Hi all,
So I did some more experiments on this patch.
* I fixed the bug with duplicate tuples I mentioned in the previous
letter. Indeed, the oldestActiveXid could be advanced past the
transaction's xid before it set the clog status. This happened because
the oldestActiveXid is calculated based on the CSN log contents, and we
wrote to CSN log before writing to clog. The fix is to write to clog
before CSN log (TransactionIdAsyncCommitTree)
* We can remove the exclusive locking on CSNLogControlLock when setting
the CSN for a transaction (CSNLogSetPageStatus). When we assign a CSN to
a transaction and its children, the atomicity is guaranteed by using an
intermediate state (COMMITSEQNO_COMMITTING), so it doesn't matter if
this function is not atomic in itself. The shared lock should suffice here.
* On throughputs of about 100k TPS, we allocate ~1k CSN log pages per
second. This is done with exclusive locking on CSN control lock, and
noticeably increases contention. To alleviate this, I allocate new pages
in batches (ExtendCSNLOG).
* When advancing oldestActiveXid, we scan CSN log to find an xid that is
still in progress. To do that, we increment the xid and query its CSN
using the high level function, acquiring and releasing the lock and
looking up the log page for each xid. I wrote some code to acquire the
lock only once and then scan the pages (CSNLogSetPageStatus).
* On bigger buffers the linear page lookup code that the SLRU uses now
becomes slow. I added a shared dynahash table to speed up this lookup.
* I merged in recent changes from master (up to 7e1fb4). Unfortunately I
didn't have enough time to fix the logical replication and snapshot
import, so now it's completely broken.
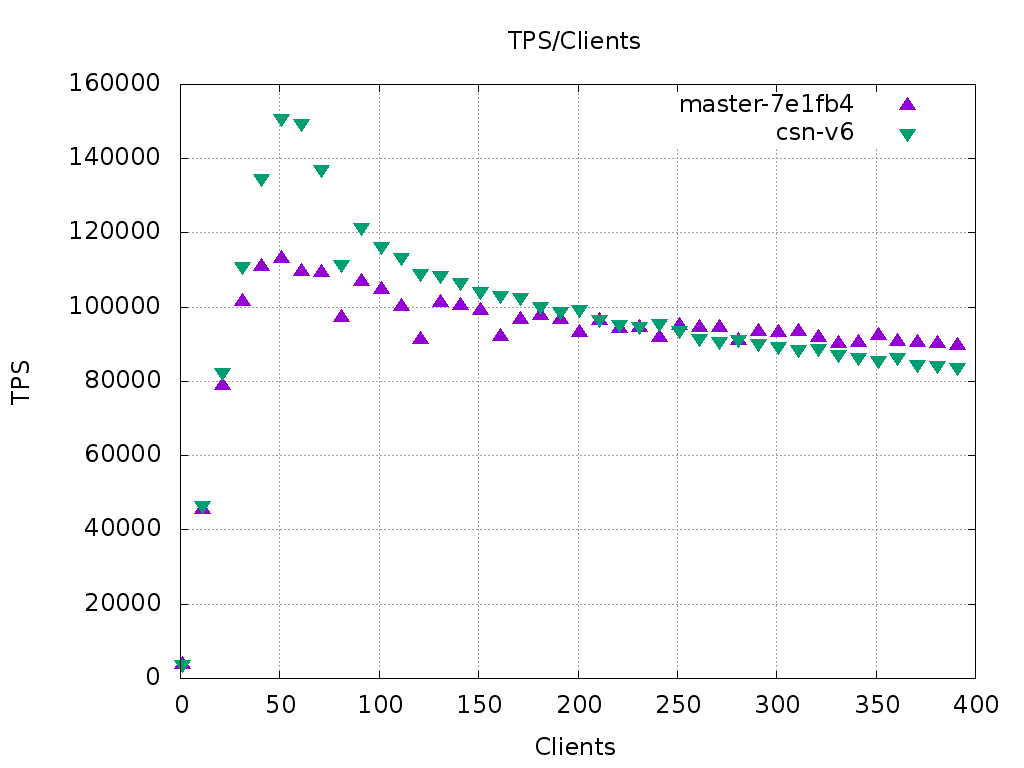
I ran some pgbench with these tweaks (tpcb-like, 72 cores, scale 500).
The throughput is good on lower number of clients (on 50 clients it's
35% higher than on the master), but then it degrades steadily. After 250
clients it's already lower than master; see the attached graph. In perf
reports the CSN-related things have almost vanished, and I see lots of
time spent working with clog. This is probably the situation where by
making some parts faster, the contention in other parts becomes worse
and overall we have a performance loss. Hilariously, at some point I saw
a big performance increase after adding some debug printfs. I wanted to
try some things with the clog next, but for now I'm out of time.
The new version of the patch is attached. Last time I apparently diff'ed
it the other way around, now it should apply fine.
--
Alexander Kuzmenkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers