Dear Tom,
Thank you for replying to my email.
On Mon, Jul 4, 2022 at 6:28 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
> I'm not real thrilled with trying to throw hashtables at the problem,
> though. As David noted, they'd be counterproductive for simple
> queries.
As you said, my approach that utilizes hash tables has some overheads,
leading to degradation in query planning time.
I tested the degradation by a brief experiment. In this experiment, I
used a simple query shown below.
===
SELECT students.name, gpas.gpa AS gpa, sum(scores.score) AS total_score
FROM students, scores, gpas
WHERE students.id = scores.student_id AND students.id = gpas.student_id
GROUP BY students.id, gpas.student_id;
===
Here, students, scores, and gpas tables have no partitions, i.e., they
are regular tables. Therefore, my techniques do not work for this
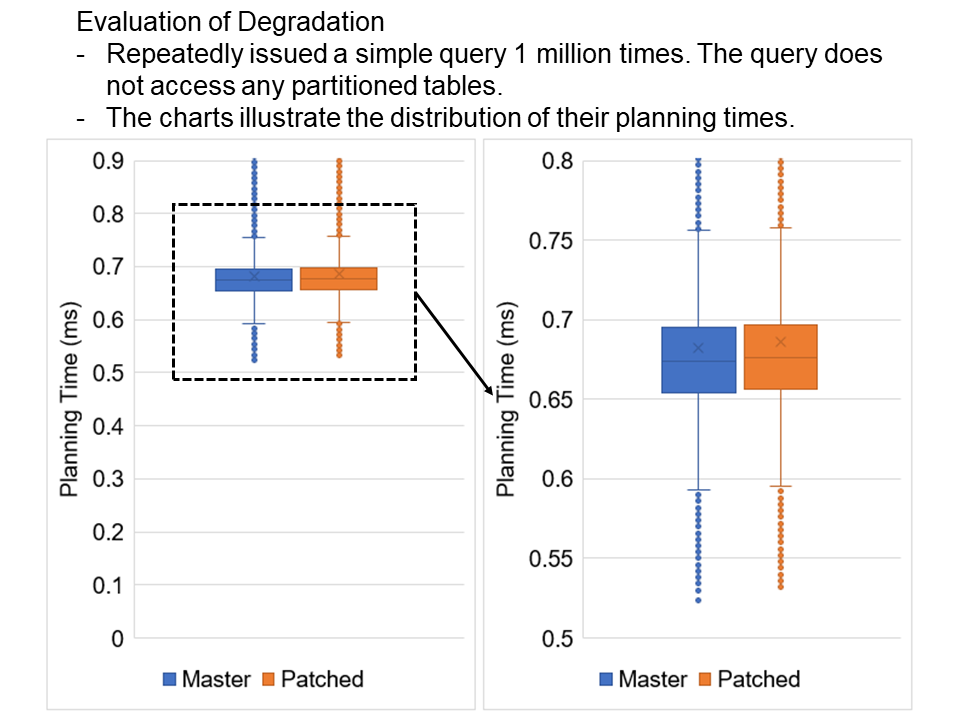
query and instead may lead to some regression. I repeatedly issued
this query 1 million times and measured their planning times.
The attached figure describes the distribution of the planning times.
The figure indicates that my patch has no severe negative impacts on
the planning performance. However, there seems to be a slight
degradation.
I show the mean and median of planning times below. With my patch, the
planning time became 0.002-0.004 milliseconds slower. We have to deal
with this problem, but reducing time complexity while keeping
degradation to zero is significantly challenging.
Planning time (ms)
| Mean | Median
------------------------------
Master | 0.682 | 0.674
Patched | 0.686 | 0.676
------------------------------
Degradation | 0.004 | 0.002
Of course, the attached result is just an example. Significant
regression might occur in other types of queries.
> For the bms_equal class of lookups, I wonder if we could get anywhere
> by adding an additional List field to every RelOptInfo that chains
> all EquivalenceMembers that match that RelOptInfo's relids.
> The trick here would be to figure out when to build those lists.
> The simple answer would be to do it lazily on-demand, but that
> would mean a separate scan of all the EquivalenceMembers for each
> RelOptInfo; I wonder if there's a way to do better?
>
> Perhaps the bms_is_subset class could be handled in a similar
> way, ie do a one-time pass to make a List of all EquivalenceMembers
> that use a RelOptInfo.
Thank you for giving your idea. I will try to polish up my algorithm
based on your suggestion.
--
Best regards,
Yuya Watari