I've started to review this, and I've got to say that I really disagree with this choice:
+ * If there are INCLUDE columns, they are stored after a key value, each + * starting from its own typalign boundary. Unlike IndexTuple, first INCLUDE + * value does not need to start from MAXALIGN boundary, so SPGiST uses private + * routines to access them.
This seems to require far more new code than it could possibly be worth, because most of the time anything you could save here is just going to disappear into end-of-tuple alignment space anyway -- recall that the overall index tuple length is going to be MAXALIGN'd no matter what. I think you should yank this out and try to rely on standard tuple construction/deconstruction code instead.
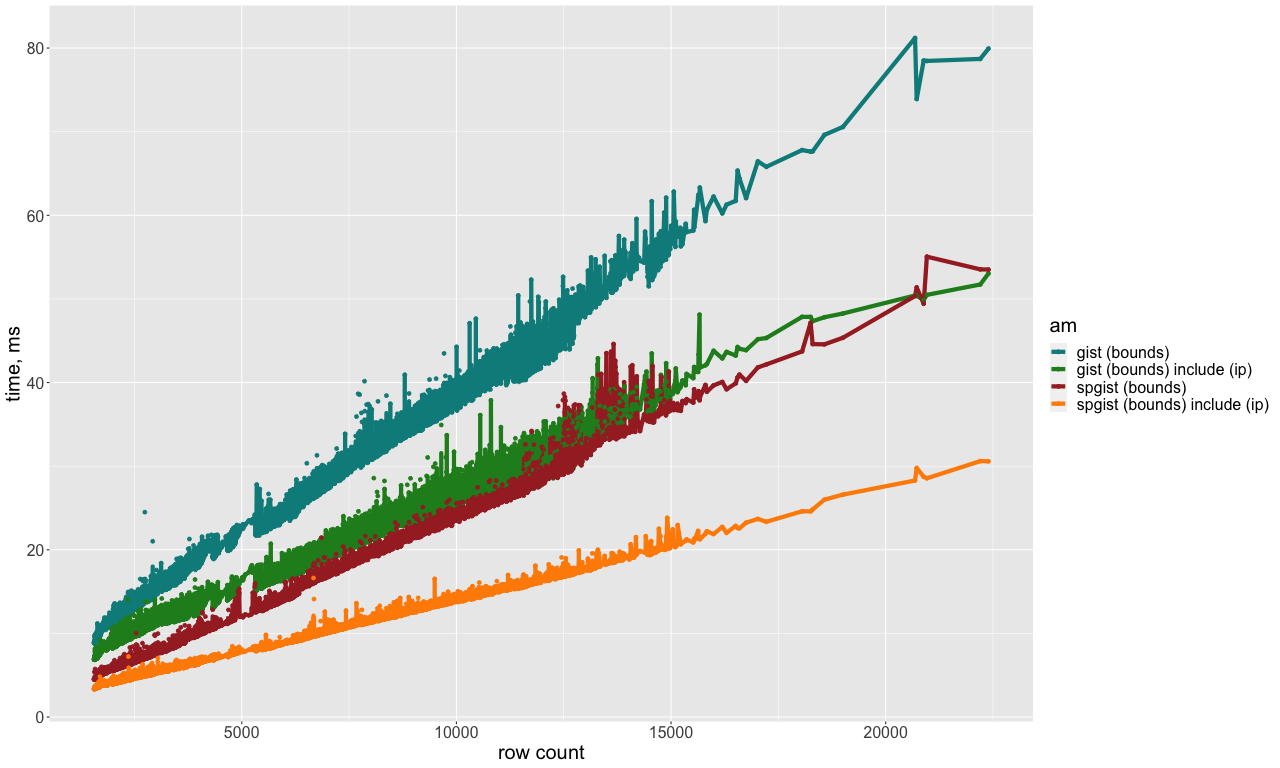
I'd say that much of the SELECT performance gain of SP-GiST over GiST is due to its lightweight pages, each containing more tuples so we can have less page fetches. And this is the main goal of having lightweight tuples.
PFA my performance measurements for box+cidr selects, with gist and spgist indexes built on box key-column and cidr (optionally) include column.
The way that seems acceptable to me is to add (optional) nulls mask into the end of existing style SpGistLeafTuple header and use indextuple routines to attach attributes after it. In this case, we can reduce the amount of code at the cost of adding one extra MAXALIGN size to the overall tuple size on 32-bit arch as now tuple header size of 12 bit already fits 3 MAXALIGNS (on 64 bit the header now is shorter than 2 maxaligns (12 bytes of 16) and nulls mask will be free of cost). If you mean this I try to make changes soon. What do you think of it?
I also find it unacceptable that you stuck a tuple descriptor pointer into the rd_amcache structure. The relcache only supports that being a flat blob of memory. I see that you tried to hack around that by having spgGetCache reconstruct a new tupdesc every time through, but (a) that's actually worse than having no cache at all, and (b) spgGetCache doesn't really know much about the longevity of the memory context it's called in. This could easily lead to dangling tuple pointers, serious memory bloat from repeated tupdesc construction, or quite possibly both. Safer would be to build the tupdesc during initSpGistState(), or maybe just make it on-demand. In view of the previous point, I'm also wondering if there's any way to get the relcache's regular rd_att tupdesc to be useful here, so we don't have to build one during scans at all.
(I wondered for a bit about whether you could keep a long-lived private tupdesc in the relcache's rd_indexcxt context. But it looks like relcache.c sometimes resets rd_amcache without also clearing the rd_indexcxt, so that would probably lead to leakage.)