Re: Slow standby snapshot
| От | Michail Nikolaev |
|---|---|
| Тема | Re: Slow standby snapshot |
| Дата | |
| Msg-id | CANtu0oiQOmRBZA6UFSA_PVGEMCaeWhDV7JBqySU7dAPZRgUo3A@mail.gmail.com обсуждение исходный текст |
| Ответ на | Re: Slow standby snapshot (Andres Freund <andres@anarazel.de>) |
| Ответы |
Re: Slow standby snapshot
Re: Slow standby snapshot |
| Список | pgsql-hackers |
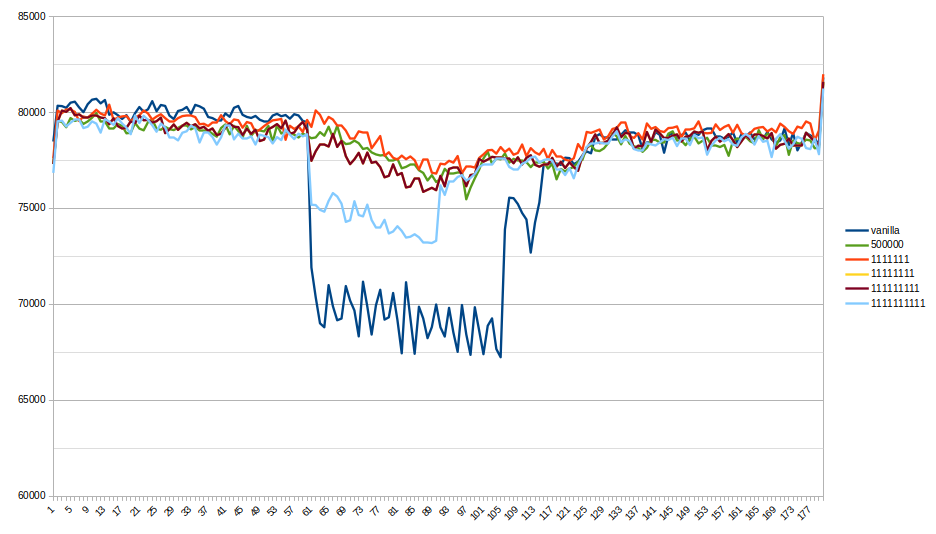
Hello. On Wed, Nov 16, 2022 at 3:44 AM Andres Freund <andres@anarazel.de> wrote: > Approach 1: > We could have an atomic variable in ProcArrayStruct that counts the amount of > wasted effort and have processes update it whenever they've wasted a > meaningful amount of effort. Something like counting the skipped elements in > KnownAssignedXidsGetAndSetXmin in a function local static variable and > updating the shared counter whenever that reaches I made the WIP patch for that approach and some initial tests. It seems like it works pretty well. At least it is better than previous ways for standbys without high read only load. Both patch and graph in attachments. Strange numbers is a limit of wasted work to perform compression. I have used the same (1) testing script and configuration as before (two 16-CPU machines, long transaction on primary at 60th second, simple-update and select-only for pgbench). If such approach looks committable - I could do more careful performance testing to find the best value for WASTED_SNAPSHOT_WORK_LIMIT_TO_COMPRESS. [1]: https://gist.github.com/michail-nikolaev/e1dfc70bdd7cfd1b902523dbb3db2f28 -- Michail Nikolaev
Вложения
В списке pgsql-hackers по дате отправления: