Обсуждение: POC: Cache data in GetSnapshotData()
Hi, I've, for a while, pondered whether we couldn't find a easier way than CSN to make snapshots cheaper as GetSnapshotData() very frequently is one of the top profile entries. Especially on bigger servers, where the pretty much guaranteed cachemisses are quite visibile. My idea is based on the observation that even in very write heavy environments the frequency of relevant PGXACT changes is noticeably lower than GetSnapshotData() calls. My idea is to simply cache the results of a GetSnapshotData() result in shared memory and invalidate it everytime something happens that affects the results. Then GetSnapshotData() can do a couple of memcpy() calls to get the snapshot - which will be significantly faster in a large number of cases. For one often enough there's many transactions without an xid assigned (and thus xip/subxip are small), for another, even if that's not the case it's linear copies instead of unpredicable random accesses through PGXACT/PGPROC. Now, that idea is pretty handwavy. After talking about it with a couple of people I've decided to write a quick POC to check whether it's actually beneficial. That POC isn't anything close to being ready or complete. I just wanted to evaluate whether the idea has some merit or not. That said, it survives make installcheck-parallel. Some very preliminary performance results indicate a growth of between 25% (pgbench -cj 796 -m prepared -f 'SELECT 1'), 15% (pgbench -s 300 -S -cj 796), 2% (pgbench -cj 96 -s 300) on a 4 x E5-4620 system. Even on my laptop I can measure benefits in a readonly, highly concurrent, workload; although unsurprisingly much smaller. Now, these are all somewhat extreme workloads, but still. It's a nice improvement for a quick POC. So far the implemented idea is to just completely wipe the cached snapshot everytime somebody commits. I've afterwards not been able to see GetSnapshotData() in the profile at all - so that possibly is actually sufficient? This implementation probably has major holes. Like it probably ends up not really increasing the xmin horizon when a longrunning readonly transaction without an xid commits... Comments about the idea? Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Вложения
>
> Hi,
>
> I've, for a while, pondered whether we couldn't find a easier way than
> CSN to make snapshots cheaper as GetSnapshotData() very frequently is
> one of the top profile entries. Especially on bigger servers, where the
> pretty much guaranteed cachemisses are quite visibile.
>
> My idea is based on the observation that even in very write heavy
> environments the frequency of relevant PGXACT changes is noticeably
> lower than GetSnapshotData() calls.
>
>
> Comments about the idea?
>
I have done some tests with this patch to see the benefit with
On 2015-05-20 19:56:39 +0530, Amit Kapila wrote: > I have done some tests with this patch to see the benefit with > and it seems to me this patch helps in reducing the contention > around ProcArrayLock, though the increase in TPS (in tpc-b tests > is around 2~4%) is not very high. > > pgbench (TPC-B test) > ./pgbench -c 64 -j 64 -T 1200 -M prepared postgres Hm, so it's a read mostly test. I probably not that badly contended on the snapshot acquisition itself. I'd guess a 80/20 read/write mix or so would be more interesting for the cases where we hit this really bad. > Without Patch (HEAD - e5f455f5) - Commit used is slightly old, but I > don't think that matters for this test. Agreed, shouldn't make much of a difference. > +1 to proceed with this patch for 9.6, as I think this patch improves the > situation with compare to current. Yea, I think so too. > Also I have seen crash once in below test scenario: > Crashed in test with scale-factor - 300, other settings same as above: > ./pgbench -c 128 -j 128 -T 1800 -M prepared postgres The patch as is really is just a proof of concept. I wrote it during a talk the flight back from fosdem... Thanks for the look. Greetings, Andres Freund
>
> On 2015-05-20 19:56:39 +0530, Amit Kapila wrote:
> > I have done some tests with this patch to see the benefit with
> > and it seems to me this patch helps in reducing the contention
> > around ProcArrayLock, though the increase in TPS (in tpc-b tests
> > is around 2~4%) is not very high.
> >
> > pgbench (TPC-B test)
> > ./pgbench -c 64 -j 64 -T 1200 -M prepared postgres
>
> Hm, so it's a read mostly test.
> the snapshot acquisition itself. I'd guess a 80/20 read/write mix or so
> would be more interesting for the cases where we hit this really bad.
>
Hi,
I've, for a while, pondered whether we couldn't find a easier way than
CSN to make snapshots cheaper as GetSnapshotData() very frequently is
one of the top profile entries. Especially on bigger servers, where the
pretty much guaranteed cachemisses are quite visibile.
My idea is based on the observation that even in very write heavy
environments the frequency of relevant PGXACT changes is noticeably
lower than GetSnapshotData() calls.
My idea is to simply cache the results of a GetSnapshotData() result in
shared memory and invalidate it everytime something happens that affects
the results. Then GetSnapshotData() can do a couple of memcpy() calls to
get the snapshot - which will be significantly faster in a large number
of cases. For one often enough there's many transactions without an xid
assigned (and thus xip/subxip are small), for another, even if that's
not the case it's linear copies instead of unpredicable random accesses
through PGXACT/PGPROC.
Now, that idea is pretty handwavy. After talking about it with a couple
of people I've decided to write a quick POC to check whether it's
actually beneficial. That POC isn't anything close to being ready or
complete. I just wanted to evaluate whether the idea has some merit or
not. That said, it survives make installcheck-parallel.
Some very preliminary performance results indicate a growth of between
25% (pgbench -cj 796 -m prepared -f 'SELECT 1'), 15% (pgbench -s 300 -S
-cj 796), 2% (pgbench -cj 96 -s 300) on a 4 x E5-4620 system. Even on my
laptop I can measure benefits in a readonly, highly concurrent,
workload; although unsurprisingly much smaller.
Now, these are all somewhat extreme workloads, but still. It's a nice
improvement for a quick POC.
So far the implemented idea is to just completely wipe the cached
snapshot everytime somebody commits. I've afterwards not been able to
see GetSnapshotData() in the profile at all - so that possibly is
actually sufficient?
This implementation probably has major holes. Like it probably ends up
not really increasing the xmin horizon when a longrunning readonly
transaction without an xid commits...
Comments about the idea?
On 5/25/15 10:04 PM, Amit Kapila wrote: > On Tue, May 26, 2015 at 12:10 AM, Andres Freund <andres@anarazel.de > <mailto:andres@anarazel.de>> wrote: > > > > On 2015-05-20 19:56:39 +0530, Amit Kapila wrote: > > > I have done some tests with this patch to see the benefit with > > > and it seems to me this patch helps in reducing the contention > > > around ProcArrayLock, though the increase in TPS (in tpc-b tests > > > is around 2~4%) is not very high. > > > > > > pgbench (TPC-B test) > > > ./pgbench -c 64 -j 64 -T 1200 -M prepared postgres > > > > Hm, so it's a read mostly test. > > Write not *Read* mostly. > > > I probably not that badly contended on > > the snapshot acquisition itself. I'd guess a 80/20 read/write mix or so > > would be more interesting for the cases where we hit this really bad. > > > > Yes 80/20 read/write mix will be good test to test this patch and I think > such a load is used by many applications (Such a load is quite common > in telecom especially their billing related applications) and currently > we don't > have such a test handy to measure performance. > > On a side note, I think it would be good if we can add such a test to > pgbench or may be use some test which adheres to TPC-C specification. > Infact, I remember [1] people posting test results with such a workload > showing ProcArrayLock as contention. > > > [1] - > http://www.postgresql.org/message-id/E8870A2F6A4B1045B1C292B77EAB207C77069A80@SZXEMA501-MBX.china.huawei.com Anything happen with this? -- Jim Nasby, Data Architect, Blue Treble Consulting, Austin TX Experts in Analytics, Data Architecture and PostgreSQL Data in Trouble? Get it in Treble! http://BlueTreble.com
On 5/25/15 10:04 PM, Amit Kapila wrote:On Tue, May 26, 2015 at 12:10 AM, Andres Freund <andres@anarazel.de<mailto:andres@anarazel.de>> wrote:
>
> On 2015-05-20 19:56:39 +0530, Amit Kapila wrote:
> > I have done some tests with this patch to see the benefit with
> > and it seems to me this patch helps in reducing the contention
> > around ProcArrayLock, though the increase in TPS (in tpc-b tests
> > is around 2~4%) is not very high.
> >
> > pgbench (TPC-B test)
> > ./pgbench -c 64 -j 64 -T 1200 -M prepared postgres
>
> Hm, so it's a read mostly test.
Write not *Read* mostly.
> I probably not that badly contended on
> the snapshot acquisition itself. I'd guess a 80/20 read/write mix or so
> would be more interesting for the cases where we hit this really bad.
>
Yes 80/20 read/write mix will be good test to test this patch and I think
such a load is used by many applications (Such a load is quite common
in telecom especially their billing related applications) and currently
we don't
have such a test handy to measure performance.
On a side note, I think it would be good if we can add such a test to
pgbench or may be use some test which adheres to TPC-C specification.
Infact, I remember [1] people posting test results with such a workload
showing ProcArrayLock as contention.
[1] -
http://www.postgresql.org/message-id/E8870A2F6A4B1045B1C292B77EAB207C77069A80@SZXEMA501-MBX.china.huawei.com
Anything happen with this?
On May 20, 2015 at 8:57 PM, Amit Kapila <amit(dot)kapila16(at)gmail(dot)com>
wrote:
> +1 to proceed with this patch for 9.6, as I think this patch improves the
> situation with compare to current.
> Also I have seen crash once in below test scenario:
> Crashed in test with scale-factor - 300, other settings same as above:
> ./pgbench -c 128 -j 128 -T 1800 -M prepared postgres
I have rebased the patch and tried to run pgbench.
I see memory corruptions, attaching the valgrind report for the same.
First interesting callstack in valgrind report is as below.
==77922== For counts of detected and suppressed errors, rerun with: -v
==77922== Use --track-origins=yes to see where uninitialised values come from
==77922== ERROR SUMMARY: 15 errors from 7 contexts (suppressed: 2 from 2)
==77873== Source and destination overlap in memcpy(0x5c08020, 0x5c08020, 4)
==77873== at 0x4C2E1DC: memcpy@@GLIBC_2.14 (in /usr/lib64/valgrind/vgpreload_memcheck-amd64-linux.so)
==77873== by 0x773303: GetSnapshotData (procarray.c:1698)
==77873== by 0x90FDB8: GetTransactionSnapshot (snapmgr.c:248)
==77873== by 0x79A22F: PortalStart (pquery.c:506)
==77873== by 0x795F67: exec_bind_message (postgres.c:1798)
==77873== by 0x798DDC: PostgresMain (postgres.c:4078)
==77873== by 0x724B27: BackendRun (postmaster.c:4237)
==77873== by 0x7242BB: BackendStartup (postmaster.c:3913)
==77873== by 0x720CF9: ServerLoop (postmaster.c:1684)
==77873== by 0x720380: PostmasterMain (postmaster.c:1292)
==77873== by 0x67CC9D: main (main.c:223)
==77873==
==77873== Source and destination overlap in memcpy(0x5c08020, 0x5c08020, 4)
==77873== at 0x4C2E1DC: memcpy@@GLIBC_2.14 (in /usr/lib64/valgrind/vgpreload_memcheck-amd64-linux.so)
==77873== by 0x77304A: GetSnapshotData (procarray.c:1579)
==77873== by 0x90FD75: GetTransactionSnapshot (snapmgr.c:233)
==77873== by 0x795A2F: exec_bind_message (postgres.c:1613)
==77873== by 0x798DDC: PostgresMain (postgres.c:4078)
==77873== by 0x724B27: BackendRun (postmaster.c:4237)
==77873== by 0x7242BB: BackendStartup (postmaster.c:3913)
==77873== by 0x720CF9: ServerLoop (postmaster.c:1684)
==77873== by 0x720380: PostmasterMain (postmaster.c:1292)
==77873== by 0x67CC9D: main (main.c:223)
Вложения
> I have rebased the patch and tried to run pgbench.
> I see memory corruptions, attaching the valgrind report for the same.Sorry forgot to add re-based patch, adding the same now.
Вложения
On 2015-12-19 22:47:30 -0800, Mithun Cy wrote: > After some analysis I saw writing to shared memory to store shared snapshot > is not protected under exclusive write lock, this leads to memory > corruptions. > I think until this is fixed measuring the performance will not be much > useful. I think at the very least the cache should be protected by a separate lock, and that lock should be acquired with TryLock. I.e. the cache is updated opportunistically. I'd go for an lwlock in the first iteration. If that works nicely we can try to keep several 'snapshot slots' around, and only lock one of them exclusively. With some care users of cached snapshots can copy the snapshot, while another slot is updated in parallel. But that's definitely not step 1. Greetings, Andres Freund
On Mon, Jan 4, 2016 at 2:28 PM, Andres Freund <andres@anarazel.de> wrote:
> I think at the very least the cache should be protected by a separate
> lock, and that lock should be acquired with TryLock. I.e. the cache is
> updated opportunistically. I'd go for an lwlock in the first iteration.
Errors are
DETAIL: Key (bid)=(24) already exists.
STATEMENT: UPDATE pgbench_branches SET bbalance = bbalance + $1 WHERE bid = $2;
client 17 aborted in state 11: ERROR: duplicate key value violates unique constraint "pgbench_branches_pkey"
DETAIL: Key (bid)=(24) already exists.
client 26 aborted in state 11: ERROR: duplicate key value violates unique constraint "pgbench_branches_pkey"
DETAIL: Key (bid)=(87) already exists.
ERROR: duplicate key value violates unique constraint "pgbench_branches_pkey"
DETAIL: Key (bid)=(113) already exists.
/*
* We don't include our own XIDs (if any) in the snapshot, but we
* must include them in xmin.
*/
if (NormalTransactionIdPrecedes(xid, xmin))
xmin = xid;
*********** if (pgxact == MyPgXact) ******************
continue;
--
Вложения
After above fix memory corruption is not visible. But I see some more failures at higher client sessions(128 it is easily reproducible).This is done with one atomic compare and swap operation.compute the snapshot(when cache is invalid) only one of them will write to cache.I tried to implement a simple patch which protect the cache. Of all the backend whichOn Mon, Jan 4, 2016 at 2:28 PM, Andres Freund <andres@anarazel.de> wrote:
> I think at the very least the cache should be protected by a separate
> lock, and that lock should be acquired with TryLock. I.e. the cache is
> updated opportunistically. I'd go for an lwlock in the first iteration.
After above fix memory corruption is not visible. But I see some more failures at higher client sessions(128 it is easily reproducible).This is done with one atomic compare and swap operation.compute the snapshot(when cache is invalid) only one of them will write to cache.I tried to implement a simple patch which protect the cache. Of all the backend whichOn Mon, Jan 4, 2016 at 2:28 PM, Andres Freund <andres@anarazel.de> wrote:
> I think at the very least the cache should be protected by a separate
> lock, and that lock should be acquired with TryLock. I.e. the cache is
> updated opportunistically. I'd go for an lwlock in the first iteration.
Errors are
DETAIL: Key (bid)=(24) already exists.
STATEMENT: UPDATE pgbench_branches SET bbalance = bbalance + $1 WHERE bid = $2;
client 17 aborted in state 11: ERROR: duplicate key value violates unique constraint "pgbench_branches_pkey"
DETAIL: Key (bid)=(24) already exists.
client 26 aborted in state 11: ERROR: duplicate key value violates unique constraint "pgbench_branches_pkey"
DETAIL: Key (bid)=(87) already exists.
ERROR: duplicate key value violates unique constraint "pgbench_branches_pkey"
DETAIL: Key (bid)=(113) already exists.After some analysis I think In GetSnapshotData() while computing snapshot.
/*
* We don't include our own XIDs (if any) in the snapshot, but we
* must include them in xmin.
*/
if (NormalTransactionIdPrecedes(xid, xmin))
xmin = xid;
*********** if (pgxact == MyPgXact) ******************
continue;We do not add our own xid to xip array, I am wondering if other backend try to usethe same snapshot will it be able to see changes made by me(current backend).I think since we compute a snapshot which will be used by other backends we need toadd our xid to xip array to tell transaction is open.
{
int *pgprocnos = arrayP->pgprocnos;
int numProcs;
+ const uint32 snapshot_cached= 0;
Note: GetSnapshotData never stores either top xid or subxids of our own
backend into a snapshot, so these xids will not be reported as "running"
by this function. This is OK for current uses, because we always check
TransactionIdIsCurrentTransactionId first, except for known-committed
XIDs which could not be ours anyway.
>On Fri, Jan 15, 2016 at 11:23 AM, Mithun Cy <mithun.cy@enterprisedb.com> wrote:On Mon, Jan 4, 2016 at 2:28 PM, Andres Freund <andres@anarazel.de> wrote:
>> I think at the very least the cache should be protected by a separate
>> lock, and that lock should be acquired with TryLock. I.e. the cache is
>> updated opportunistically. I'd go for an lwlock in the first iteration.>I also think this observation of yours is right and currently that is>okay because we always first check TransactionIdIsCurrentTransactionId().
>+ const uint32 snapshot_cached= 0;
I also did some read-only perf tests.
Non-Default Settings.
================
scale_factor=300.
./postgres -c shared_buffers=16GB -N 200 -c min_wal_size=15GB -c max_wal_size=20GB -c checkpoint_timeout=900 -c maintenance_work_mem=1GB -c checkpoint_completion_target=0.9
./pgbench -c $clients -j $clients -T 300 -M prepared -S postgres
Machine Detail:
cpu : POWER8
cores: 24 (192 with HT).
Clients Base With cached snapshot
1 19653.914409 19926.884664
16 190764.519336 190040.299297
32 339327.881272 354467.445076
48 462632.02493 464767.917813
64 522642.515148 533271.556703
80 515262.813189 513353.962521
But did not see any perf improvement. Will continue testing the same.
--
Вложения
On Thu, Feb 25, 2016 at 12:57 PM, Mithun Cy <mithun.cy@enterprisedb.com> wrote: > I have fixed all of the issues reported by regress test. Also now when > backend try to cache the snapshot we also try to store the self-xid and sub > xid, so other backends can use them. > > I also did some read-only perf tests. I'm not sure what you are doing that keeps breaking threading for Gmail, but this thread is getting split up for me into multiple threads with only a few messages in each. The same seems to be happening in the community archives. Please try to figure out what is causing that and stop doing it. I notice you seem to not to have implemented this suggestion by Andres: http://www.postgresql.org//message-id/20160104085845.m5nrypvmmpea5nm7@alap3.anarazel.de Also, you should test this on a machine with more than 2 cores. Andres's original test seems to have been on a 4-core system, where this would be more likely to work out. Also, Andres suggested testing this on an 80-20 write mix, where as you tested it on 100% read-only. In that case there is no blocking ProcArrayLock, which reduces the chances that the patch will benefit. I suspect, too, that the chances of this patch working out have probably been reduced by 0e141c0fbb211bdd23783afa731e3eef95c9ad7a, which seems to be targeting mostly the same problem. I mean it's possible that this patch could win even when no ProcArrayLock-related blocking is happening, but the original idea seems to have been that it would help mostly with that case. You could try benchmarking it on the commit just before that one and then on current sources and see if you get the same results on both, or if there was more benefit before that commit. Also, you could consider repeating the LWLOCK_STATS testing that Amit did in his original reply to Andres. That would tell you whether the performance is not increasing because the patch doesn't reduce ProcArrayLock contention, or whether the performance is not increasing because the patch DOES reduce ProcArrayLock contention but then the contention shifts to CLogControlLock or elsewhere. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
>
> On Thu, Feb 25, 2016 at 12:57 PM, Mithun Cy <mithun.cy@enterprisedb.com> wrote:
> > I have fixed all of the issues reported by regress test. Also now when
> > backend try to cache the snapshot we also try to store the self-xid and sub
> > xid, so other backends can use them.
> >
> > I also did some read-only perf tests.
>
> I'm not sure what you are doing that keeps breaking threading for
> Gmail, but this thread is getting split up for me into multiple
> threads with only a few messages in each. The same seems to be
> happening in the community archives. Please try to figure out what is
> causing that and stop doing it.
>
> I notice you seem to not to have implemented this suggestion by Andres:
>
> http://www.postgresql.org//message-id/20160104085845.m5nrypvmmpea5nm7@alap3.anarazel.de
>
> Also, you should test this on a machine with more than 2 cores.
> Andres's original test seems to have been on a 4-core system, where
> this would be more likely to work out.
>
> Also, Andres suggested testing this on an 80-20 write mix, where as
> you tested it on 100% read-only. In that case there is no blocking
> ProcArrayLock, which reduces the chances that the patch will benefit.
>
+1
>
> Also, you could consider repeating the LWLOCK_STATS testing that Amit
> did in his original reply to Andres. That would tell you whether the
> performance is not increasing because the patch doesn't reduce
> ProcArrayLock contention, or whether the performance is not increasing
> because the patch DOES reduce ProcArrayLock contention but then the
> contention shifts to CLogControlLock or elsewhere.
>
./pgbench -c $clients -j $clients -T 1800 -M prepared postgres
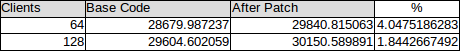
ProcArrayLock: Base.
=================
postgresql-2016-03-01_115252.log:PID 110019 lwlock main 4: shacq 1867601 exacq 35625 blk 134682 spindelay 128 dequeue self 28871
postgresql-2016-03-01_115253.log:PID 110115 lwlock main 4: shacq 2201613 exacq 43489 blk 155499 spindelay 127 dequeue self 32751
postgresql-2016-03-01_115253.log:PID 110122 lwlock main 4: shacq 2231327 exacq 44824 blk 159440 spindelay 128 dequeue self 33336
postgresql-2016-03-01_115254.log:PID 110126 lwlock main 4: shacq 2247983 exacq 44632 blk 158669 spindelay 131 dequeue self 33365
postgresql-2016-03-01_115254.log:PID 110059 lwlock main 4: shacq 2036809 exacq 38607 blk 143538 spindelay 117 dequeue self 31008
ProcArrayLock: With Patch.
=====================
postgresql-2016-03-01_124747.log:PID 1789 lwlock main 4: shacq 2273958 exacq 61605 blk 79581 spindelay 307 dequeue self 66088
postgresql-2016-03-01_124748.log:PID 1880 lwlock main 4: shacq 2456388 exacq 65996 blk 82300 spindelay 470 dequeue self 68770
postgresql-2016-03-01_124748.log:PID 1765 lwlock main 4: shacq 2244083 exacq 60835 blk 79042 spindelay 336 dequeue self 65212
postgresql-2016-03-01_124749.log:PID 1882 lwlock main 4: shacq 2489271 exacq 67043 blk 85650 spindelay 463 dequeue self 68401
postgresql-2016-03-01_124749.log:PID 1753 lwlock main 4: shacq 2232791 exacq 60647 blk 78659 spindelay 364 dequeue self 65180
postgresql-2016-03-01_124750.log:PID 1849 lwlock main 4: shacq 2374922 exacq 64075 blk 81860 spindelay 339 dequeue self 67584
-------------Block time of ProcArrayLock has reduced significantly.
ClogControlLock : Base.
===================
postgresql-2016-03-01_115302.log:PID 110040 lwlock main 11: shacq 586129 exacq 268808 blk 90570 spindelay 261 dequeue self 59619
postgresql-2016-03-01_115303.log:PID 110047 lwlock main 11: shacq 593492 exacq 271019 blk 89547 spindelay 268 dequeue self 59999
postgresql-2016-03-01_115303.log:PID 110078 lwlock main 11: shacq 620830 exacq 285244 blk 92939 spindelay 262 dequeue self 61912
postgresql-2016-03-01_115304.log:PID 110083 lwlock main 11: shacq 633101 exacq 289983 blk 93485 spindelay 262 dequeue self 62394
postgresql-2016-03-01_115305.log:PID 110105 lwlock main 11: shacq 646584 exacq 297598 blk 93331 spindelay 312 dequeue self 63279
ClogControlLock : With Patch.
=======================
postgresql-2016-03-01_124730.log:PID 1865 lwlock main 11: shacq 722881 exacq 330273 blk 106163 spindelay 468 dequeue self 80316
postgresql-2016-03-01_124731.log:PID 1857 lwlock main 11: shacq 713720 exacq 327158 blk 106719 spindelay 439 dequeue self 79996
postgresql-2016-03-01_124732.log:PID 1826 lwlock main 11: shacq 696762 exacq 317239 blk 104523 spindelay 448 dequeue self 79374
postgresql-2016-03-01_124732.log:PID 1862 lwlock main 11: shacq 721272 exacq 330350 blk 105965 spindelay 492 dequeue self 81036
postgresql-2016-03-01_124733.log:PID 1879 lwlock main 11: shacq 737398 exacq 335357 blk 105424 spindelay 520 dequeue self 80977
-------------Block time of ClogControlLock has increased slightly.
Will continue with further tests on lower clients.
Вложения
On Tue, Mar 1, 2016 at 12:59 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:>Don't we need to add this only when the xid of current transaction is valid? Also, I think it will be better if we can explain why we need to add the our >own transaction id while caching the snapshot.I have fixed the same thing and patch is attached.Some more tests done after thatpgbench write tests: on 8 socket, 64 core machine./postgres -c shared_buffers=16GB -N 200 -c min_wal_size=15GB -c max_wal_size=20GB -c checkpoint_timeout=900 -c maintenance_work_mem=1GB -c checkpoint_completion_target=0.9
./pgbench -c $clients -j $clients -T 1800 -M prepared postgresA small improvement in performance at 64 thread.
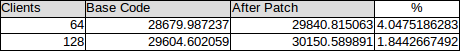
--
Вложения
>What if you apply both this and Amit's clog control log patch(es)? Maybe the combination of the two helps substantially more than either >one alone.
| clients | BASE | ONLY CLOG CHANGES | % Increase | ONLY SAVE SNAPSHOT | % Increase | CLOG CHANGES + SAVE SNAPSHOT | % Increase |
| 64 | 29247.658034 | 30855.728835 | 5.4981181711 | 29254.532186 | 0.0235032562 | 32691.832776 | 11.7758992463 |
| 88 | 31214.305391 | 33313.393095 | 6.7247618606 | 32109.248609 | 2.8670931702 | 35433.655203 | 13.5173592978 |
| 128 | 30896.673949 | 34015.362152 | 10.0939285832 | *** | *** | 34947.296355 | 13.110221549 |
| 256 | 27183.780921 | 31192.895437 | 14.7481857938 | *** | *** | 32873.782735 | 20.9316056164 |
On Thu, Mar 3, 2016 at 11:50 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>What if you apply both this and Amit's clog control log patch(es)? Maybe the combination of the two helps substantially more than either >one alone.I did the above tests along with Amit's clog patch. Machine :8 socket, 64 core. 128 hyperthread.With clog changes, perf of caching the snapshot patch improves.
clients BASE ONLY CLOG CHANGES % Increase ONLY SAVE SNAPSHOT % Increase CLOG CHANGES + SAVE SNAPSHOT % Increase 64 29247.658034 30855.728835 5.4981181711 29254.532186 0.0235032562 32691.832776 11.7758992463 88 31214.305391 33313.393095 6.7247618606 32109.248609 2.8670931702 35433.655203 13.5173592978 128 30896.673949 34015.362152 10.0939285832 *** *** 34947.296355 13.110221549 256 27183.780921 31192.895437 14.7481857938 *** *** 32873.782735 20.9316056164
| clients | BASE | ONLY CLOG CHANGES | % Increase | ONLY SAVE SNAPSHOT | % Increase | CLOG CHANGES + SAVE SNAPSHOT | % Increase |
| 88 | 36055.425005 | 52796.618434 | 46.4318294034 | 37728.004118 | 4.6389111008 | 56025.454917 | 55.3870323515 |
| Clients | + WITH INCREASE IN CLOG BUFFER | % increase |
| 88 | 58217.924138 | 61.4678626862 |
On Thu, Mar 10, 2016 at 1:04 PM, Mithun Cy <mithun.cy@enterprisedb.com> wrote:On Thu, Mar 3, 2016 at 11:50 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>What if you apply both this and Amit's clog control log patch(es)? Maybe the combination of the two helps substantially more than either >one alone.I did the above tests along with Amit's clog patch. Machine :8 socket, 64 core. 128 hyperthread.With clog changes, perf of caching the snapshot patch improves.
clients BASE ONLY CLOG CHANGES % Increase ONLY SAVE SNAPSHOT % Increase CLOG CHANGES + SAVE SNAPSHOT % Increase 64 29247.658034 30855.728835 5.4981181711 29254.532186 0.0235032562 32691.832776 11.7758992463 88 31214.305391 33313.393095 6.7247618606 32109.248609 2.8670931702 35433.655203 13.5173592978 128 30896.673949 34015.362152 10.0939285832 *** *** 34947.296355 13.110221549 256 27183.780921 31192.895437 14.7481857938 *** *** 32873.782735 20.9316056164 This data looks promising to me and indicates that saving the snapshot has benefits and we can see noticeable performance improvement especially once the CLog contention gets reduced. I wonder if we should try these tests with unlogged tables, because I suspect most of the contention after CLogControlLock and ProcArrayLock is for WAL related locks, so you might be able to see better gain with these patches. Do you think it makes sense to check the performance by increasing CLOG buffers (patch for same is posted in Speed up Clog thread [1]) as that also relieves contention on CLOG as per the tests I have done?
--
> I will continue to benchmark above tests with much wider range of clients.
| clients | BASE | ONLY CLOG CHANGES | % Increase | CLOG CHANGES + SAVE SNAPSHOT | % Increase |
| 1 | 1198.326337 | 1328.069656 | 10.8270439357 | 1234.078342 | 2.9834948875 |
| 32 | 37455.181727 | 38295.250519 | 2.2428640131 | 41023.126293 | 9.5259037641 |
| 64 | 48838.016451 | 50675.845885 | 3.7631123611 | 51662.814319 | 5.7840143259 |
| 88 | 36878.187766 | 53173.577363 | 44.1870671639 | 56025.454917 | 51.9203038731 |
| 128 | 35901.537773 | 52026.024098 | 44.9130798434 | 53864.486733 | 50.0339263281 |
| 256 | 28130.354402 | 46793.134156 | 66.3439197647 | 46817.04602 | 66.4289235427 |
On Thu, Mar 3, 2016 at 6:20 AM, Mithun Cy <mithun.cy@enterprisedb.com> wrote:
> I will continue to benchmark above tests with much wider range of clients.Latest Benchmarking shows following results for unlogged tables.
clients BASE ONLY CLOG CHANGES % Increase CLOG CHANGES + SAVE SNAPSHOT % Increase 1 1198.326337 1328.069656 10.8270439357 1234.078342 2.9834948875 32 37455.181727 38295.250519 2.2428640131 41023.126293 9.5259037641 64 48838.016451 50675.845885 3.7631123611 51662.814319 5.7840143259 88 36878.187766 53173.577363 44.1870671639 56025.454917 51.9203038731 128 35901.537773 52026.024098 44.9130798434 53864.486733 50.0339263281 256 28130.354402 46793.134156 66.3439197647 46817.04602 66.4289235427
--
On 2016-03-16 13:29:22 -0400, Robert Haas wrote: > Whoa. At 64 clients, we're hardly getting any benefit, but then by 88 > clients, we're getting a huge benefit. I wonder why there's that sharp > change there. What's the specifics of the machine tested? I wonder if it either correlates with the number of hardware threads, real cores, or cache sizes. - Andres
On Wed, Mar 16, 2016 at 1:33 PM, Andres Freund <andres@anarazel.de> wrote: > On 2016-03-16 13:29:22 -0400, Robert Haas wrote: >> Whoa. At 64 clients, we're hardly getting any benefit, but then by 88 >> clients, we're getting a huge benefit. I wonder why there's that sharp >> change there. > > What's the specifics of the machine tested? I wonder if it either > correlates with the number of hardware threads, real cores, or cache > sizes. I think this was done on cthulhu, whose /proc/cpuinfo output ends this way: processor : 127 vendor_id : GenuineIntel cpu family : 6 model : 47 model name : Intel(R) Xeon(R) CPU E7- 8830 @ 2.13GHz stepping : 2 microcode : 0x37 cpu MHz : 2129.000 cache size : 24576 KB physical id : 3 siblings : 16 core id : 25 cpu cores : 8 apicid : 243 initial apicid : 243 fpu : yes fpu_exception : yes cpuid level : 11 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic popcnt aes lahf_lm ida arat epb dtherm tpr_shadow vnmi flexpriority ept vpid bogomips : 4266.62 clflush size : 64 cache_alignment : 64 address sizes : 44 bits physical, 48 bits virtual power management: -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Mar 16, 2016 at 4:40 AM, Mithun Cy <mithun.cy@enterprisedb.com> wrote:On Thu, Mar 3, 2016 at 6:20 AM, Mithun Cy <mithun.cy@enterprisedb.com> wrote:
> I will continue to benchmark above tests with much wider range of clients.Latest Benchmarking shows following results for unlogged tables.
clients BASE ONLY CLOG CHANGES % Increase CLOG CHANGES + SAVE SNAPSHOT % Increase 1 1198.326337 1328.069656 10.8270439357 1234.078342 2.9834948875 32 37455.181727 38295.250519 2.2428640131 41023.126293 9.5259037641 64 48838.016451 50675.845885 3.7631123611 51662.814319 5.7840143259 88 36878.187766 53173.577363 44.1870671639 56025.454917 51.9203038731 128 35901.537773 52026.024098 44.9130798434 53864.486733 50.0339263281 256 28130.354402 46793.134156 66.3439197647 46817.04602 66.4289235427 Whoa. At 64 clients, we're hardly getting any benefit, but then by 88 clients, we're getting a huge benefit. I wonder why there's that sharp change there.
On Thu, Mar 17, 2016 at 9:00 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
I am attaching LWLock stats data for above test setups(unlogged tables).
| BASE | At 64 clients Block-time unit | At 88 clients Block-time unit |
| ProcArrayLock | 182946 | 117827 |
| ClogControlLock | 107420 | 120266 |
| clog patch | ||
| ProcArrayLock | 183663 | 121215 |
| ClogControlLock | 72806 | 65220 |
| clog patch + save snapshot | ||
| ProcArrayLock | 128260 | 83356 |
| ClogControlLock | 78921 | 74011 |
Вложения
>Do you think it makes sense to check the performance by increasing CLOG buffers (patch for same is posted in Speed up Clog thread [1]) >as that also relieves contention on CLOG as per the tests I have done?
| clients | BASE | + WITH INCREASE IN CLOG BUFFER Patch | % Increase |
| 1 | 1198.326337 | 1275.461955 | 6.4369458985 |
| 32 | 37455.181727 | 41239.13593 | 10.102618726 |
| 64 | 48838.016451 | 56362.163626 | 15.4063324471 |
| 88 | 36878.187766 | 58217.924138 | 57.8654691695 |
| 128 | 35901.537773 | 58239.783982 | 62.22086182 |
| 256 | 28130.354402 | 56417.133939 | 100.5560723934 |
Thanks and Regards
On Tue, Mar 22, 2016 at 4:42 AM, Mithun Cy <mithun.cy@enterprisedb.com> wrote: > On Thu, Mar 10, 2016 at 1:36 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > >Do you think it makes sense to check the performance by increasing CLOG buffers (patch for same is posted in Speed upClog thread [1]) >as that also relieves contention on CLOG as per the tests I have done? > > Along with clog patches and save snapshot, I also applied Amit's increase clog buffer patch. Below is the benchmark results. I think that we really shouldn't do anything about this patch until after the CLOG stuff is settled, which it isn't yet. So I'm going to mark this Returned with Feedback; let's reconsider it for 9.7. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Apr 8, 2016 at 12:13 PM, Robert Haas <robertmhaas@gmail.com> wrote: > I think that we really shouldn't do anything about this patch until > after the CLOG stuff is settled, which it isn't yet. So I'm going to > mark this Returned with Feedback; let's reconsider it for 9.7. I am updating a rebased patch have tried to benchmark again could see good improvement in the pgbench read-only case at very high clients on our cthulhu (8 nodes, 128 hyper thread machines) and power2 (4 nodes, 192 hyper threads) machine. There is some issue with base code benchmarking which is somehow not consistent so once I could figure out what is the issue with that I will update -- Thanks and Regards Mithun C Y EnterpriseDB: http://www.enterprisedb.com -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
I have made few more changes with the new patch. 1. Ran pgindent. 2. Instead of an atomic state variable to make only one process cache the snapshot in shared memory, I have used conditional try lwlock. With this, we have a small and reliable code. 3. Performance benchmarking Machine - cthulhu ============== [mithun.cy@cthulhu bin]$ lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 128 On-line CPU(s) list: 0-127 Thread(s) per core: 2 Core(s) per socket: 8 Socket(s): 8 NUMA node(s): 8 Vendor ID: GenuineIntel CPU family: 6 Model: 47 Model name: Intel(R) Xeon(R) CPU E7- 8830 @ 2.13GHz Stepping: 2 CPU MHz: 1197.000 BogoMIPS: 4266.63 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 24576K NUMA node0 CPU(s): 0,65-71,96-103 NUMA node1 CPU(s): 72-79,104-111 NUMA node2 CPU(s): 80-87,112-119 NUMA node3 CPU(s): 88-95,120-127 NUMA node4 CPU(s): 1-8,33-40 NUMA node5 CPU(s): 9-16,41-48 NUMA node6 CPU(s): 17-24,49-56 NUMA node7 CPU(s): 25-32,57-64 Server configuration: ./postgres -c shared_buffers=8GB -N 300 -c min_wal_size=15GB -c max_wal_size=20GB -c checkpoint_timeout=900 -c maintenance_work_mem=1GB -c checkpoint_completion_target=0.9 -c wal_buffers=256MB & pgbench configuration: scale_factor = 300 ./pgbench -c $threads -j $threads -T $time_for_reading -M prepared -S postgres The machine has 64 cores with this patch I can see server starts improvement after 64 clients. I have tested up to 256 clients. Which shows performance improvement nearly max 39%. Alternatively, I thought instead of storing the snapshot in a shared memory each backend can hold on to its previously computed snapshot until next commit/rollback happens in the system. We can have a global counter value associated with the snapshot when ever it is computed. Upon any new end of the transaction, the global counter will be incremented. So when a process wants a new snapshot it can compare these 2 values to check if it can use previously computed snapshot. This makes code significantly simple. With the first approach, one process has to compute and store the snapshot for every end of the transaction and others can reuse the cached the snapshot. In the second approach, every process has to re-compute the snapshot. So I am keeping with the same approach. On Mon, Jul 10, 2017 at 10:13 AM, Mithun Cy <mithun.cy@enterprisedb.com> wrote: > On Fri, Apr 8, 2016 at 12:13 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> I think that we really shouldn't do anything about this patch until >> after the CLOG stuff is settled, which it isn't yet. So I'm going to >> mark this Returned with Feedback; let's reconsider it for 9.7. > > I am updating a rebased patch have tried to benchmark again could see > good improvement in the pgbench read-only case at very high clients on > our cthulhu (8 nodes, 128 hyper thread machines) and power2 (4 nodes, > 192 hyper threads) machine. There is some issue with base code > benchmarking which is somehow not consistent so once I could figure > out what is the issue with that I will update > > -- > Thanks and Regards > Mithun C Y > EnterpriseDB: http://www.enterprisedb.com -- Thanks and Regards Mithun C Y EnterpriseDB: http://www.enterprisedb.com -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
On Wed, Aug 2, 2017 at 3:42 PM, Mithun Cy <mithun.cy@enterprisedb.com> wrote: Sorry, there was an unnecessary header included in proc.c which should be removed adding the corrected patch. -- Thanks and Regards Mithun C Y EnterpriseDB: http://www.enterprisedb.com -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
Hi,
I think this patch should have a "cover letter" explaining what it's
trying to achieve, how it does so and why it's safe/correct. I think
it'd also be good to try to show some of the worst cases of this patch
(i.e. where the caching only adds overhead, but never gets used), and
some of the best cases (where the cache gets used quite often, and
reduces contention significantly).
I wonder if there's a way to avoid copying the snapshot into the cache
in situations where we're barely ever going to need it. But right now
the only way I can think of is to look at the length of the
ProcArrayLock wait queue and count the exclusive locks therein - which'd
be expensive and intrusive...
On 2017-08-02 15:56:21 +0530, Mithun Cy wrote:
> diff --git a/src/backend/storage/ipc/procarray.c b/src/backend/storage/ipc/procarray.c
> index a7e8cf2..4d7debe 100644
> --- a/src/backend/storage/ipc/procarray.c
> +++ b/src/backend/storage/ipc/procarray.c
> @@ -366,11 +366,13 @@ ProcArrayRemove(PGPROC *proc, TransactionId latestXid)
> (arrayP->numProcs - index - 1) * sizeof(int));
> arrayP->pgprocnos[arrayP->numProcs - 1] = -1; /* for debugging */
> arrayP->numProcs--;
> + ProcGlobal->is_snapshot_valid = false;
> LWLockRelease(ProcArrayLock);
> return;
> }
> }
>
> + ProcGlobal->is_snapshot_valid = false;
> /* Oops */
> LWLockRelease(ProcArrayLock);
Why do we need to do anything here? And if we need to, why not in
ProcArrayAdd?
> @@ -1552,6 +1557,8 @@ GetSnapshotData(Snapshot snapshot)
> errmsg("out of memory")));
> }
>
> + snapshot->takenDuringRecovery = RecoveryInProgress();
> +
> /*
> * It is sufficient to get shared lock on ProcArrayLock, even if we are
> * going to set MyPgXact->xmin.
> @@ -1566,100 +1573,200 @@ GetSnapshotData(Snapshot snapshot)
> /* initialize xmin calculation with xmax */
> globalxmin = xmin = xmax;
>
> - snapshot->takenDuringRecovery = RecoveryInProgress();
> -
This movement of code seems fairly unrelated?
> if (!snapshot->takenDuringRecovery)
> {
Do we really need to restrict this to !recovery snapshots? It'd be nicer
if we could generalize it - I don't immediately see anything !recovery
specific in the logic here.
> - int *pgprocnos = arrayP->pgprocnos;
> - int numProcs;
> + if (ProcGlobal->is_snapshot_valid)
> + {
> + Snapshot csnap = &ProcGlobal->cached_snapshot;
> + TransactionId *saved_xip;
> + TransactionId *saved_subxip;
>
> - /*
> - * Spin over procArray checking xid, xmin, and subxids. The goal is
> - * to gather all active xids, find the lowest xmin, and try to record
> - * subxids.
> - */
> - numProcs = arrayP->numProcs;
> - for (index = 0; index < numProcs; index++)
> + saved_xip = snapshot->xip;
> + saved_subxip = snapshot->subxip;
> +
> + memcpy(snapshot, csnap, sizeof(SnapshotData));
> +
> + snapshot->xip = saved_xip;
> + snapshot->subxip = saved_subxip;
> +
> + memcpy(snapshot->xip, csnap->xip,
> + sizeof(TransactionId) * csnap->xcnt);
> + memcpy(snapshot->subxip, csnap->subxip,
> + sizeof(TransactionId) * csnap->subxcnt);
> + globalxmin = ProcGlobal->cached_snapshot_globalxmin;
> + xmin = csnap->xmin;
> +
> + count = csnap->xcnt;
> + subcount = csnap->subxcnt;
> + suboverflowed = csnap->suboverflowed;
> +
> + Assert(TransactionIdIsValid(globalxmin));
> + Assert(TransactionIdIsValid(xmin));
> + }
Can we move this to a separate function? In fact, could you check how
much effort it'd be to split cached, !recovery, recovery cases into
three static inline helper functions? This is starting to be hard to
read, the indentation added in this patch doesn't help... Consider doing
recovery, !recovery cases in a preliminary separate patch.
> + * Let only one of the caller cache the computed snapshot, and
> + * others can continue as before.
> */
> - if (!suboverflowed)
> + if (!ProcGlobal->is_snapshot_valid &&
> + LWLockConditionalAcquire(&ProcGlobal->CachedSnapshotLock,
> + LW_EXCLUSIVE))
> {
I'd also move this to a helper function (the bit inside the lock).
> +
> + /*
> + * The memory barrier has be to be placed here to ensure that
> + * is_snapshot_valid is set only after snapshot is cached.
> + */
> + pg_write_barrier();
> + ProcGlobal->is_snapshot_valid = true;
> + LWLockRelease(&ProcGlobal->CachedSnapshotLock);
LWLockRelease() is a full memory barrier, so this shouldn't be required.
> /*
> diff --git a/src/include/storage/proc.h b/src/include/storage/proc.h
> index 7dbaa81..7d06904 100644
> --- a/src/include/storage/proc.h
> +++ b/src/include/storage/proc.h
> @@ -16,6 +16,7 @@
>
> #include "access/xlogdefs.h"
> #include "lib/ilist.h"
> +#include "utils/snapshot.h"
> #include "storage/latch.h"
> #include "storage/lock.h"
> #include "storage/pg_sema.h"
> @@ -253,6 +254,22 @@ typedef struct PROC_HDR
> int startupProcPid;
> /* Buffer id of the buffer that Startup process waits for pin on, or -1 */
> int startupBufferPinWaitBufId;
> +
> + /*
> + * In GetSnapshotData we can reuse the previously snapshot computed if no
> + * new transaction has committed or rolledback. Thus saving good amount of
> + * computation cycle under GetSnapshotData where we need to iterate
> + * through procArray every time we try to get the current snapshot. Below
> + * members help us to save the previously computed snapshot in global
> + * shared memory and any process which want to get current snapshot can
> + * directly copy from them if it is still valid.
> + */
> + SnapshotData cached_snapshot; /* Previously saved snapshot */
> + volatile bool is_snapshot_valid; /* is above snapshot valid */
> + TransactionId cached_snapshot_globalxmin; /* globalxmin when above
I'd rename is_snapshot_valid to 'cached_snapshot_valid' or such, it's
not clear from the name what it refers to.
> + LWLock CachedSnapshotLock; /* A try lock to make sure only one
> + * process write to cached_snapshot */
> } PROC_HDR;
>
Hm, I'd not add the lock to the struct, we normally don't do that for
the "in core" lwlocks that don't exist in a "configurable" number like
the buffer locks and such.
Regards,
Andres
Cache the SnapshotData for reuse:
===========================
In one of our perf analysis using perf tool it showed GetSnapshotData
takes a very high percentage of CPU cycles on readonly workload when
there is very high number of concurrent connections >= 64.
Machine : cthulhu 8 node machine.
----------------------------------------------
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 8
NUMA node(s): 8
Vendor ID: GenuineIntel
CPU family: 6
Model: 47
Model name: Intel(R) Xeon(R) CPU E7- 8830 @ 2.13GHz
Stepping: 2
CPU MHz: 2128.000
BogoMIPS: 4266.63
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 24576K
NUMA node0 CPU(s): 0,65-71,96-103
NUMA node1 CPU(s): 72-79,104-111
NUMA node2 CPU(s): 80-87,112-119
NUMA node3 CPU(s): 88-95,120-127
NUMA node4 CPU(s): 1-8,33-40
NUMA node5 CPU(s): 9-16,41-48
NUMA node6 CPU(s): 17-24,49-56
NUMA node7 CPU(s): 25-32,57-64
Perf CPU cycle 128 clients.
On further analysis, it appears this mainly accounts to cache-misses
happening while iterating through large proc array to compute the
SnapshotData. Also, it seems mainly on read-only (read heavy) workload
SnapshotData mostly remains same as no new(rarely a) transaction
commits or rollbacks. Taking advantage of this we can save the
previously computed SanspshotData in shared memory and in
GetSnapshotData we can use the saved SnapshotData instead of computing
same when it is still valid. A saved SnapsotData is valid until no
transaction end.
[Perf analysis Base]
Samples: 421K of event 'cache-misses', Event count (approx.): 160069274
Overhead Command Shared Object Symbol
18.63% postgres postgres [.] GetSnapshotData
11.98% postgres postgres [.] _bt_compare
10.20% postgres postgres [.] PinBuffer 8.63% postgres postgres [.] LWLockAttemptLock
6.50% postgres postgres [.] LWLockRelease
[Perf analysis with Patch]
Server configuration:
./postgres -c shared_buffers=8GB -N 300 -c min_wal_size=15GB -c
max_wal_size=20GB -c checkpoint_timeout=900 -c
maintenance_work_mem=1GB -c checkpoint_completion_target=0.9 -c
wal_buffers=256MB &
pgbench configuration:
scale_factor = 300
./pgbench -c $threads -j $threads -T $time_for_reading -M prepared -S postgres
The machine has 64 cores with this patch I can see server starts
improvement after 64 clients. I have tested up to 256 clients. Which
shows performance improvement nearly max 39% [1]. This is the best
case for the patch where once computed snapshotData is reused further.
The worst case seems to be small, quick write transactions with which
frequently invalidate the cached SnapshotData before it is reused by
any next GetSnapshotData call. As of now, I tested simple update
tests: pgbench -M Prepared -N on the same machine with the above
server configuration. I do not see much change in TPS numbers.
All TPS are median of 3 runs
Clients TPS-With Patch 05 TPS-Base %Diff
1 752.461117 755.186777 -0.3%
64 32171.296537 31202.153576 +3.1%
128 41059.660769 40061.929658 +2.49%
I will do some profiling and find out why this case is not costing us
some performance due to caching overhead.
[]
On Thu, Aug 3, 2017 at 2:16 AM, Andres Freund <andres@anarazel.de> wrote:
> Hi,
>
> I think this patch should have a "cover letter" explaining what it's
> trying to achieve, how it does so and why it's safe/correct. I think
> it'd also be good to try to show some of the worst cases of this patch
> (i.e. where the caching only adds overhead, but never gets used), and
> some of the best cases (where the cache gets used quite often, and
> reduces contention significantly).
>
> I wonder if there's a way to avoid copying the snapshot into the cache
> in situations where we're barely ever going to need it. But right now
> the only way I can think of is to look at the length of the
> ProcArrayLock wait queue and count the exclusive locks therein - which'd
> be expensive and intrusive...
>
>
> On 2017-08-02 15:56:21 +0530, Mithun Cy wrote:
>> diff --git a/src/backend/storage/ipc/procarray.c b/src/backend/storage/ipc/procarray.c
>> index a7e8cf2..4d7debe 100644
>> --- a/src/backend/storage/ipc/procarray.c
>> +++ b/src/backend/storage/ipc/procarray.c
>> @@ -366,11 +366,13 @@ ProcArrayRemove(PGPROC *proc, TransactionId latestXid)
>> (arrayP->numProcs - index - 1) * sizeof(int));
>> arrayP->pgprocnos[arrayP->numProcs - 1] = -1; /* for debugging */
>> arrayP->numProcs--;
>> + ProcGlobal->is_snapshot_valid = false;
>> LWLockRelease(ProcArrayLock);
>> return;
>> }
>> }
>>
>> + ProcGlobal->is_snapshot_valid = false;
>> /* Oops */
>> LWLockRelease(ProcArrayLock);
>
> Why do we need to do anything here? And if we need to, why not in
;> ProcArrayAdd?
In ProcArrayRemove I can see ShmemVariableCache->latestCompletedXid is
set to latestXid which is going to change xmax in GetSnapshotData,
hence invalidated the snapshot there. ProcArrayAdd do not seem to be
affecting snapshotData. I have modified now to set
cached_snapshot_valid to false just below the statement
ShmemVariableCache->latestCompletedXid = latestXid only.
+if (TransactionIdIsValid(latestXid))
+{
+ Assert(TransactionIdIsValid(allPgXact[proc->pgprocno].xid));
+ /* Advance global latestCompletedXid while holding the lock */
+ if (TransactionIdPrecedes(ShmemVariableCache->latestCompletedXid,
+ latestXid))
+ ShmemVariableCache->latestCompletedXid = latestXid;
>> @@ -1552,6 +1557,8 @@ GetSnapshotData(Snapshot snapshot)
>> errmsg("out of memory")));
>> }
>>
>> + snapshot->takenDuringRecovery = RecoveryInProgress();
>> +
>> /*
>> * It is sufficient to get shared lock on ProcArrayLock, even if we are
>> * going to set MyPgXact->xmin.
>> @@ -1566,100 +1573,200 @@ GetSnapshotData(Snapshot snapshot)
>> /* initialize xmin calculation with xmax */
>> globalxmin = xmin = xmax;
>>
>> - snapshot->takenDuringRecovery = RecoveryInProgress();
>> -
>
> This movement of code seems fairly unrelated?
-- Yes not related, It was part of early POC patch so retained it as
it is. Now reverted those changes moved them back under the
ProcArrayLock
>> if (!snapshot->takenDuringRecovery)
>> {
>
> Do we really need to restrict this to !recovery snapshots? It'd be nicer
> if we could generalize it - I don't immediately see anything !recovery
> specific in the logic here.
Agree I will add one more patch on this to include standby(recovery
state) case also to unify all the cases where we can cache the
snapshot. Before let me see
>> - int *pgprocnos = arrayP->pgprocnos;
>> - int numProcs;
>> + if (ProcGlobal->is_snapshot_valid)
>> + {
>> + Snapshot csnap = &ProcGlobal->cached_snapshot;
>> + TransactionId *saved_xip;
>> + TransactionId *saved_subxip;
>>
>> - /*
>> - * Spin over procArray checking xid, xmin, and subxids. The goal is
>> - * to gather all active xids, find the lowest xmin, and try to record
>> - * subxids.
>> - */
>> - numProcs = arrayP->numProcs;
>> - for (index = 0; index < numProcs; index++)
>> + saved_xip = snapshot->xip;
>> + saved_subxip = snapshot->subxip;
>> +
>> + memcpy(snapshot, csnap, sizeof(SnapshotData));
>> +
>> + snapshot->xip = saved_xip;
>> + snapshot->subxip = saved_subxip;
>> +
>> + memcpy(snapshot->xip, csnap->xip,
>> + sizeof(TransactionId) * csnap->xcnt);
>> + memcpy(snapshot->subxip, csnap->subxip,
>> + sizeof(TransactionId) * csnap->subxcnt);
>> + globalxmin = ProcGlobal->cached_snapshot_globalxmin;
>> + xmin = csnap->xmin;
>> +
>> + count = csnap->xcnt;
>> + subcount = csnap->subxcnt;
>> + suboverflowed = csnap->suboverflowed;
>> +
>> + Assert(TransactionIdIsValid(globalxmin));
>> + Assert(TransactionIdIsValid(xmin));
>> + }
>
> Can we move this to a separate function? In fact, could you check how
> much effort it'd be to split cached, !recovery, recovery cases into
> three static inline helper functions? This is starting to be hard to
> read, the indentation added in this patch doesn't help... Consider doing
> recovery, !recovery cases in a preliminary separate patch.
In this patch, I have moved the code 2 functions one to cache the
snapshot data another to get the snapshot data from the cache. In the
next patch, I will try to unify these things with recovery (standby)
case. For recovery case, we are copying the xids from a simple xid
array KnownAssignedXids[], I am not completely sure whether caching
them bring similar performance benefits as above so I will also try to
get a perf report for same.
>
>> + * Let only one of the caller cache the computed snapshot, and
>> + * others can continue as before.
>> */
>> - if (!suboverflowed)
>> + if (!ProcGlobal->is_snapshot_valid &&
>> + LWLockConditionalAcquire(&ProcGlobal->CachedSnapshotLock,
>> + LW_EXCLUSIVE))
>> {
>
> I'd also move this to a helper function (the bit inside the lock).
Fixed as suggested.
>> +
>> + /*
>> + * The memory barrier has be to be placed here to ensure that
>> + * is_snapshot_valid is set only after snapshot is cached.
>> + */
>> + pg_write_barrier();
>> + ProcGlobal->is_snapshot_valid = true;
>> + LWLockRelease(&ProcGlobal->CachedSnapshotLock);
>
> LWLockRelease() is a full memory barrier, so this shouldn't be required.
Okay, Sorry for my understanding, Do you want me to set
ProcGlobal->is_snapshot_valid after
LWLockRelease(&ProcGlobal->CachedSnapshotLock)?
>
>> /*
>> diff --git a/src/include/storage/proc.h b/src/include/storage/proc.h
>> index 7dbaa81..7d06904 100644
>> --- a/src/include/storage/proc.h
>> +++ b/src/include/storage/proc.h
>> @@ -16,6 +16,7 @@
>>
>> #include "access/xlogdefs.h"
>> #include "lib/ilist.h"
>> +#include "utils/snapshot.h"
>> #include "storage/latch.h"
>> #include "storage/lock.h"
>> #include "storage/pg_sema.h"
>> @@ -253,6 +254,22 @@ typedef struct PROC_HDR
>> int startupProcPid;
>> /* Buffer id of the buffer that Startup process waits for pin on, or -1 */
>> int startupBufferPinWaitBufId;
>> +
>> + /*
>> + * In GetSnapshotData we can reuse the previously snapshot computed if no
>> + * new transaction has committed or rolledback. Thus saving good amount of
>> + * computation cycle under GetSnapshotData where we need to iterate
>> + * through procArray every time we try to get the current snapshot. Below
>> + * members help us to save the previously computed snapshot in global
>> + * shared memory and any process which want to get current snapshot can
>> + * directly copy from them if it is still valid.
>> + */
>> + SnapshotData cached_snapshot; /* Previously saved snapshot */
>> + volatile bool is_snapshot_valid; /* is above snapshot valid */
>> + TransactionId cached_snapshot_globalxmin; /* globalxmin when above
>
>
> I'd rename is_snapshot_valid to 'cached_snapshot_valid' or such, it's
> not clear from the name what it refers to.
-- Renamed to cached_snapshot_valid.
>
>> + LWLock CachedSnapshotLock; /* A try lock to make sure only one
>> + * process write to cached_snapshot */
>> } PROC_HDR;
>>
>
> Hm, I'd not add the lock to the struct, we normally don't do that for
> the "in core" lwlocks that don't exist in a "configurable" number like
> the buffer locks and such.
>
-- I am not really sure about this. Can you please help what exactly I
should be doing here to get this corrected? Is that I have to add it
to lwlocknames.txt as a new LWLock?
--
Thanks and Regards
Mithun C Y
EnterpriseDB: http://www.enterprisedb.com
Hi all please ignore this mail, this email is incomplete I have to add
more information and Sorry accidentally I pressed the send button
while replying.
On Tue, Aug 29, 2017 at 11:27 AM, Mithun Cy <mithun.cy@enterprisedb.com> wrote:
> Cache the SnapshotData for reuse:
> ===========================
> In one of our perf analysis using perf tool it showed GetSnapshotData
> takes a very high percentage of CPU cycles on readonly workload when
> there is very high number of concurrent connections >= 64.
>
> Machine : cthulhu 8 node machine.
> ----------------------------------------------
> Architecture: x86_64
> CPU op-mode(s): 32-bit, 64-bit
> Byte Order: Little Endian
> CPU(s): 128
> On-line CPU(s) list: 0-127
> Thread(s) per core: 2
> Core(s) per socket: 8
> Socket(s): 8
> NUMA node(s): 8
> Vendor ID: GenuineIntel
> CPU family: 6
> Model: 47
> Model name: Intel(R) Xeon(R) CPU E7- 8830 @ 2.13GHz
> Stepping: 2
> CPU MHz: 2128.000
> BogoMIPS: 4266.63
> Virtualization: VT-x
> L1d cache: 32K
> L1i cache: 32K
> L2 cache: 256K
> L3 cache: 24576K
> NUMA node0 CPU(s): 0,65-71,96-103
> NUMA node1 CPU(s): 72-79,104-111
> NUMA node2 CPU(s): 80-87,112-119
> NUMA node3 CPU(s): 88-95,120-127
> NUMA node4 CPU(s): 1-8,33-40
> NUMA node5 CPU(s): 9-16,41-48
> NUMA node6 CPU(s): 17-24,49-56
> NUMA node7 CPU(s): 25-32,57-64
>
> Perf CPU cycle 128 clients.
>
> On further analysis, it appears this mainly accounts to cache-misses
> happening while iterating through large proc array to compute the
> SnapshotData. Also, it seems mainly on read-only (read heavy) workload
> SnapshotData mostly remains same as no new(rarely a) transaction
> commits or rollbacks. Taking advantage of this we can save the
> previously computed SanspshotData in shared memory and in
> GetSnapshotData we can use the saved SnapshotData instead of computing
> same when it is still valid. A saved SnapsotData is valid until no
> transaction end.
>
> [Perf analysis Base]
>
> Samples: 421K of event 'cache-misses', Event count (approx.): 160069274
> Overhead Command Shared Object Symbol
> 18.63% postgres postgres [.] GetSnapshotData
> 11.98% postgres postgres [.] _bt_compare
> 10.20% postgres postgres [.] PinBuffer
> 8.63% postgres postgres [.] LWLockAttemptLock
> 6.50% postgres postgres [.] LWLockRelease
>
>
> [Perf analysis with Patch]
>
>
> Server configuration:
> ./postgres -c shared_buffers=8GB -N 300 -c min_wal_size=15GB -c
> max_wal_size=20GB -c checkpoint_timeout=900 -c
> maintenance_work_mem=1GB -c checkpoint_completion_target=0.9 -c
> wal_buffers=256MB &
>
> pgbench configuration:
> scale_factor = 300
> ./pgbench -c $threads -j $threads -T $time_for_reading -M prepared -S postgres
>
> The machine has 64 cores with this patch I can see server starts
> improvement after 64 clients. I have tested up to 256 clients. Which
> shows performance improvement nearly max 39% [1]. This is the best
> case for the patch where once computed snapshotData is reused further.
>
> The worst case seems to be small, quick write transactions with which
> frequently invalidate the cached SnapshotData before it is reused by
> any next GetSnapshotData call. As of now, I tested simple update
> tests: pgbench -M Prepared -N on the same machine with the above
> server configuration. I do not see much change in TPS numbers.
>
> All TPS are median of 3 runs
> Clients TPS-With Patch 05 TPS-Base %Diff
> 1 752.461117 755.186777 -0.3%
> 64 32171.296537 31202.153576 +3.1%
> 128 41059.660769 40061.929658 +2.49%
>
> I will do some profiling and find out why this case is not costing us
> some performance due to caching overhead.
>
>
> []
>
> On Thu, Aug 3, 2017 at 2:16 AM, Andres Freund <andres@anarazel.de> wrote:
>> Hi,
>>
>> I think this patch should have a "cover letter" explaining what it's
>> trying to achieve, how it does so and why it's safe/correct. I think
>> it'd also be good to try to show some of the worst cases of this patch
>> (i.e. where the caching only adds overhead, but never gets used), and
>> some of the best cases (where the cache gets used quite often, and
>> reduces contention significantly).
>>
>> I wonder if there's a way to avoid copying the snapshot into the cache
>> in situations where we're barely ever going to need it. But right now
>> the only way I can think of is to look at the length of the
>> ProcArrayLock wait queue and count the exclusive locks therein - which'd
>> be expensive and intrusive...
>>
>>
>> On 2017-08-02 15:56:21 +0530, Mithun Cy wrote:
>>> diff --git a/src/backend/storage/ipc/procarray.c b/src/backend/storage/ipc/procarray.c
>>> index a7e8cf2..4d7debe 100644
>>> --- a/src/backend/storage/ipc/procarray.c
>>> +++ b/src/backend/storage/ipc/procarray.c
>>> @@ -366,11 +366,13 @@ ProcArrayRemove(PGPROC *proc, TransactionId latestXid)
>>> (arrayP->numProcs - index - 1) * sizeof(int));
>>> arrayP->pgprocnos[arrayP->numProcs - 1] = -1; /* for debugging */
>>> arrayP->numProcs--;
>>> + ProcGlobal->is_snapshot_valid = false;
>>> LWLockRelease(ProcArrayLock);
>>> return;
>>> }
>>> }
>>>
>>> + ProcGlobal->is_snapshot_valid = false;
>>> /* Oops */
>>> LWLockRelease(ProcArrayLock);
>>
>> Why do we need to do anything here? And if we need to, why not in
> ;> ProcArrayAdd?
>
> In ProcArrayRemove I can see ShmemVariableCache->latestCompletedXid is
> set to latestXid which is going to change xmax in GetSnapshotData,
> hence invalidated the snapshot there. ProcArrayAdd do not seem to be
> affecting snapshotData. I have modified now to set
> cached_snapshot_valid to false just below the statement
> ShmemVariableCache->latestCompletedXid = latestXid only.
> +if (TransactionIdIsValid(latestXid))
> +{
> + Assert(TransactionIdIsValid(allPgXact[proc->pgprocno].xid));
> + /* Advance global latestCompletedXid while holding the lock */
> + if (TransactionIdPrecedes(ShmemVariableCache->latestCompletedXid,
> + latestXid))
> + ShmemVariableCache->latestCompletedXid = latestXid;
>
>
>
>>> @@ -1552,6 +1557,8 @@ GetSnapshotData(Snapshot snapshot)
>>> errmsg("out of memory")));
>>> }
>>>
>>> + snapshot->takenDuringRecovery = RecoveryInProgress();
>>> +
>>> /*
>>> * It is sufficient to get shared lock on ProcArrayLock, even if we are
>>> * going to set MyPgXact->xmin.
>>> @@ -1566,100 +1573,200 @@ GetSnapshotData(Snapshot snapshot)
>>> /* initialize xmin calculation with xmax */
>>> globalxmin = xmin = xmax;
>>>
>>> - snapshot->takenDuringRecovery = RecoveryInProgress();
>>> -
>>
>> This movement of code seems fairly unrelated?
>
> -- Yes not related, It was part of early POC patch so retained it as
> it is. Now reverted those changes moved them back under the
> ProcArrayLock
>
>>> if (!snapshot->takenDuringRecovery)
>>> {
>>
>> Do we really need to restrict this to !recovery snapshots? It'd be nicer
>> if we could generalize it - I don't immediately see anything !recovery
>> specific in the logic here.
>
> Agree I will add one more patch on this to include standby(recovery
> state) case also to unify all the cases where we can cache the
> snapshot. Before let me see
>
>
>>> - int *pgprocnos = arrayP->pgprocnos;
>>> - int numProcs;
>>> + if (ProcGlobal->is_snapshot_valid)
>>> + {
>>> + Snapshot csnap = &ProcGlobal->cached_snapshot;
>>> + TransactionId *saved_xip;
>>> + TransactionId *saved_subxip;
>>>
>>> - /*
>>> - * Spin over procArray checking xid, xmin, and subxids. The goal is
>>> - * to gather all active xids, find the lowest xmin, and try to record
>>> - * subxids.
>>> - */
>>> - numProcs = arrayP->numProcs;
>>> - for (index = 0; index < numProcs; index++)
>>> + saved_xip = snapshot->xip;
>>> + saved_subxip = snapshot->subxip;
>>> +
>>> + memcpy(snapshot, csnap, sizeof(SnapshotData));
>>> +
>>> + snapshot->xip = saved_xip;
>>> + snapshot->subxip = saved_subxip;
>>> +
>>> + memcpy(snapshot->xip, csnap->xip,
>>> + sizeof(TransactionId) * csnap->xcnt);
>>> + memcpy(snapshot->subxip, csnap->subxip,
>>> + sizeof(TransactionId) * csnap->subxcnt);
>>> + globalxmin = ProcGlobal->cached_snapshot_globalxmin;
>>> + xmin = csnap->xmin;
>>> +
>>> + count = csnap->xcnt;
>>> + subcount = csnap->subxcnt;
>>> + suboverflowed = csnap->suboverflowed;
>>> +
>>> + Assert(TransactionIdIsValid(globalxmin));
>>> + Assert(TransactionIdIsValid(xmin));
>>> + }
>>
>> Can we move this to a separate function? In fact, could you check how
>> much effort it'd be to split cached, !recovery, recovery cases into
>> three static inline helper functions? This is starting to be hard to
>> read, the indentation added in this patch doesn't help... Consider doing
>> recovery, !recovery cases in a preliminary separate patch.
>
> In this patch, I have moved the code 2 functions one to cache the
> snapshot data another to get the snapshot data from the cache. In the
> next patch, I will try to unify these things with recovery (standby)
> case. For recovery case, we are copying the xids from a simple xid
> array KnownAssignedXids[], I am not completely sure whether caching
> them bring similar performance benefits as above so I will also try to
> get a perf report for same.
>
>>
>>> + * Let only one of the caller cache the computed snapshot, and
>>> + * others can continue as before.
>>> */
>>> - if (!suboverflowed)
>>> + if (!ProcGlobal->is_snapshot_valid &&
>>> + LWLockConditionalAcquire(&ProcGlobal->CachedSnapshotLock,
>>> + LW_EXCLUSIVE))
>>> {
>>
>> I'd also move this to a helper function (the bit inside the lock).
>
> Fixed as suggested.
>
>>> +
>>> + /*
>>> + * The memory barrier has be to be placed here to ensure that
>>> + * is_snapshot_valid is set only after snapshot is cached.
>>> + */
>>> + pg_write_barrier();
>>> + ProcGlobal->is_snapshot_valid = true;
>>> + LWLockRelease(&ProcGlobal->CachedSnapshotLock);
>>
>> LWLockRelease() is a full memory barrier, so this shouldn't be required.
>
> Okay, Sorry for my understanding, Do you want me to set
> ProcGlobal->is_snapshot_valid after
> LWLockRelease(&ProcGlobal->CachedSnapshotLock)?
>
>>
>>> /*
>>> diff --git a/src/include/storage/proc.h b/src/include/storage/proc.h
>>> index 7dbaa81..7d06904 100644
>>> --- a/src/include/storage/proc.h
>>> +++ b/src/include/storage/proc.h
>>> @@ -16,6 +16,7 @@
>>>
>>> #include "access/xlogdefs.h"
>>> #include "lib/ilist.h"
>>> +#include "utils/snapshot.h"
>>> #include "storage/latch.h"
>>> #include "storage/lock.h"
>>> #include "storage/pg_sema.h"
>>> @@ -253,6 +254,22 @@ typedef struct PROC_HDR
>>> int startupProcPid;
>>> /* Buffer id of the buffer that Startup process waits for pin on, or -1 */
>>> int startupBufferPinWaitBufId;
>>> +
>>> + /*
>>> + * In GetSnapshotData we can reuse the previously snapshot computed if no
>>> + * new transaction has committed or rolledback. Thus saving good amount of
>>> + * computation cycle under GetSnapshotData where we need to iterate
>>> + * through procArray every time we try to get the current snapshot. Below
>>> + * members help us to save the previously computed snapshot in global
>>> + * shared memory and any process which want to get current snapshot can
>>> + * directly copy from them if it is still valid.
>>> + */
>>> + SnapshotData cached_snapshot; /* Previously saved snapshot */
>>> + volatile bool is_snapshot_valid; /* is above snapshot valid */
>>> + TransactionId cached_snapshot_globalxmin; /* globalxmin when above
>>
>>
>> I'd rename is_snapshot_valid to 'cached_snapshot_valid' or such, it's
>> not clear from the name what it refers to.
>
> -- Renamed to cached_snapshot_valid.
>
>>
>>> + LWLock CachedSnapshotLock; /* A try lock to make sure only one
>>> + * process write to cached_snapshot */
>>> } PROC_HDR;
>>>
>>
>> Hm, I'd not add the lock to the struct, we normally don't do that for
>> the "in core" lwlocks that don't exist in a "configurable" number like
>> the buffer locks and such.
>>
>
> -- I am not really sure about this. Can you please help what exactly I
> should be doing here to get this corrected? Is that I have to add it
> to lwlocknames.txt as a new LWLock?
>
> --
> Thanks and Regards
> Mithun C Y
> EnterpriseDB: http://www.enterprisedb.com
--
Thanks and Regards
Mithun C Y
EnterpriseDB: http://www.enterprisedb.com
On Thu, Aug 3, 2017 at 2:16 AM, Andres Freund <andres@anarazel.de> wrote:
>I think this patch should have a "cover letter" explaining what it's
> trying to achieve, how it does so and why it's safe/correct.
Cache the SnapshotData for reuse:
===========================
In one of our perf analysis using perf tool it showed GetSnapshotData
takes a very high percentage of CPU cycles on readonly workload when
there is very high number of concurrent connections >= 64.
Machine : cthulhu 8 node machine.
----------------------------------------------
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 8
NUMA node(s): 8
Vendor ID: GenuineIntel
CPU family: 6
Model: 47
Model name: Intel(R) Xeon(R) CPU E7- 8830 @ 2.13GHz
Stepping: 2
CPU MHz: 2128.000
BogoMIPS: 4266.63
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 24576K
NUMA node0 CPU(s): 0,65-71,96-103
NUMA node1 CPU(s): 72-79,104-111
NUMA node2 CPU(s): 80-87,112-119
NUMA node3 CPU(s): 88-95,120-127
NUMA node4 CPU(s): 1-8,33-40
NUMA node5 CPU(s): 9-16,41-48
NUMA node6 CPU(s): 17-24,49-56
NUMA node7 CPU(s): 25-32,57-64
On further analysis, it appears this mainly accounts to cache-misses
happening while iterating through large proc array to compute the
SnapshotData. Also, it seems mainly on read-only (read heavy) workload
SnapshotData mostly remains same as no new(rarely a) transaction
commits or rollbacks. Taking advantage of this we can save the
previously computed SanspshotData in shared memory and in
GetSnapshotData we can use the saved SnapshotData instead of computing
same when it is still valid. A saved SnapsotData is valid until no
open transaction end after it.
[Perf cache-misses analysis of Base for 128 pgbench readonly clients]
======================================================
Samples: 421K of event 'cache-misses', Event count (approx.): 160069274
Overhead Command Shared Object Symbol
18.63% postgres postgres [.] GetSnapshotData
11.98% postgres postgres [.] _bt_compare
10.20% postgres postgres [.] PinBuffer
8.63% postgres postgres [.] LWLockAttemptLock
6.50% postgres postgres [.] LWLockRelease
[Perf cache-misses analysis with Patch for 128 pgbench readonly clients]
========================================================
Samples: 357K of event 'cache-misses', Event count (approx.): 102380622
Overhead Command Shared Object Symbol
0.27% postgres postgres [.] GetSnapshotData
with the patch, it appears cache-misses events has reduced significantly.
Test Setting:
=========
Server configuration:
./postgres -c shared_buffers=8GB -N 300 -c min_wal_size=15GB -c
max_wal_size=20GB -c checkpoint_timeout=900 -c
maintenance_work_mem=1GB -c checkpoint_completion_target=0.9 -c
wal_buffers=256MB &
pgbench configuration:
scale_factor = 300
./pgbench -c $threads -j $threads -T $time_for_reading -M prepared -S postgres
The machine has 64 cores with this patch I can see server starts
improvement after 64 clients. I have tested up to 256 clients. Which
shows performance improvement nearly max 39% [1]. This is the best
case for the patch where once computed snapshotData is reused further.
The worst case seems to be small, quick write transactions which
frequently invalidate the cached SnapshotData before it is reused by
any next GetSnapshotData call. As of now, I tested simple update
tests: pgbench -M Prepared -N on the same machine with the above
server configuration. I do not see much change in TPS numbers.
All TPS are median of 3 runs
Clients TPS-With Patch 05 TPS-Base %Diff
1 752.461117 755.186777 -0.3%
64 32171.296537 31202.153576 +3.1%
128 41059.660769 40061.929658 +2.49%
I will do some profiling and find out why this case is not costing us
some performance due to caching overhead.
>> diff --git a/src/backend/storage/ipc/procarray.c b/src/backend/storage/ipc/procarray.c
>> index a7e8cf2..4d7debe 100644
>> --- a/src/backend/storage/ipc/procarray.c
>> +++ b/src/backend/storage/ipc/procarray.c
>> @@ -366,11 +366,13 @@ ProcArrayRemove(PGPROC *proc, TransactionId latestXid)
>> (arrayP->numProcs - index - 1) * sizeof(int));
>> arrayP->pgprocnos[arrayP->numProcs - 1] = -1; /* for debugging */
>> arrayP->numProcs--;
>> + ProcGlobal->is_snapshot_valid = false;
>> LWLockRelease(ProcArrayLock);
>> return;
>> }
>> }
>>
>> + ProcGlobal->is_snapshot_valid = false;
>> /* Oops */
>> LWLockRelease(ProcArrayLock);
>
> Why do we need to do anything here? And if we need to, why not in
> ProcArrayAdd?
-- In ProcArrayRemove I can see ShmemVariableCache->latestCompletedXid
is set to latestXid which is going to change xmax in GetSnapshotData,
hence invalidated the snapshot there. ProcArrayAdd do not seem to be
affecting snapshotData. I have modified now to set
cached_snapshot_valid to false just below the statement
ShmemVariableCache->latestCompletedXid = latestXid only.
+if (TransactionIdIsValid(latestXid))
+{
+ Assert(TransactionIdIsValid(allPgXact[proc->pgprocno].xid));
+ /* Advance global latestCompletedXid while holding the lock */
+ if (TransactionIdPrecedes(ShmemVariableCache->latestCompletedXid,
+ latestXid))
+ ShmemVariableCache->latestCompletedXid = latestXid;
>> @@ -1552,6 +1557,8 @@ GetSnapshotData(Snapshot snapshot)
>> globalxmin = xmin = xmax;
>>
>> - snapshot->takenDuringRecovery = RecoveryInProgress();
>> -
>
> This movement of code seems fairly unrelated?
-- Sorry not related, It was part of early POC patch so retained it as
it is. Now reverted those changes moved them back under the
ProcArrayLock
>> if (!snapshot->takenDuringRecovery)
>> {
>
> Do we really need to restrict this to !recovery snapshots? It'd be nicer
> if we could generalize it - I don't immediately see anything !recovery
> specific in the logic here.
-- Agree I will add one more patch on this to include standby(recovery
state) case also to unify all the cases where we can cache the
snapshot. In this patch, I have moved the code 2 functions one to
cache the snapshot data another to get the snapshot data from the
cache. In the next patch, I will try to unify these things with
recovery (standby) case. For recovery case, we are copying the xids
from a simple xid array KnownAssignedXids[], I am not completely sure
whether caching them bring similar performance benefits as above so I
will also try to get a perf report for same.
>
>> + * Let only one of the caller cache the computed snapshot, and
>> + * others can continue as before.
>> */
>> - if (!suboverflowed)
>> + if (!ProcGlobal->is_snapshot_valid &&
>> + LWLockConditionalAcquire(&ProcGlobal->CachedSnapshotLock,
>> + LW_EXCLUSIVE))
>> {
>
> I'd also move this to a helper function (the bit inside the lock).
-- Fixed as suggested.
>> +
>> + /*
>> + * The memory barrier has be to be placed here to ensure that
>> + * is_snapshot_valid is set only after snapshot is cached.
>> + */
>> + pg_write_barrier();
>> + ProcGlobal->is_snapshot_valid = true;
>> + LWLockRelease(&ProcGlobal->CachedSnapshotLock);
>
> LWLockRelease() is a full memory barrier, so this shouldn't be required.
-- Okay, Sorry for my understanding, do you want me to set
ProcGlobal->is_snapshot_valid after
LWLockRelease(&ProcGlobal->CachedSnapshotLock)?
>> + SnapshotData cached_snapshot; /* Previously saved snapshot */
>> + volatile bool is_snapshot_valid; /* is above snapshot valid */
>> + TransactionId cached_snapshot_globalxmin; /* globalxmin when above
>
>
> I'd rename is_snapshot_valid to 'cached_snapshot_valid' or such, it's
> not clear from the name what it refers to.
-- Fixed renamed as suggested.
>
>> + LWLock CachedSnapshotLock; /* A try lock to make sure only one
>> + * process write to cached_snapshot */
>> } PROC_HDR;
>>
>
> Hm, I'd not add the lock to the struct, we normally don't do that for
> the "in core" lwlocks that don't exist in a "configurable" number like
> the buffer locks and such.
>
-- I am not really sure about this. Can you please help what exactly I
should be doing here to get this corrected? Is that I have to add it
to lwlocknames.txt as a new LWLock?
--
Thanks and Regards
Mithun C Y
EnterpriseDB: http://www.enterprisedb.com
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Вложения
Hi, On 08/29/2017 05:04 AM, Mithun Cy wrote: > Test Setting: > ========= > Server configuration: > ./postgres -c shared_buffers=8GB -N 300 -c min_wal_size=15GB -c > max_wal_size=20GB -c checkpoint_timeout=900 -c > maintenance_work_mem=1GB -c checkpoint_completion_target=0.9 -c > wal_buffers=256MB & > > pgbench configuration: > scale_factor = 300 > ./pgbench -c $threads -j $threads -T $time_for_reading -M prepared -S postgres > > The machine has 64 cores with this patch I can see server starts > improvement after 64 clients. I have tested up to 256 clients. Which > shows performance improvement nearly max 39% [1]. This is the best > case for the patch where once computed snapshotData is reused further. > > The worst case seems to be small, quick write transactions which > frequently invalidate the cached SnapshotData before it is reused by > any next GetSnapshotData call. As of now, I tested simple update > tests: pgbench -M Prepared -N on the same machine with the above > server configuration. I do not see much change in TPS numbers. > > All TPS are median of 3 runs > Clients TPS-With Patch 05 TPS-Base %Diff > 1 752.461117 755.186777 -0.3% > 64 32171.296537 31202.153576 +3.1% > 128 41059.660769 40061.929658 +2.49% > > I will do some profiling and find out why this case is not costing us > some performance due to caching overhead. > I have done a run with this patch on a 2S/28C/56T/256Gb w/ 2 x RAID10 SSD machine. Both for -M prepared, and -M prepared -S I'm not seeing any improvements (1 to 375 clients); e.g. +-1%. Although the -M prepared -S case should improve, I'm not sure that the extra overhead in the -M prepared case is worth the added code complexity. Best regards, Jesper -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Wed, Sep 13, 2017 at 7:24 PM, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: > I have done a run with this patch on a 2S/28C/56T/256Gb w/ 2 x RAID10 SSD > machine. > > Both for -M prepared, and -M prepared -S I'm not seeing any improvements (1 > to 375 clients); e.g. +-1%. My test was done on an 8 socket NUMA intel machine, where I could clearly see improvements as posted before. Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 128 On-line CPU(s) list: 0-127 Thread(s) per core: 2 Core(s) per socket: 8 Socket(s): 8 NUMA node(s): 8 Vendor ID: GenuineIntel CPU family: 6 Model: 47 Model name: Intel(R) Xeon(R) CPU E7- 8830 @ 2.13GHz Stepping: 2 CPU MHz: 1064.000 BogoMIPS: 4266.62 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 24576K NUMA node0 CPU(s): 0,65-71,96-103 NUMA node1 CPU(s): 72-79,104-111 NUMA node2 CPU(s): 80-87,112-119 NUMA node3 CPU(s): 88-95,120-127 NUMA node4 CPU(s): 1-8,33-40 NUMA node5 CPU(s): 9-16,41-48 NUMA node6 CPU(s): 17-24,49-56 NUMA node7 CPU(s): 25-32,57-64 Let me recheck if the improvement is due to NUMA or cache sizes. Currently above machine is not available for me. It will take 2 more days for same. > Although the -M prepared -S case should improve, I'm not sure that the extra > overhead in the -M prepared case is worth the added code complexity. Each tpcb like (-M prepared) transaction in pgbench have 3 updates 1 insert and 1 select statements. There will be more GetSnapshotData calls than the end of the transaction (cached snapshot invalidation). So I think whatever we cache has a higher chance of getting used before it is invalidated in -M prepared. But on worst cases where we have quick write transaction which invalidates cached snapshot before it is reused becomes an overhead. As Andres has suggested previously I need a mechanism to identify and avoid caching for such scenarios. I do not have a right solution for this at present but one thing we can try is just before caching if we see an exclusive request in wait queue of ProcArrayLock we can avoid caching. -- Thanks and Regards Mithun C Y EnterpriseDB: http://www.enterprisedb.com -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Tue, Aug 29, 2017 at 1:57 AM, Mithun Cy <mithun.cy@enterprisedb.com> wrote: > All TPS are median of 3 runs > Clients TPS-With Patch 05 TPS-Base %Diff > 1 752.461117 755.186777 -0.3% > 64 32171.296537 31202.153576 +3.1% > 128 41059.660769 40061.929658 +2.49% > > I will do some profiling and find out why this case is not costing us > some performance due to caching overhead. So, this shows only a 2.49% improvement at 128 clients but in the earlier message you reported a 39% speedup at 256 clients. Is that really correct? There's basically no improvement up to threads = 2 x CPU cores, and then after that it starts to improve rapidly? What happens at intermediate points, like 160, 192, 224 clients? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Thu, Sep 21, 2017 at 3:15 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Aug 29, 2017 at 1:57 AM, Mithun Cy <mithun.cy@enterprisedb.com> wrote: >> All TPS are median of 3 runs >> Clients TPS-With Patch 05 TPS-Base %Diff >> 1 752.461117 755.186777 -0.3% >> 64 32171.296537 31202.153576 +3.1% >> 128 41059.660769 40061.929658 +2.49% >> >> I will do some profiling and find out why this case is not costing us >> some performance due to caching overhead. > > So, this shows only a 2.49% improvement at 128 clients but in the > earlier message you reported a 39% speedup at 256 clients. Is that > really correct? There's basically no improvement up to threads = 2 x > CPU cores, and then after that it starts to improve rapidly? What > happens at intermediate points, like 160, 192, 224 clients? It could be interesting to do multiple runs as well, and eliminate runs with upper and lower bound results while taking an average of the others. 2/3% is within the noise band of pgbench. -- Michael -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
> On Tue, Aug 29, 2017 at 1:57 AM, Mithun Cy <mithun.cy@enterprisedb.com> wrote:
>> All TPS are median of 3 runs
>> Clients TPS-With Patch 05 TPS-Base %Diff
>> 1 752.461117 755.186777 -0.3%
>> 64 32171.296537 31202.153576 +3.1%
>> 128 41059.660769 40061.929658 +2.49%
>>
>> I will do some profiling and find out why this case is not costing us
>> some performance due to caching overhead.
>
> So, this shows only a 2.49% improvement at 128 clients but in the
> earlier message you reported a 39% speedup at 256 clients. Is that
> really correct? There's basically no improvement up to threads = 2 x
> CPU cores, and then after that it starts to improve rapidly? What
> happens at intermediate points, like 160, 192, 224 clients?
I think there is some confusion above results is for pgbench simple update (-N) tests where cached snapshot gets invalidated, I have run this to check if there is any regression due to frequent cache invalidation and did not find any. The target test for the above patch is read-only case [1] where we can see the performance improvement as high as 39% (@256 threads) on Cthulhu(a 8 socket numa machine with 64 CPU cores). At 64 threads ( = CPU cores) we have 5% improvement and at clients 128 = (2 * CPU cores = hyperthreads) we have 17% improvement.
Clients BASE CODE With patch %Imp
64 452475.929144 476195.952736 5.2422730281
128 556207.727932 653256.029012 17.4482115595
256 494336.282804 691614.000463 39.9075941867
[1] cache_the_snapshot_
Thanks and Regards
Mithun C Y
EnterpriseDB: http://www.enterprisedb.com
On Wed, Sep 20, 2017 at 9:46 PM, Mithun Cy <mithun.cy@enterprisedb.com> wrote: > I think there is some confusion above results is for pgbench simple update > (-N) tests where cached snapshot gets invalidated, I have run this to check > if there is any regression due to frequent cache invalidation and did not > find any. The target test for the above patch is read-only case [1] where we > can see the performance improvement as high as 39% (@256 threads) on > Cthulhu(a 8 socket numa machine with 64 CPU cores). At 64 threads ( = CPU > cores) we have 5% improvement and at clients 128 = (2 * CPU cores = > hyperthreads) we have 17% improvement. > > Clients BASE CODE With patch %Imp > > 64 452475.929144 476195.952736 5.2422730281 > > 128 556207.727932 653256.029012 17.4482115595 > > 256 494336.282804 691614.000463 39.9075941867 Oh, you're right. I was confused. But now I'm confused about something else: if you're seeing a clear gain at higher-client counts, why is Jesper Pederson not seeing the same thing? Do you have results for a 2-socket machine? Maybe this only helps with >2 sockets. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Thu, Sep 21, 2017 at 7:25 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Sep 20, 2017 at 9:46 PM, Mithun Cy <mithun.cy@enterprisedb.com> wrote: >> I think there is some confusion above results is for pgbench simple update >> (-N) tests where cached snapshot gets invalidated, I have run this to check >> if there is any regression due to frequent cache invalidation and did not >> find any. The target test for the above patch is read-only case [1] where we >> can see the performance improvement as high as 39% (@256 threads) on >> Cthulhu(a 8 socket numa machine with 64 CPU cores). At 64 threads ( = CPU >> cores) we have 5% improvement and at clients 128 = (2 * CPU cores = >> hyperthreads) we have 17% improvement. >> >> Clients BASE CODE With patch %Imp >> >> 64 452475.929144 476195.952736 5.2422730281 >> >> 128 556207.727932 653256.029012 17.4482115595 >> >> 256 494336.282804 691614.000463 39.9075941867 > > Oh, you're right. I was confused. > > But now I'm confused about something else: if you're seeing a clear > gain at higher-client counts, why is Jesper Pederson not seeing the > same thing? Do you have results for a 2-socket machine? Maybe this > only helps with >2 sockets. My current tests show on scylla (2 socket machine with 28 CPU core) I do not see any improvement at all as similar to Jesper. But same tests on power2 (4 sockets) and Cthulhu(8 socket machine) we can see improvements. -- Thanks and Regards Mithun C Y EnterpriseDB: http://www.enterprisedb.com -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Wed, Sep 20, 2017 at 10:04 PM, Mithun Cy <mithun.cy@enterprisedb.com> wrote: > My current tests show on scylla (2 socket machine with 28 CPU core) I > do not see any improvement at all as similar to Jesper. But same tests > on power2 (4 sockets) and Cthulhu(8 socket machine) we can see > improvements. OK, makes sense. So for whatever reason, this appears to be something that will only help users with >2 sockets. But that's not necessarily a bad thing. The small regression at 1 client is a bit concerning though. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On September 20, 2017 7:22:00 PM PDT, Robert Haas <robertmhaas@gmail.com> wrote: >On Wed, Sep 20, 2017 at 10:04 PM, Mithun Cy ><mithun.cy@enterprisedb.com> wrote: >> My current tests show on scylla (2 socket machine with 28 CPU core) I >> do not see any improvement at all as similar to Jesper. But same >tests >> on power2 (4 sockets) and Cthulhu(8 socket machine) we can see >> improvements. > >OK, makes sense. So for whatever reason, this appears to be something >that will only help users with >2 sockets. But that's not necessarily >a bad thing. Wonder how much of that is microarchitecture, how much number of sockets. Andres -- Sent from my Android device with K-9 Mail. Please excuse my brevity. -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Wed, Sep 20, 2017 at 10:32 PM, Andres Freund <andres@anarazel.de> wrote: > Wonder how much of that is microarchitecture, how much number of sockets. I don't know. How would we tell? power2 is a 4-socket POWER box, and cthulhu is an 8-socket x64 box, so it's not like they are the same sort of thing. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers