Обсуждение: Hard link / rsync backup strategy successful
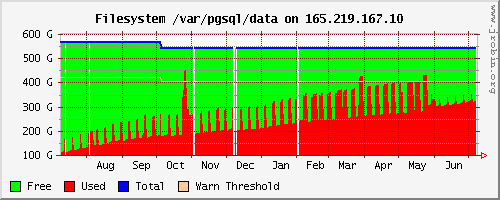
As a follow-up to this: http://archives.postgresql.org/pgsql-admin/2009-03/msg00233.php The strategy described in the above post has worked out very well for us. If you do backups across a relatively slow link, and significant portions of your database remain relatively stable, you might want to consider this approach. Attached is a graph which shows the space used on the volume containing the database and its backups for a county with fast growth in database size due to aggressive document scanning. Notice the weekly spikes -- these represent a new cpio|gzip PITR base backup copied to the local volume. A crontab script would check for completion of its copy to another local server and to the remote server; when both were successful, the *prior* base backup and the WAL files needed for it would be deleted. You can see how the spikes get wider as the portion of the week required to get the backup across the WAN expanded with size. After we implemented the new techniques at the end of May, there is a slightly higher base, because of a full, non-compressed copy of the live database, but the backup times, and the data which needs to be moved both are drastically reduced. (The shorter, narrower spikes give a pretty good idea of the improvement we've seen for this county.) One minor point -- we found that to minimize traffic, it was important to freeze tuples pretty aggressively; otherwise the large insert-only tables sent the data across twice, nearly doubling the bandwidth required for backups. -Kevin
Вложения
{kind=link}
Kevin Grittner wrote: > As a follow-up to this: > > http://archives.postgresql.org/pgsql-admin/2009-03/msg00233.php > > The strategy described in the above post has worked out very well for > us. If you do backups across a relatively slow link, and significant > portions of your database remain relatively stable, you might want to > consider this approach. Thanks, this is good material. I keep thinking it should be in the FAQ somehow, or maybe on its own full Wiki article. -- Alvaro Herrera http://www.CommandPrompt.com/ PostgreSQL Replication, Consulting, Custom Development, 24x7 support
Kevin, Kevin Grittner wrote: > As a follow-up to this: > > http://archives.postgresql.org/pgsql-admin/2009-03/msg00233.php > I just read this post. What exactly does doing the hard link buy you here? Since it's just another inode pointer to the same file, I fail to see what the purpose of it is... For example, take a look at the code below : chander@bender:~$ echo "apple" > a chander@bender:~$ cat a apple chander@bender:~$ cp -l a b chander@bender:~$ cat b apple chander@bender:~$ echo "pear" > a chander@bender:~$ cat b pear Just curious... It seems that the method described in your email (creating a backup using 'cp -l' and then using rsync) would "break" your old backup (the hard link copy) since some of the files in it would be modified, but it would be missing the "new" files that were added to the backup. Essentially making your "old" backup an incomplete backup of your new cluster. In essence, a "hard link" isn't a copy of any sort, it's just a pointer to the same inode, which is the exact same data... Perhaps there is something that I am missing here? Thanks -- Chander Ganesan Open Technology Group, Inc. One Copley Parkway, Suite 210 Morrisville, NC 27560 919-463-0999/877-258-8987 http://www.otg-nc.com Expert PostgreSQL, PostGIS, and other Open Source training delivered world-wide.
I'm in agreement. That is a recipe for a failed recovery.
If you must use some file system / volume trickery to get an initial backup then I would suggest looking into LVM or some similar volume manager. For beginners, take a look at the link below.
http://tldp.org/HOWTO/LVM-HOWTO/snapshots_backup.html
The technique does work however if you're using the PostgreSQL PITR backup method, which is what I am guessing at, then you're only adding overhead and complexity to the process.
Greg
If you must use some file system / volume trickery to get an initial backup then I would suggest looking into LVM or some similar volume manager. For beginners, take a look at the link below.
http://tldp.org/HOWTO/LVM-HOWTO/snapshots_backup.html
The technique does work however if you're using the PostgreSQL PITR backup method, which is what I am guessing at, then you're only adding overhead and complexity to the process.
Greg
On Tue, Jul 14, 2009 at 3:03 PM, Chander Ganesan <chander@otg-nc.com> wrote:
Kevin,
Kevin Grittner wrote:As a follow-up to this:I just read this post. What exactly does doing the hard link buy you here? Since it's just another inode pointer to the same file, I fail to see what the purpose of it is... For example, take a look at the code below :
http://archives.postgresql.org/pgsql-admin/2009-03/msg00233.php
chander@bender:~$ echo "apple" > a
chander@bender:~$ cat a
apple
chander@bender:~$ cp -l a b
chander@bender:~$ cat b
apple
chander@bender:~$ echo "pear" > a
chander@bender:~$ cat b
pear
Just curious... It seems that the method described in your email (creating a backup using 'cp -l' and then using rsync) would "break" your old backup (the hard link copy) since some of the files in it would be modified, but it would be missing the "new" files that were added to the backup. Essentially making your "old" backup an incomplete backup of your new cluster.
In essence, a "hard link" isn't a copy of any sort, it's just a pointer to the same inode, which is the exact same data...
Perhaps there is something that I am missing here?
Thanks
--
Chander Ganesan
Open Technology Group, Inc.
One Copley Parkway, Suite 210
Morrisville, NC 27560
919-463-0999/877-258-8987
http://www.otg-nc.com
Expert PostgreSQL, PostGIS, and other Open Source training delivered world-wide.
--
Sent via pgsql-admin mailing list (pgsql-admin@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-admin
Chander Ganesan <chander@otg-nc.com> wrote: > What exactly does doing the hard link buy you here? For some of our largest databases, 90% of the space is in files which don't change from one week to the next. If you read through the steps carefully, you will see that these files (and only these files) are hard linked from one backup to the next. This results in a backup taking only 10% of the space it otherwise would. > Just curious... It seems that the method described in your email > (creating a backup using 'cp -l' and then using rsync) would > "break" your old backup (the hard link copy) since some of the files > in it would be modified, You have apparently missed the fact that rsync (unless you go out of your way to defeat this) will copy to a temporary filename, and then mv the new file in place of the old. This doesn't modify the old file; it unlinks the copy you are replacing, leaving any other directory entries which point at the old data unaffected. > but it would be missing the "new" files that were added to > the backup. Not at all. Re-read the rsync docs. > In essence, a "hard link" isn't a copy of any sort, it's just a > pointer to the same inode, which is the exact same data... Which is exactly what we want -- for those files which didn't change from one backup to the next. > Perhaps there is something that I am missing here? The main thing seems to be that (unless you use a switch to tell it otherwise) rsync never modifies a file at the target location. It creates new files and moves them to the correct name, and if you use the --delete switch it unlinks files not present on the source; but it *never* modifies an existing file on the target. The prior backup, from which we cp -l, will never be affected. -Kevin
Greg Spiegelberg <gspiegelberg@gmail.com> wrote: > That is a recipe for a failed recovery. Our warm standbys seem to disagree with you. > If you must use some file system / volume trickery to get an initial > backup We don't. Read it again. It is *subsequent* backups where we do the trickery, off of an earlier backup. > The technique does work however if you're using the PostgreSQL PITR > backup method, which is what I am guessing at, then you're only > adding overhead and complexity to the process. Disk space for our largest backups is down by 90%, WAN usage by about 99%. The complexity is about a wash compared with what we were doing before. We have scripts to automatically do the backups, use them to restart warm standbys, detect a successful warm standby restart from a new backup and delete any now-expendable old backups, and copy monthly archival copies of backups to archival storage. All with automatic proper handling of the related WAL files. Compared to some of that, this was easy. -Kevin
Kevin, Kevin Grittner wrote: > You have apparently missed the fact that rsync (unless you go out of > your way to defeat this) will copy to a temporary filename, and then > mv the new file in place of the old. This doesn't modify the old > file; it unlinks the copy you are replacing, leaving any other > directory entries which point at the old data unaffected. > Ahh, there's the subtlety that I missed. :-) I figured I was missing something, since at face value it seems like your hard link strategy is doomed to fail. Thanks for the clarification :-) That's a pretty nifty mechanism to retain your old database versions. I suppose you just have to be careful to make a copy of the cluster before trying to start it up (lest you break an older or newer backup). -- Chander Ganesan Open Technology Group, Inc. One Copley Parkway, Suite 210 Morrisville, NC 27560 919-463-0999/877-258-8987 http://www.otg-nc.com
Chander Ganesan <chander@otg-nc.com> wrote: > I suppose you just have to be careful to make a copy of the cluster > before trying to start it up (lest you break an older or newer > backup). Yeah, you don't want to get confused and have the warm standby using a hard link to a backup. The trick is to *only* use the cp -l from one backup copy to another, and then only update the new copy with rsync. If you keep that straight, it's not too hard.... -Kevin