Re: Automatically sizing the IO worker pool
| От | Dmitry Dolgov |
|---|---|
| Тема | Re: Automatically sizing the IO worker pool |
| Дата | |
| Msg-id | pdrbpbvhscwckb6nqkfgoo7o63nnmeq7taaazgfi3bk627gb6p@rzcauoqabb3k обсуждение исходный текст |
| Ответ на | Re: Automatically sizing the IO worker pool (Thomas Munro <thomas.munro@gmail.com>) |
| Ответы |
Re: Automatically sizing the IO worker pool
|
| Список | pgsql-hackers |
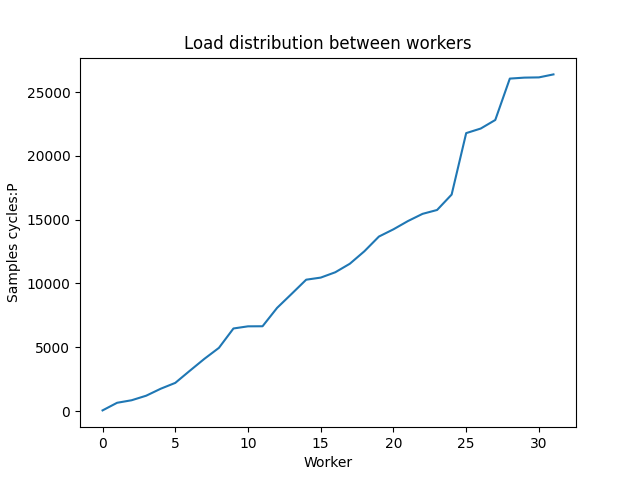
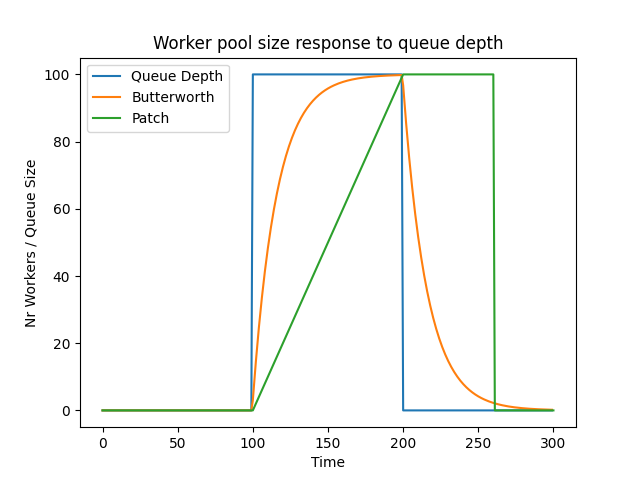
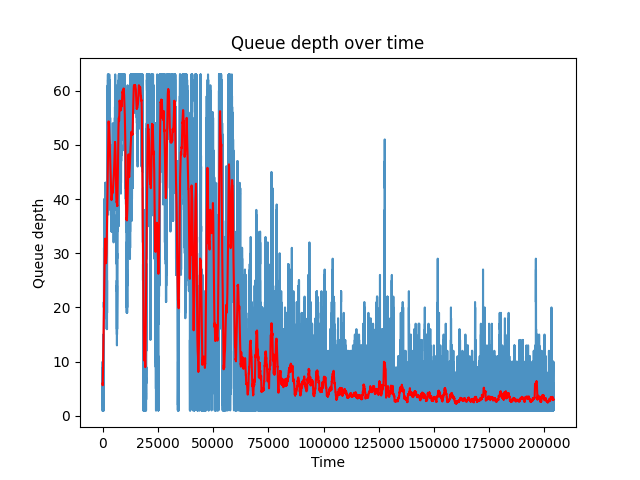
> On Sat, Jul 12, 2025 at 05:08:29PM +1200, Thomas Munro wrote: > On Wed, May 28, 2025 at 5:55 AM Dmitry Dolgov <9erthalion6@gmail.com> wrote: > > I probably had to start with a statement that I find the current > > approach reasonable, and I'm only curious if there is more to get > > out of it. I haven't benchmarked the patch yet (plan getting to it > > when I'll get back), and can imagine practical considerations > > significantly impacting any potential solution. > > Here's a rebase. Thanks. I was experimenting with this approach, and realized there isn't much metrics exposed about workers and the IO queue so far. Since the worker pool growth is based on the queue size and workers try to share the load uniformly, it makes to have a system view to show those numbers, let's say a system view for worker handles and a function to get the current queue size? E.g. workers load in my testing was quite varying, see "Load distribution between workers" graph, which shows a quick profiling run including currently running io workers. Regarding the worker pool growth approach, it sounds reasonable to me. With static number of workers one needs to somehow find a number suitable for all types of workload, where with this patch one needs only to fiddle with the launch interval to handle possible spikes. It would be interesting to investigate, how this approach would react to different dynamics of the queue size. I've plotted one "spike" scenario in the "Worker pool size response to queue depth", where there is a pretty artificial burst of IO, making the queue size look like a step function. If I understand the patch implementation correctly, it would respond linearly over time (green line), one could also think about applying a first order butterworth low pass filter to respond quicker but still smooth (orange line). But in reality the queue size would be of course much more volatile even on stable workloads, like in "Queue depth over time" (one can see general oscillation, as well as different modes, e.g. where data is in the page cache vs where it isn't). Event more, there is a feedback where increasing number of workers would accelerate queue size decrease -- based on [1] the system utilization for M/M/k depends on the arrival rate, processing rate and number of processors, where pretty intuitively more processors reduce utilization. But alas, as you've mentioned this result exists for Poisson distribution only. Btw, I assume something similar could be done to other methods as well? I'm not up to date on io uring, can one change the ring depth on the fly? As a side note, I was trying to experiment with this patch using dm-mapper's delay feature to introduce an arbitrary large io latency and see how the io queue is growing. But strangely enough, even though the pure io latency was high, the queue growth was smaller than e.g. on a real hardware under the same conditions without any artificial delay. Is there anything obvious I'm missing that could have explained that? [1]: Harchol-Balter, Mor. Performance modeling and design of computer systems: queueing theory in action. Cambridge University Press, 2013.
Вложения
В списке pgsql-hackers по дате отправления: