Re: WIP: WAL prefetch (another approach)
| От | Tomas Vondra |
|---|---|
| Тема | Re: WIP: WAL prefetch (another approach) |
| Дата | |
| Msg-id | a6915477-c675-7959-28b2-5b8fa60f44fc@enterprisedb.com обсуждение |
| Ответ на | Re: WIP: WAL prefetch (another approach) (Thomas Munro <thomas.munro@gmail.com>) |
| Ответы |
Re: WIP: WAL prefetch (another approach)
|
| Список | pgsql-hackers |
Hi,
It's great you posted a new version of this patch, so I took a look a
brief look at it. The code seems in pretty good shape, I haven't found
any real issues - just two minor comments:
This seems a bit strange:
#define DEFAULT_DECODE_BUFFER_SIZE 0x10000
Why not to define this as a simple decimal value? Is there something
special about this particular value, or is it arbitrary? I guess it's
simply the minimum for wal_decode_buffer_size GUC, but why not to use
the GUC for all places decoding WAL?
FWIW I don't think we include updates to typedefs.list in patches.
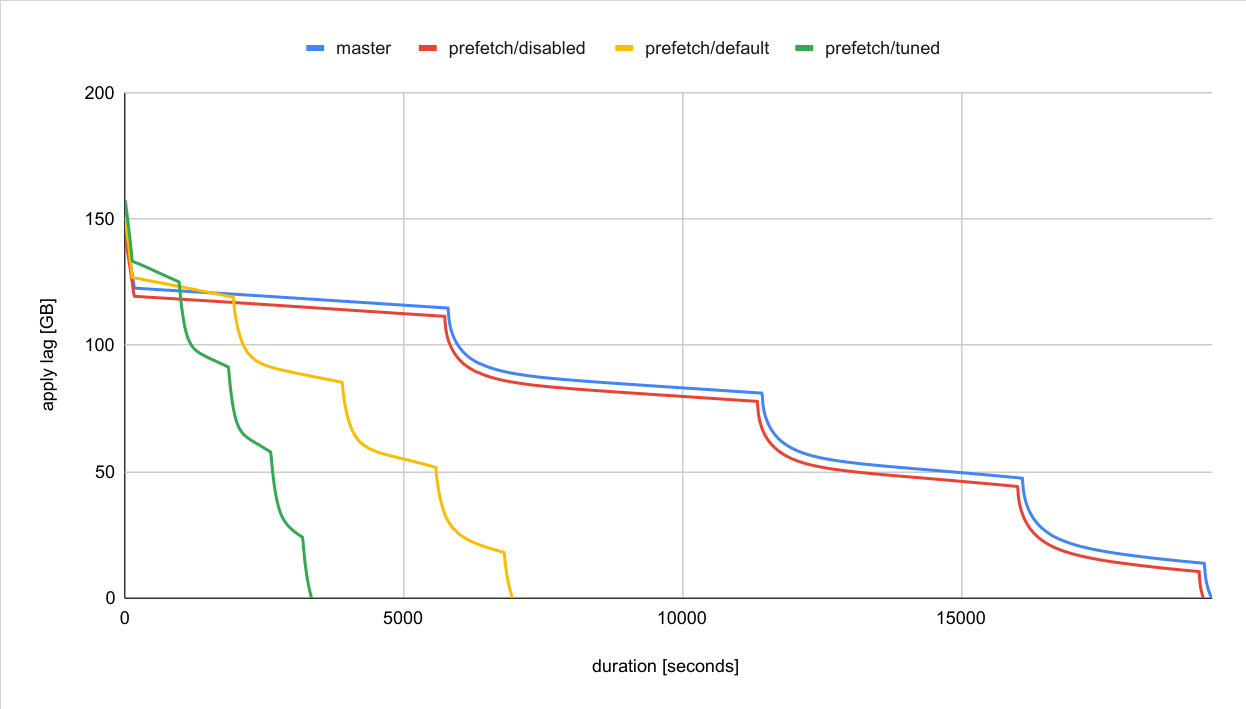
I also repeated the benchmarks I did at the beginning of the year [1].
Attached is a chart with four different configurations:
1) master (f79962d826)
2) patched (with prefetching disabled)
3) patched (with default configuration)
4) patched (with I/O concurrency 256 and 2MB decode buffer)
For all configs the shared buffers were set to 64GB, checkpoints every
20 minutes, etc.
The results are pretty good / similar to previous results. Replaying the
1h worth of work on a smaller machine takes ~5:30h without prefetching
(master or with prefetching disabled). With prefetching enabled this
drops to ~2h (default config) and ~1h (with tuning).
regards
[1]
https://www.postgresql.org/message-id/c5d52837-6256-0556-ac8c-d6d3d558820a%40enterprisedb.com
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Вложения
В списке pgsql-hackers по дате отправления: