg, count(l_extendedprice) AS avg, array_agg(l_orderkey)AS array_agg FROM lineitem_102009 lineitem WHERE ((l_quantity < '5'::numeric) AND (l_orderkey > 5500)AND (l_orderkey < 9500)) GROUP BY l_quantity; ┌──────────────────────────────────────────────────────────────────────────────────────────────────┐ │ QUERY PLAN │ ├──────────────────────────────────────────────────────────────────────────────────────────────────┤ │ GroupAggregate (cost=138.43..139.02 rows=1 width=85) │ │ Group Key: l_quantity │ │ -> Sort (cost=138.43..138.53 rows=38 width=21) │ │ Sort Key: l_quantity │ │ -> Bitmap Heap Scan on lineitem_102009 lineitem (cost=13.07..137.44 rows=38 width=21) │ │ Recheck Cond: ((l_orderkey > 5500) AND (l_orderkey < 9500)) │ │ Filter: (l_quantity < '5'::numeric) │ │ -> Bitmap Index Scan on lineitem_pkey_102009 (cost=0.00..13.06 rows=478 width=0) │ │ Index Cond: ((l_orderkey > 5500) AND (l_orderkey < 9500)) │ └──────────────────────────────────────────────────────────────────────────────────────────────────┘ (9 rows) As you probably can guess, what made me notice this wsa the difference in the array_agg output. > Of the three core regression test EXPLAINs that changed in the > pathification commit, two actually were a case of finding better > plans. The other one was a random-looking swap between two plans with > near-identical costs. When I looked into it, I found that the reason > the planner liked the new plan better was that it was parallel-safe; > add_path() saw the costs as fuzzily equal and allowed parallel-safe to > be the determining factor in the choice. The old code hadn't done > that because the hard-wired cost comparisons in grouping_planner() > never took parallel-safety into account. But I'd call that a > parallelism change, not a pathification change; it would certainly > have appeared to be that if the patches had gone in in the opposite > order. I've not yet looked deep enough to determine the root cause; I did however notice that set enable_sort = false; yields a cheaper plan than the default one, within the fuzz range (137.91..137.93 vs 138.43..139.02). Greetings, Andres Freund
Andres Freund <andres@anarazel.de> writes: > On 2016-03-12 12:22:01 -0500, Tom Lane wrote: >> I wonder whether that's pathification per se. > If you're interested enough, I've uploaded a dump of the schema relevant > table to http://anarazel.de/t/lineitem_95_96_plan.dump.gz I haven't dug into it, but I'll bet this is a case of add_path deciding that the GroupAgg plan is fuzzily the same cost and better sorted (ie, it produces *some* sort order, versus none for the hash), so it kicks the hash plan out. Again, that would not have happened with the old hard-wired cost comparisons in grouping_planner, because they considered no factors other than an exact cost comparison. > I've not yet looked deep enough to determine the root cause; I did > however notice that set enable_sort = false; yields a cheaper plan than > the default one, within the fuzz range (137.91..137.93 vs 138.43..139.02). Yeah, you're just forcing it to choose the hash plan again. But that's within the cost fuzz range, so it's a legitimate choice. regards, tom lane
Hello, I'm now checking the new planner implementation to find out the way to integrate CustomPath to the upper planner also. CustomPath node is originally expected to generate various kind of plan node, not only scan/join, and its interface is designed to support them. For example, we can expect a CustomPath that generates "CustomSort". On the other hands, upper path consideration is more variable than the case of scan/join path consideration. Probably, we can have no centralized point to add custom-paths for sort, group-by, ... So, I think we have hooks for each (supported) upper path workload. In case of sorting for example, the best location of the hook is just above of the Assert() in the create_ordered_paths(). It allows to compare estimated cost between SortPath and CustomPath. However, it does not allow to inject CustomPath(for sort) into the path node that may involve sorting, like WindowPath or AggPath. Thus, another hook may be put on create_window_paths and create_grouping_paths in my thought. Some other good idea? Even though I couldn't check the new planner implementation entirely, it seems to be the points below are good candidate to inject CustomPath (and potentially ForeignScan). - create_grouping_paths - create_window_paths - create_distinct_paths - create_ordered_paths - just below of the create_modifytable_path (may be valuable for foreign-update pushdown) Thanks, -- NEC Business Creation Division / PG-Strom Project KaiGai Kohei <kaigai@ak.jp.nec.com> > -----Original Message----- > From: pgsql-hackers-owner@postgresql.org > [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Tom Lane > Sent: Saturday, March 05, 2016 3:02 AM > To: David Rowley > Cc: Robert Haas; pgsql-hackers@postgresql.org > Subject: Re: [HACKERS] WIP: Upper planner pathification > > OK, here is a version that I think addresses all of the recent comments: > > * I refactored the grouping-sets stuff as suggested by Robert and David. > The GroupingSetsPath code is now used *only* when there are grouping sets, > otherwise what you get is a plain AGG_SORTED AggPath. This allowed > removal of a boatload of weird corner cases in the GroupingSets code path, > so it was a good change. (Fundamentally, that's cleaning up some > questionable coding in the grouping sets patch rather than fixing anything > directly related to pathification, but I like the code better now.) > > * I refactored the handling of targetlists in createplan.c. After some > reflection I decided that the disuse_physical_tlist callers fell into > three separate categories: those that actually needed the exact requested > tlist to be returned, those that wanted non-bloated tuples because they > were going to put them into sort or hash storage, and those that needed > grouping columns to be properly labeled. The new approach is to pass down > a "flags" word that specifies which if any of these cases apply at a > specific plan level. use_physical_tlist now always makes the right > decision to start with, and disuse_physical_tlist is gone entirely, which > should make things a bit faster since we won't uselessly construct and > discard physical tlists. The missing logic from make_subplanTargetList > and locate_grouping_columns is reincarnated in the physical-tlist code. > > * Added explicit limit/offset fields to LimitPath, as requested by Teodor. > > * Removed SortPath.sortgroupclauses. > > * Fixed handling of parallel-query fields in new path node types. > (BTW, I found what seemed to be a couple of pre-existing bugs of > the same kind, eg create_mergejoin_path was different from the > other two kinds of join as to setting parallel_degree.) > > > What remains to be done, IMV: > > * Performance testing as per yesterday's discussion. > > * Debug support in outfuncs.c and print_path() for new node types. > > * Clean up unfinished work on function header comments. > > * Write some documentation about how FDWs might use this. > > I'll work on the performance testing next. Barring unsatisfactory > results from that, I think this could be committable in a couple > of days. > > regards, tom lane
On 14/03/16 02:43, Kouhei Kaigai wrote: > > CustomPath node is originally expected to generate various kind of plan > node, not only scan/join, and its interface is designed to support them. > For example, we can expect a CustomPath that generates "CustomSort". > > On the other hands, upper path consideration is more variable than the > case of scan/join path consideration. Probably, we can have no centralized > point to add custom-paths for sort, group-by, ... > So, I think we have hooks for each (supported) upper path workload. > > In case of sorting for example, the best location of the hook is just > above of the Assert() in the create_ordered_paths(). It allows to compare > estimated cost between SortPath and CustomPath. > However, it does not allow to inject CustomPath(for sort) into the path > node that may involve sorting, like WindowPath or AggPath. > Thus, another hook may be put on create_window_paths and > create_grouping_paths in my thought. > > Some other good idea? > > Even though I couldn't check the new planner implementation entirely, > it seems to be the points below are good candidate to inject CustomPath > (and potentially ForeignScan). > > - create_grouping_paths > - create_window_paths > - create_distinct_paths > - create_ordered_paths > - just below of the create_modifytable_path > (may be valuable for foreign-update pushdown) > To me that seems too low inside the planning tree, perhaps adding it just to the subquery_planner before SS_identify_outer_params would be better, that's the place where you see the path for the whole (sub)query so you can search and modify what you need from there. -- Petr Jelinek http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
> -----Original Message----- > From: Petr Jelinek [mailto:petr@2ndquadrant.com] > Sent: Monday, March 14, 2016 12:18 PM > To: Kaigai Kouhei(海外 浩平); Tom Lane; David Rowley > Cc: Robert Haas; pgsql-hackers@postgresql.org > Subject: Re: [HACKERS] WIP: Upper planner pathification > > On 14/03/16 02:43, Kouhei Kaigai wrote: > > > > CustomPath node is originally expected to generate various kind of plan > > node, not only scan/join, and its interface is designed to support them. > > For example, we can expect a CustomPath that generates "CustomSort". > > > > On the other hands, upper path consideration is more variable than the > > case of scan/join path consideration. Probably, we can have no centralized > > point to add custom-paths for sort, group-by, ... > > So, I think we have hooks for each (supported) upper path workload. > > > > In case of sorting for example, the best location of the hook is just > > above of the Assert() in the create_ordered_paths(). It allows to compare > > estimated cost between SortPath and CustomPath. > > However, it does not allow to inject CustomPath(for sort) into the path > > node that may involve sorting, like WindowPath or AggPath. > > Thus, another hook may be put on create_window_paths and > > create_grouping_paths in my thought. > > > > Some other good idea? > > > > Even though I couldn't check the new planner implementation entirely, > > it seems to be the points below are good candidate to inject CustomPath > > (and potentially ForeignScan). > > > > - create_grouping_paths > > - create_window_paths > > - create_distinct_paths > > - create_ordered_paths > > - just below of the create_modifytable_path > > (may be valuable for foreign-update pushdown) > > > > To me that seems too low inside the planning tree, perhaps adding it > just to the subquery_planner before SS_identify_outer_params would be > better, that's the place where you see the path for the whole (sub)query > so you can search and modify what you need from there. > Thanks for your idea. Yes, I also thought a similar point; where all the path consideration get completed. It indeed allows extensions to walk down the path tree and replace a part of them. However, when we want to inject CustomPath under the built-in paths, extension has to re-calculate cost of the built-in paths again. Perhaps, it affects to the decision of built-in path selection. So, I concluded that it is not realistic to re-implement equivalent upper planning stuff in the extension side, if we put the hook after all the planning works done. If extension can add its CustomPath at create_grouping_paths(), the later steps, like create_window_paths, stands on the estimated cost of the CustomPath. Thus, extension don't need to know the detail of the entire upper planning. Thanks, -- NEC Business Creation Division / PG-Strom Project KaiGai Kohei <kaigai@ak.jp.nec.com>
Petr Jelinek <petr@2ndquadrant.com> writes:
> On 14/03/16 02:43, Kouhei Kaigai wrote:
>> Even though I couldn't check the new planner implementation entirely,
>> it seems to be the points below are good candidate to inject CustomPath
>> (and potentially ForeignScan).
>>
>> - create_grouping_paths
>> - create_window_paths
>> - create_distinct_paths
>> - create_ordered_paths
>> - just below of the create_modifytable_path
>> (may be valuable for foreign-update pushdown)
> To me that seems too low inside the planning tree, perhaps adding it
> just to the subquery_planner before SS_identify_outer_params would be
> better, that's the place where you see the path for the whole (sub)query
> so you can search and modify what you need from there.
I don't like either of those too much. The main thing I've noticed over
the past few days is that you can't readily generate custom upper-level
Paths unless you know what PathTarget grouping_planner is expecting each
level to produce. So what I was toying with doing is (1) having
grouping_planner put all those targets into the PlannerInfo, perhaps
in an array indexed by UpperRelationKind; and (2) adding a hook call
immediately after those targets are computed, say right before
the create_grouping_paths() call (approximately planner.c:1738
in HEAD). It should be sufficient to have one hook there since
you can inject Paths into any of the upper relations at that point;
moreover, that's late enough that you shouldn't have to recompute
anything you figured out during scan/join planning.
Now, a simple hook function is probably about the best we can offer
CustomScan providers, since we don't really know what they're going
to do. But I'm pretty unenthused about telling FDW authors to use
such a hook, because generally speaking they're simply going to waste
cycles finding out that they aren't involved in a given query.
It would be better if we invent an FDW callback that's meant to be
invoked at this stage, but only call it for FDW(s) actively involved
in the query. I'm not sure exactly what that ought to look like though.
Maybe only call the FDW identified as possible owner of the topmost
scan/join relation?
regards, tom lane
On Mon, Mar 14, 2016 at 1:04 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Petr Jelinek <petr@2ndquadrant.com> writes: >> On 14/03/16 02:43, Kouhei Kaigai wrote: >>> Even though I couldn't check the new planner implementation entirely, >>> it seems to be the points below are good candidate to inject CustomPath >>> (and potentially ForeignScan). >>> >>> - create_grouping_paths >>> - create_window_paths >>> - create_distinct_paths >>> - create_ordered_paths >>> - just below of the create_modifytable_path >>> (may be valuable for foreign-update pushdown) > >> To me that seems too low inside the planning tree, perhaps adding it >> just to the subquery_planner before SS_identify_outer_params would be >> better, that's the place where you see the path for the whole (sub)query >> so you can search and modify what you need from there. > > I don't like either of those too much. The main thing I've noticed over > the past few days is that you can't readily generate custom upper-level > Paths unless you know what PathTarget grouping_planner is expecting each > level to produce. So what I was toying with doing is (1) having > grouping_planner put all those targets into the PlannerInfo, perhaps > in an array indexed by UpperRelationKind; and (2) adding a hook call > immediately after those targets are computed, say right before > the create_grouping_paths() call (approximately planner.c:1738 > in HEAD). It should be sufficient to have one hook there since > you can inject Paths into any of the upper relations at that point; > moreover, that's late enough that you shouldn't have to recompute > anything you figured out during scan/join planning. That is a nice set of characteristics for a hook. > Now, a simple hook function is probably about the best we can offer > CustomScan providers, since we don't really know what they're going > to do. But I'm pretty unenthused about telling FDW authors to use > such a hook, because generally speaking they're simply going to waste > cycles finding out that they aren't involved in a given query. > It would be better if we invent an FDW callback that's meant to be > invoked at this stage, but only call it for FDW(s) actively involved > in the query. I'm not sure exactly what that ought to look like though. > Maybe only call the FDW identified as possible owner of the topmost > scan/join relation? I think in the short term that's as well as we're going to do, so +1. In the long run, I'm interested in making FDWs be able to optimize queries like foreigntab JOIN localtab ON foreigntab.x = localtab.x (e.g. by copying localtab to the remote side when it's small); but that will require revisiting some old decisions, too. What you're proposing here sounds consistent with what we've done so far. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Mon, Mar 14, 2016 at 1:04 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> It would be better if we invent an FDW callback that's meant to be
>> invoked at this stage, but only call it for FDW(s) actively involved
>> in the query. I'm not sure exactly what that ought to look like though.
>> Maybe only call the FDW identified as possible owner of the topmost
>> scan/join relation?
> I think in the short term that's as well as we're going to do, so +1.
> In the long run, I'm interested in making FDWs be able to optimize
> queries like foreigntab JOIN localtab ON foreigntab.x = localtab.x
> (e.g. by copying localtab to the remote side when it's small); but
> that will require revisiting some old decisions, too.
Yeah. An alternative definition that would support that would be to
call the upper-path-providing callback for each FDW that's responsible
for any base relation of the query. But I think that that would often
lead to a lot of redundant/wasted computation, and it's not clear to
me that we can support such cases without other changes as well.
regards, tom lane
On Mon, Mar 14, 2016 at 1:37 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> On Mon, Mar 14, 2016 at 1:04 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> It would be better if we invent an FDW callback that's meant to be >>> invoked at this stage, but only call it for FDW(s) actively involved >>> in the query. I'm not sure exactly what that ought to look like though. >>> Maybe only call the FDW identified as possible owner of the topmost >>> scan/join relation? > >> I think in the short term that's as well as we're going to do, so +1. >> In the long run, I'm interested in making FDWs be able to optimize >> queries like foreigntab JOIN localtab ON foreigntab.x = localtab.x >> (e.g. by copying localtab to the remote side when it's small); but >> that will require revisiting some old decisions, too. > > Yeah. An alternative definition that would support that would be to > call the upper-path-providing callback for each FDW that's responsible > for any base relation of the query. But I think that that would often > lead to a lot of redundant/wasted computation, and it's not clear to > me that we can support such cases without other changes as well. Sure, that's fine with me. Are you going to go make these changes now? Eventually, we might just support a configurable flag on FDWs where FDWs that want to do this sort of thing can request callbacks on every join and every upper rel in the query. But that can wait. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Mon, Mar 14, 2016 at 1:37 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Yeah. An alternative definition that would support that would be to
>> call the upper-path-providing callback for each FDW that's responsible
>> for any base relation of the query. But I think that that would often
>> lead to a lot of redundant/wasted computation, and it's not clear to
>> me that we can support such cases without other changes as well.
> Sure, that's fine with me. Are you going to go make these changes now?
Yeah, in a bit.
> Eventually, we might just support a configurable flag on FDWs where
> FDWs that want to do this sort of thing can request callbacks on every
> join and every upper rel in the query. But that can wait.
That'd be a possibility, too.
regards, tom lane
Robert Haas <robertmhaas@gmail.com> writes:
> On Mon, Mar 14, 2016 at 1:37 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Yeah. An alternative definition that would support that would be to
>> call the upper-path-providing callback for each FDW that's responsible
>> for any base relation of the query. But I think that that would often
>> lead to a lot of redundant/wasted computation, and it's not clear to
>> me that we can support such cases without other changes as well.
> Sure, that's fine with me. Are you going to go make these changes now?
So I started looking at this, and almost immediately came to two
conclusions:
1. We need to add a "PathTarget *" parameter to create_foreignscan_path.
The hard-wired assignment that's in there now,
pathnode->path.pathtarget = &(rel->reltarget);
is sufficient for scan and join paths, but it doesn't work at all for
upper relations because we don't put anything in their reltarget fields.
We could do so, but it's still problematic because there will be
situations where non-topmost Paths associated with an upperrel have other
targets than what topmost Paths do. This is true today for set-operation
Paths and WindowAgg Paths, and I think possibly other cases as well (such
as inserted projection nodes). We could possibly insist on creating a
separate upperrel for every distinct target that's used by intermediate
levels of Path in these trees, but that seems kinda pointless to me, at
least for now. Really the best answer is to let FDWs have control of it.
And it's not like we've never whacked this function's API around before.
2. I was being way too cycle-miserly when I decided to make
RelOptInfo.reltarget be an embedded struct rather than defining PathTarget
as a regular, separate node type. I'm gonna change that before it's too
late. One extra palloc per RelOptInfo is not a noticeable price, and
there are too many places where this choice is resulting in notational
weirdness.
regards, tom lane
> -----Original Message-----
> From: Tom Lane [mailto:tgl@sss.pgh.pa.us]
> Sent: Tuesday, March 15, 2016 2:04 AM
> To: Petr Jelinek
> Cc: Kaigai Kouhei(海外 浩平); David Rowley; Robert Haas;
> pgsql-hackers@postgresql.org
> Subject: Re: [HACKERS] WIP: Upper planner pathification
>
> Petr Jelinek <petr@2ndquadrant.com> writes:
> > On 14/03/16 02:43, Kouhei Kaigai wrote:
> >> Even though I couldn't check the new planner implementation entirely,
> >> it seems to be the points below are good candidate to inject CustomPath
> >> (and potentially ForeignScan).
> >>
> >> - create_grouping_paths
> >> - create_window_paths
> >> - create_distinct_paths
> >> - create_ordered_paths
> >> - just below of the create_modifytable_path
> >> (may be valuable for foreign-update pushdown)
>
> > To me that seems too low inside the planning tree, perhaps adding it
> > just to the subquery_planner before SS_identify_outer_params would be
> > better, that's the place where you see the path for the whole (sub)query
> > so you can search and modify what you need from there.
>
> I don't like either of those too much. The main thing I've noticed over
> the past few days is that you can't readily generate custom upper-level
> Paths unless you know what PathTarget grouping_planner is expecting each
> level to produce. So what I was toying with doing is (1) having
> grouping_planner put all those targets into the PlannerInfo, perhaps
> in an array indexed by UpperRelationKind; and (2) adding a hook call
> immediately after those targets are computed, say right before
> the create_grouping_paths() call (approximately planner.c:1738
> in HEAD). It should be sufficient to have one hook there since
> you can inject Paths into any of the upper relations at that point;
> moreover, that's late enough that you shouldn't have to recompute
> anything you figured out during scan/join planning.
>
Regarding to the (2), I doubt whether the location is reasonable,
because pathlist of each upper_rels[] are still empty, aren't it?
It will make extension not-easy to construct its own CustomPath that
takes underlying built-in pathnodes.
For example, an extension implements its own sort logic but not
interested in group-by/window function, it shall want to add its
CustomPath to UPPERREL_ORDERED, however, it does not know which is
the input_rel and no built-in paths are not added yet at the point
of create_upper_paths_hook().
On the other hands, here is another problem if we put a hook after
all the upper paths done. In this case, built-in create_xxxx_paths()
functions cannot pay attention for CustomPath to be added later when
these functions pick up the cheapest path.
So, even though we don't need to define multiple hook declarations,
I think the hook invocation is needed just after create_xxxx_paths()
for each. It will need to inform extension the context of hook
invocation, the argument list will take UpperRelationKind.
In addition, extension cannot reference some local variables from
the root structure, like:- rollup_lists- rollup_groupclauses- wflists- activeWindows- have_postponed_srfs
As we are doing at set_join_pathlist_hook, it is good idea to define
UpperPathExtraData structure to pack misc information.
So, how about to re-define the hook as follows?
typedef void (*create_upper_paths_hook_type) (UpperRelationKind upper_kind,
PlannerInfo*root, RelOptInfo *scan_join_rel,
UpperPathExtraData *extra);
Thanks,
--
NEC Business Creation Division / PG-Strom Project
KaiGai Kohei <kaigai@ak.jp.nec.com>
On Mon, Mar 14, 2016 at 9:21 PM, Kouhei Kaigai <kaigai@ak.jp.nec.com> wrote: > So, even though we don't need to define multiple hook declarations, > I think the hook invocation is needed just after create_xxxx_paths() > for each. It will need to inform extension the context of hook > invocation, the argument list will take UpperRelationKind. That actually seems like a pretty good point. Otherwise you can't push anything from the upper rels down unless you are prepared to handle all of it. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Mon, Mar 14, 2016 at 9:21 PM, Kouhei Kaigai <kaigai@ak.jp.nec.com> wrote:
>> So, even though we don't need to define multiple hook declarations,
>> I think the hook invocation is needed just after create_xxxx_paths()
>> for each. It will need to inform extension the context of hook
>> invocation, the argument list will take UpperRelationKind.
> That actually seems like a pretty good point. Otherwise you can't
> push anything from the upper rels down unless you are prepared to
> handle all of it.
I'm not exactly convinced of the use-case for that. What external
thing is likely to handle window functions but not aggregation,
for example?
regards, tom lane
> Robert Haas <robertmhaas@gmail.com> writes:
> > On Mon, Mar 14, 2016 at 9:21 PM, Kouhei Kaigai <kaigai@ak.jp.nec.com> wrote:
> >> So, even though we don't need to define multiple hook declarations,
> >> I think the hook invocation is needed just after create_xxxx_paths()
> >> for each. It will need to inform extension the context of hook
> >> invocation, the argument list will take UpperRelationKind.
>
> > That actually seems like a pretty good point. Otherwise you can't
> > push anything from the upper rels down unless you are prepared to
> > handle all of it.
>
> I'm not exactly convinced of the use-case for that. What external
> thing is likely to handle window functions but not aggregation,
> for example?
>
WindowPath usually takes a SortPath. Even though extension don't want to
handle window function itself, it may want to add alternative sort logic
than built-in.
Unless it does not calculate expected cost, nobody knows whether WindowPath +
SortPath is really cheaper than WindowPath + CustomPath("GpuSort").
The supplied query may require to run group-by prior to window function,
but extension may not be interested in group-by on the other hands, thus,
extension needs to get control around the location where built-in logic
also adds paths to fetch the cheapest path of the underlying paths.
Thanks,
--
NEC Business Creation Division / PG-Strom Project
KaiGai Kohei <kaigai@ak.jp.nec.com>
> > Robert Haas <robertmhaas@gmail.com> writes:
> > > On Mon, Mar 14, 2016 at 9:21 PM, Kouhei Kaigai <kaigai@ak.jp.nec.com> wrote:
> > >> So, even though we don't need to define multiple hook declarations,
> > >> I think the hook invocation is needed just after create_xxxx_paths()
> > >> for each. It will need to inform extension the context of hook
> > >> invocation, the argument list will take UpperRelationKind.
> >
> > > That actually seems like a pretty good point. Otherwise you can't
> > > push anything from the upper rels down unless you are prepared to
> > > handle all of it.
> >
> > I'm not exactly convinced of the use-case for that. What external
> > thing is likely to handle window functions but not aggregation,
> > for example?
> >
> WindowPath usually takes a SortPath. Even though extension don't want to
> handle window function itself, it may want to add alternative sort logic
> than built-in.
> Unless it does not calculate expected cost, nobody knows whether WindowPath +
> SortPath is really cheaper than WindowPath + CustomPath("GpuSort").
>
> The supplied query may require to run group-by prior to window function,
> but extension may not be interested in group-by on the other hands, thus,
> extension needs to get control around the location where built-in logic
> also adds paths to fetch the cheapest path of the underlying paths.
>
If I would design the hook, I will put its entrypoint at:
- tail of create_grouping_paths(), just before set_cheapest()
- tail of create_window_paths(), just before set_cheapest()
- tail of create_distinct_paths(), just before set_cheapest()
- tail of create_ordered_paths(), just before set_cheapest()
- tail of grouping_planner(), after the loop of create_modifytable_path()
I'm not 100% certain whether the last one is the straightforward idea
to provide alternative writing stuff. For example, if an extension has
own special storage like columnar format, we may need more consideration
whether CustomPath and related stuff are suitable tool.
On the other hands, I believe the earlier 4 entrypoints are right location.
Thanks,
--
NEC Business Creation Division / PG-Strom Project
KaiGai Kohei <kaigai@ak.jp.nec.com>
Вложения
On Wed, Mar 16, 2016 at 2:47 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> On Mon, Mar 14, 2016 at 9:21 PM, Kouhei Kaigai <kaigai@ak.jp.nec.com> wrote: >>> So, even though we don't need to define multiple hook declarations, >>> I think the hook invocation is needed just after create_xxxx_paths() >>> for each. It will need to inform extension the context of hook >>> invocation, the argument list will take UpperRelationKind. > >> That actually seems like a pretty good point. Otherwise you can't >> push anything from the upper rels down unless you are prepared to >> handle all of it. > > I'm not exactly convinced of the use-case for that. What external > thing is likely to handle window functions but not aggregation, > for example? I'm not going to say that you're entirely wrong, but I think that attitude is a bit short-sighted. If somebody comes up with a new, awesome strategy for evaluating window functions, they're not going to be able to make it work in all cases without cut-and-pasting the logic for generating grouping paths. Now maybe nobody will ever come up with such a strategy, but if they do, this will get in the way. Also, KaiGai offered a different example of how this might get in the way. I'm not prepared to do battle over this right now, but I think that there are an awful lot of cases where extension authors haven't been able to quite do what they want to do without core changes because they couldn't get control in quite the right place; or they could do it but they had to cut-and-paste a lot of code. I don't think it requires all that much imagination to see how that could also happen here. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Wed, Mar 16, 2016 at 2:47 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Robert Haas <robertmhaas@gmail.com> writes:
>>> On Mon, Mar 14, 2016 at 9:21 PM, Kouhei Kaigai <kaigai@ak.jp.nec.com> wrote:
>>>> So, even though we don't need to define multiple hook declarations,
>>>> I think the hook invocation is needed just after create_xxxx_paths()
>>>> for each. It will need to inform extension the context of hook
>>>> invocation, the argument list will take UpperRelationKind.
>>> That actually seems like a pretty good point. Otherwise you can't
>>> push anything from the upper rels down unless you are prepared to
>>> handle all of it.
>> I'm not exactly convinced of the use-case for that. What external
>> thing is likely to handle window functions but not aggregation,
>> for example?
> I'm not going to say that you're entirely wrong, but I think that
> attitude is a bit short-sighted.
Well, I'm prepared to yield to the extent of repeating the hook call
before each phase with an UpperRelationKind parameter to tell which phase
we're about to do. The main concern here is to avoid redundant
computation, but the hook can check the "kind" parameter and fall out
quickly if it has nothing useful to do at the current phase.
I do not, however, like the proposal to expose wflists and so forth.
Those are internal data structures in grouping_planner and I absolutely
refuse to promise that they're going to stay stable. (I had already
been thinking a couple of weeks ago about revising the activeWindows
data structure, now that it would be reasonably practical to cost out
different orders for doing the window functions in.) I think a hook
that has its own ideas about window function implementation methods
can gather its own information about the WFs without that much extra
cost, and it very probably wouldn't want exactly the same data that
create_window_paths uses today anyway.
So what I would now propose is
typedef void (*create_upper_paths_hook_type) (PlannerInfo *root,
UpperRelationKindstage, RelOptInfo *input_rel);
and have this invoked at each stage right before we call
create_grouping_paths, create_window_paths, etc.
Also, I don't particularly see a need for a corresponding API for FDWs.
If an FDW is going to do anything in this space, it presumably has to
build up ForeignPaths for all the steps anyway. So I'd be inclined
to leave GetForeignUpperPaths as-is.
Comments?
regards, tom lane
On Thu, Mar 17, 2016 at 2:31 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Well, I'm prepared to yield to the extent of repeating the hook call > before each phase with an UpperRelationKind parameter to tell which phase > we're about to do. The main concern here is to avoid redundant > computation, but the hook can check the "kind" parameter and fall out > quickly if it has nothing useful to do at the current phase. > > I do not, however, like the proposal to expose wflists and so forth. > Those are internal data structures in grouping_planner and I absolutely > refuse to promise that they're going to stay stable. (I had already > been thinking a couple of weeks ago about revising the activeWindows > data structure, now that it would be reasonably practical to cost out > different orders for doing the window functions in.) I think a hook > that has its own ideas about window function implementation methods > can gather its own information about the WFs without that much extra > cost, and it very probably wouldn't want exactly the same data that > create_window_paths uses today anyway. > > So what I would now propose is > > typedef void (*create_upper_paths_hook_type) (PlannerInfo *root, > UpperRelationKind stage, > RelOptInfo *input_rel); > > and have this invoked at each stage right before we call > create_grouping_paths, create_window_paths, etc. Works for me. > Also, I don't particularly see a need for a corresponding API for FDWs. > If an FDW is going to do anything in this space, it presumably has to > build up ForeignPaths for all the steps anyway. So I'd be inclined > to leave GetForeignUpperPaths as-is. No idea if that is going to be a significant limitation or not. Doesn't seem like it should be, but what do I know? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Thu, Mar 17, 2016 at 2:31 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Also, I don't particularly see a need for a corresponding API for FDWs.
>> If an FDW is going to do anything in this space, it presumably has to
>> build up ForeignPaths for all the steps anyway. So I'd be inclined
>> to leave GetForeignUpperPaths as-is.
> No idea if that is going to be a significant limitation or not.
> Doesn't seem like it should be, but what do I know?
Well, to my mind the GetForeignUpperPaths API is meant to handle the
common case efficiently. An FDW that's not happy with that can always
get into the create_upper_paths_hook instead.
regards, tom lane
On Thu, Mar 17, 2016 at 4:22 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> On Thu, Mar 17, 2016 at 2:31 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> Also, I don't particularly see a need for a corresponding API for FDWs. >>> If an FDW is going to do anything in this space, it presumably has to >>> build up ForeignPaths for all the steps anyway. So I'd be inclined >>> to leave GetForeignUpperPaths as-is. > >> No idea if that is going to be a significant limitation or not. >> Doesn't seem like it should be, but what do I know? > > Well, to my mind the GetForeignUpperPaths API is meant to handle the > common case efficiently. An FDW that's not happy with that can always > get into the create_upper_paths_hook instead. OK - sold. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
> Robert Haas <robertmhaas@gmail.com> writes: > > On Wed, Mar 16, 2016 at 2:47 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > >> Robert Haas <robertmhaas@gmail.com> writes: > >>> On Mon, Mar 14, 2016 at 9:21 PM, Kouhei Kaigai <kaigai@ak.jp.nec.com> wrote: > >>>> So, even though we don't need to define multiple hook declarations, > >>>> I think the hook invocation is needed just after create_xxxx_paths() > >>>> for each. It will need to inform extension the context of hook > >>>> invocation, the argument list will take UpperRelationKind. > > >>> That actually seems like a pretty good point. Otherwise you can't > >>> push anything from the upper rels down unless you are prepared to > >>> handle all of it. > > >> I'm not exactly convinced of the use-case for that. What external > >> thing is likely to handle window functions but not aggregation, > >> for example? > > > I'm not going to say that you're entirely wrong, but I think that > > attitude is a bit short-sighted. > > Well, I'm prepared to yield to the extent of repeating the hook call > before each phase with an UpperRelationKind parameter to tell which phase > we're about to do. The main concern here is to avoid redundant > computation, but the hook can check the "kind" parameter and fall out > quickly if it has nothing useful to do at the current phase. > > I do not, however, like the proposal to expose wflists and so forth. > Those are internal data structures in grouping_planner and I absolutely > refuse to promise that they're going to stay stable. (I had already > been thinking a couple of weeks ago about revising the activeWindows > data structure, now that it would be reasonably practical to cost out > different orders for doing the window functions in.) I think a hook > that has its own ideas about window function implementation methods > can gather its own information about the WFs without that much extra > cost, and it very probably wouldn't want exactly the same data that > create_window_paths uses today anyway. > > So what I would now propose is > > typedef void (*create_upper_paths_hook_type) (PlannerInfo *root, > UpperRelationKind stage, > RelOptInfo *input_rel); > Hmm... It's not easy to imagine a case that extension wants own idea to extract window functions from the target list and select active windows, even if extension wants to have own executor and own cost estimation logic. In case when extension tries to add WindowPath + CustomPath(Sort), extension is interested in alternative sort task, but not window function itself. It is natural to follow the built-in implementation, thus, it motivates extension author to take copy & paste the code. select_active_windows() is static, so extension needs to have same routine on their side. On the other hands, 'rollup_lists' and 'rollup_groupclauses' need three static functions (extract_rollup_sets(), reorder_grouping_sets() and preprocess_groupclause() to reproduce the equivalent data structure. It is larger copy & paste burden, if extension is not interested in extracting the information related to grouping set. I understand it is not "best", but better to provide extra information needed for extension to reproduce equivalent pathnode, even if fields of UpperPathExtraData structure is not stable right now. > and have this invoked at each stage right before we call > create_grouping_paths, create_window_paths, etc. > It seems to me reasonable. > Also, I don't particularly see a need for a corresponding API for FDWs. > If an FDW is going to do anything in this space, it presumably has to > build up ForeignPaths for all the steps anyway. So I'd be inclined > to leave GetForeignUpperPaths as-is. > It seems to me reasonable. FDW driver which is interested in remote execution of upper path can use the hook arbitrary. Thanks, -- NEC Business Creation Division / PG-Strom Project KaiGai Kohei <kaigai@ak.jp.nec.com>
Kouhei Kaigai <kaigai@ak.jp.nec.com> writes:
> On Wed, Mar 16, 2016 at 2:47 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> I do not, however, like the proposal to expose wflists and so forth.
>> Those are internal data structures in grouping_planner and I absolutely
>> refuse to promise that they're going to stay stable.
> Hmm... It's not easy to imagine a case that extension wants own idea
> to extract window functions from the target list and select active
> windows, even if extension wants to have own executor and own cost
> estimation logic.
> In case when extension tries to add WindowPath + CustomPath(Sort),
> extension is interested in alternative sort task, but not window
> function itself. It is natural to follow the built-in implementation,
> thus, it motivates extension author to take copy & paste the code.
> select_active_windows() is static, so extension needs to have same
> routine on their side.
Well, to be perfectly blunt about it, I have said from day one that this
notion that a CustomScan extension will be able to cause arbitrary planner
behavior changes is loony. We are simply not going to drop a hook into
every tenth line of the planner for you, nor de-static-ify every internal
function, nor (almost equivalently) expose the data structures those
functions produce, because it would cripple core planner development to
try to keep the implied APIs stable. And I continue to maintain that any
actually-generally-useful ideas would be better handled by submitting them
as patches to the core planner, rather than trying to implement them in an
arms-length extension.
In the case at hand, I notice that the WindowFuncLists struct is
actually from find_window_functions in clauses.c, so an extension
that needed to get hold of that would be unlikely to do any copying
and pasting anyhow -- it'd just call find_window_functions again.
(That only needs to search the targetlist, so it's not that expensive.)
The other lists you mention are all tightly tied to specific, and not
terribly well-designed, implementation strategies for grouping sets and
window functions. Those are *very* likely to change in the near future;
and even if they don't, I'm skeptical that an external implementor of
grouping sets or window functions would want to use exactly those same
implementation strategies. Maybe the only reason you're there at all
is you want to be smarter about the order of doing window functions,
for example.
So I really don't want to export any of that stuff.
As for other details of the proposed patch, I was intending to put
all the hook calls into grouping_planner for consistency, rather than
scattering them between grouping_planner and its subroutines. So that
would probably mean calling the hook for a given step *before* we
generate the core paths for that step, not after. Did you have a
reason to want the other order? (If you say "so the hook can look
at the core-made paths", I'm going to say "that's a bad idea". It'd
further increase the coupling between a CustomScan extension and core.)
regards, tom lane
> -----Original Message----- > From: pgsql-hackers-owner@postgresql.org > [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Tom Lane > Sent: Friday, March 18, 2016 11:44 PM > To: Kaigai Kouhei(海外 浩平) > Cc: Robert Haas; Petr Jelinek; David Rowley; pgsql-hackers@postgresql.org > Subject: Re: [HACKERS] WIP: Upper planner pathification > > Kouhei Kaigai <kaigai@ak.jp.nec.com> writes: > > On Wed, Mar 16, 2016 at 2:47 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > >> I do not, however, like the proposal to expose wflists and so forth. > >> Those are internal data structures in grouping_planner and I absolutely > >> refuse to promise that they're going to stay stable. > > > Hmm... It's not easy to imagine a case that extension wants own idea > > to extract window functions from the target list and select active > > windows, even if extension wants to have own executor and own cost > > estimation logic. > > In case when extension tries to add WindowPath + CustomPath(Sort), > > extension is interested in alternative sort task, but not window > > function itself. It is natural to follow the built-in implementation, > > thus, it motivates extension author to take copy & paste the code. > > select_active_windows() is static, so extension needs to have same > > routine on their side. > > Well, to be perfectly blunt about it, I have said from day one that this > notion that a CustomScan extension will be able to cause arbitrary planner > behavior changes is loony. We are simply not going to drop a hook into > every tenth line of the planner for you, nor de-static-ify every internal > function, nor (almost equivalently) expose the data structures those > functions produce, because it would cripple core planner development to > try to keep the implied APIs stable. And I continue to maintain that any > actually-generally-useful ideas would be better handled by submitting them > as patches to the core planner, rather than trying to implement them in an > arms-length extension. > > In the case at hand, I notice that the WindowFuncLists struct is > actually from find_window_functions in clauses.c, so an extension > that needed to get hold of that would be unlikely to do any copying > and pasting anyhow -- it'd just call find_window_functions again. > (That only needs to search the targetlist, so it's not that expensive.) > The other lists you mention are all tightly tied to specific, and not > terribly well-designed, implementation strategies for grouping sets and > window functions. Those are *very* likely to change in the near future; > and even if they don't, I'm skeptical that an external implementor of > grouping sets or window functions would want to use exactly those same > implementation strategies. Maybe the only reason you're there at all > is you want to be smarter about the order of doing window functions, > for example. > > So I really don't want to export any of that stuff. > Hmm. I could understand we have active development around this area thus miscellaneous internal data structure may not be enough stable to expose the extension. Don't you deny recall the discussion once implementation gets calmed down on the future development cycle? > As for other details of the proposed patch, I was intending to put > all the hook calls into grouping_planner for consistency, rather than > scattering them between grouping_planner and its subroutines. So that > would probably mean calling the hook for a given step *before* we > generate the core paths for that step, not after. Did you have a > reason to want the other order? (If you say "so the hook can look > at the core-made paths", I'm going to say "that's a bad idea". It'd > further increase the coupling between a CustomScan extension and core.) > No deep reason. I just followed the manner in scan/join path hook; that calls extension once the core feature adds built-in path nodes. Thanks, -- NEC Business Creation Division / PG-Strom Project KaiGai Kohei <kaigai@ak.jp.nec.com>
On 3/17/16 9:01 AM, Robert Haas wrote: > I think that > there are an awful lot of cases where extension authors haven't been > able to quite do what they want to do without core changes because > they couldn't get control in quite the right place; or they could do > it but they had to cut-and-paste a lot of code. FWIW, I've certainly run into this at least once, maybe twice. The case I can think of offhand is doing function resolution with variant. I don't remember the details anymore, but my recollection is that to get what I needed I would have needed to copy huge swaths of the rewrite code. -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com
On Mon, Mar 21, 2016 at 7:55 AM, Jim Nasby <Jim.Nasby@bluetreble.com> wrote: > On 3/17/16 9:01 AM, Robert Haas wrote: >> >> I think that >> there are an awful lot of cases where extension authors haven't been >> able to quite do what they want to do without core changes because >> they couldn't get control in quite the right place; or they could do >> it but they had to cut-and-paste a lot of code. > > FWIW, I've certainly run into this at least once, maybe twice. The case I > can think of offhand is doing function resolution with variant. I don't > remember the details anymore, but my recollection is that to get what I > needed I would have needed to copy huge swaths of the rewrite code. Amen, I have been doing that a couple of days ago with some elog stuff. -- Michael
On 3/22/16 7:28 AM, Michael Paquier wrote: > On Mon, Mar 21, 2016 at 7:55 AM, Jim Nasby <Jim.Nasby@bluetreble.com> wrote: >> On 3/17/16 9:01 AM, Robert Haas wrote: >>> >>> I think that >>> there are an awful lot of cases where extension authors haven't been >>> able to quite do what they want to do without core changes because >>> they couldn't get control in quite the right place; or they could do >>> it but they had to cut-and-paste a lot of code. >> >> FWIW, I've certainly run into this at least once, maybe twice. The case I >> can think of offhand is doing function resolution with variant. I don't >> remember the details anymore, but my recollection is that to get what I >> needed I would have needed to copy huge swaths of the rewrite code. > > Amen, I have been doing that a couple of days ago with some elog stuff. Any ideas on ways to address this? Adding more hooks in random places every time we stumble across something doesn't seem like a good method. One thing I've wondered about is making it easier to find specific constructs in a parsed query so that you can make specific modifications. I recall looking at that once and finding a roadblock (maybe a bunch of functions were static?) -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com
> -----Original Message----- > From: pgsql-hackers-owner@postgresql.org > [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Kouhei Kaigai > Sent: Saturday, March 19, 2016 8:57 AM > To: Tom Lane > Cc: Robert Haas; Petr Jelinek; David Rowley; pgsql-hackers@postgresql.org > Subject: Re: [HACKERS] WIP: Upper planner pathification > > > -----Original Message----- > > From: pgsql-hackers-owner@postgresql.org > > [mailto:pgsql-hackers-owner@postgresql.org] On Behalf Of Tom Lane > > Sent: Friday, March 18, 2016 11:44 PM > > To: Kaigai Kouhei(海外 浩平) > > Cc: Robert Haas; Petr Jelinek; David Rowley; pgsql-hackers@postgresql.org > > Subject: Re: [HACKERS] WIP: Upper planner pathification > > > > Kouhei Kaigai <kaigai@ak.jp.nec.com> writes: > > > On Wed, Mar 16, 2016 at 2:47 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > >> I do not, however, like the proposal to expose wflists and so forth. > > >> Those are internal data structures in grouping_planner and I absolutely > > >> refuse to promise that they're going to stay stable. > > > > > Hmm... It's not easy to imagine a case that extension wants own idea > > > to extract window functions from the target list and select active > > > windows, even if extension wants to have own executor and own cost > > > estimation logic. > > > In case when extension tries to add WindowPath + CustomPath(Sort), > > > extension is interested in alternative sort task, but not window > > > function itself. It is natural to follow the built-in implementation, > > > thus, it motivates extension author to take copy & paste the code. > > > select_active_windows() is static, so extension needs to have same > > > routine on their side. > > > > Well, to be perfectly blunt about it, I have said from day one that this > > notion that a CustomScan extension will be able to cause arbitrary planner > > behavior changes is loony. We are simply not going to drop a hook into > > every tenth line of the planner for you, nor de-static-ify every internal > > function, nor (almost equivalently) expose the data structures those > > functions produce, because it would cripple core planner development to > > try to keep the implied APIs stable. And I continue to maintain that any > > actually-generally-useful ideas would be better handled by submitting them > > as patches to the core planner, rather than trying to implement them in an > > arms-length extension. > > > > In the case at hand, I notice that the WindowFuncLists struct is > > actually from find_window_functions in clauses.c, so an extension > > that needed to get hold of that would be unlikely to do any copying > > and pasting anyhow -- it'd just call find_window_functions again. > > (That only needs to search the targetlist, so it's not that expensive.) > > The other lists you mention are all tightly tied to specific, and not > > terribly well-designed, implementation strategies for grouping sets and > > window functions. Those are *very* likely to change in the near future; > > and even if they don't, I'm skeptical that an external implementor of > > grouping sets or window functions would want to use exactly those same > > implementation strategies. Maybe the only reason you're there at all > > is you want to be smarter about the order of doing window functions, > > for example. > > > > So I really don't want to export any of that stuff. > > > Hmm. I could understand we have active development around this area > thus miscellaneous internal data structure may not be enough stable > to expose the extension. > Don't you deny recall the discussion once implementation gets calmed > down on the future development cycle? > > > As for other details of the proposed patch, I was intending to put > > all the hook calls into grouping_planner for consistency, rather than > > scattering them between grouping_planner and its subroutines. So that > > would probably mean calling the hook for a given step *before* we > > generate the core paths for that step, not after. Did you have a > > reason to want the other order? (If you say "so the hook can look > > at the core-made paths", I'm going to say "that's a bad idea". It'd > > further increase the coupling between a CustomScan extension and core.) > > > No deep reason. I just followed the manner in scan/join path hook; that > calls extension once the core feature adds built-in path nodes. > Ah, I oversight a deep reason. ForeignScan/CustomScan may have an alternative execution path if extension supports corner case handling for a case when these node cannot execute or can execute but unreasonable cost actually, on execution time, even if planner thought the path is most reasonable on optimization time. One example at scan/join was EPQ rechecks. Remote join invocation was not reasonable for each EPQ recheck, thus, ForeignPath had fdw_outerpath field to pick up a core-made path. I can expect some other similar cases. For example, a custom-scan that support multi-node aggregation wants to switch to built-in aggregation if network would be unreachable to other node. For example, a custom-scan that support GPU sorting wants to switch to built-in sorting if available GPU RAM would be less than requirement on execution time. ...and so on. > (If you say "so the hook can look at the core-made paths", > I'm going to say "that's a bad idea". > I assume that you are saying it is a bad idea to reference the core-made path to construct foreign/custom-scan path itself. However, what I'm saying here is a case when extension wants to pick up a core-made cheapest path as a part of fdw_outerpath or custom_paths. Thanks, -- NEC Business Creation Division / PG-Strom Project KaiGai Kohei <kaigai@ak.jp.nec.com>
Robert Haas <robertmhaas@gmail.com> writes:
> On Thu, Mar 17, 2016 at 2:31 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> So what I would now propose is
>>
>> typedef void (*create_upper_paths_hook_type) (PlannerInfo *root,
>> UpperRelationKind stage,
>> RelOptInfo *input_rel);
>>
>> and have this invoked at each stage right before we call
>> create_grouping_paths, create_window_paths, etc.
> Works for me.
Now that the commitfest crunch is over, I went back and took care of
this loose end. I ended up passing the output_rel as well for each
step, to save hook users from having to look that up for themselves.
The hook calls are placed immediately before set_cheapest() for each
upper rel, so that all core-built Paths are available for inspection.
regards, tom lane