Spurious Stalls
Вложения
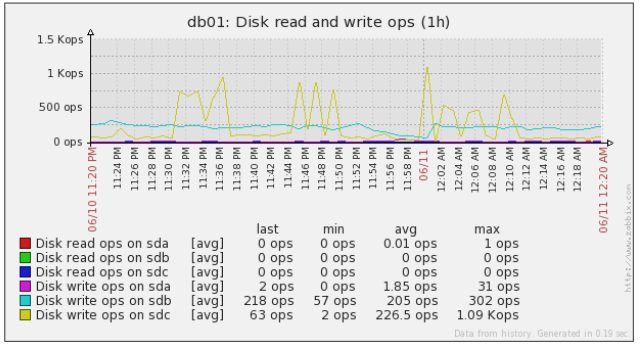
- read_write_ops.png
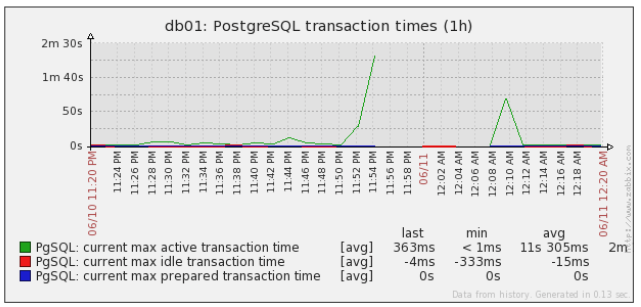
- transaction_times.png
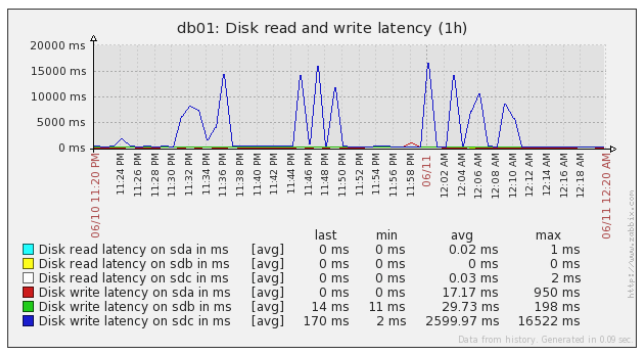
- read_write_latency.png
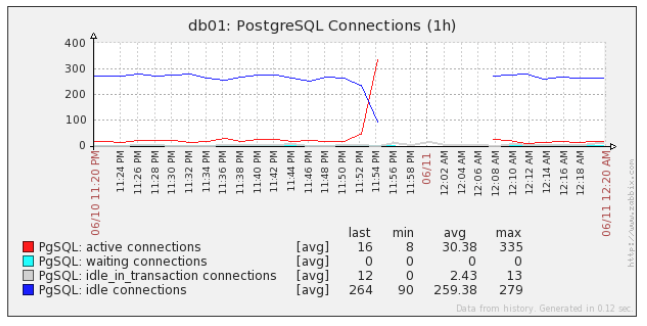
- pgsql_connections.png
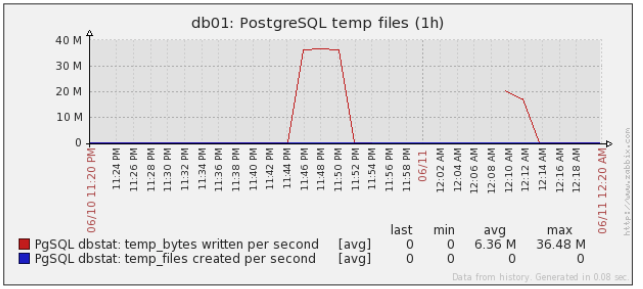
- temp_files.png
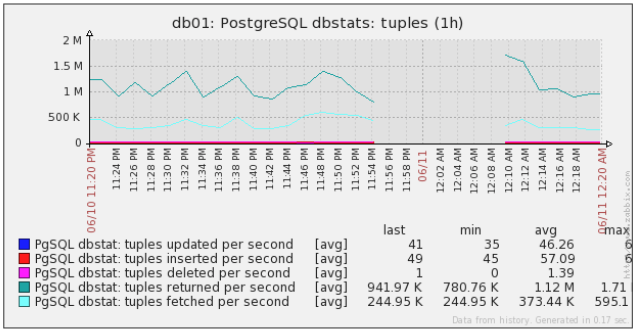
- tuples.png
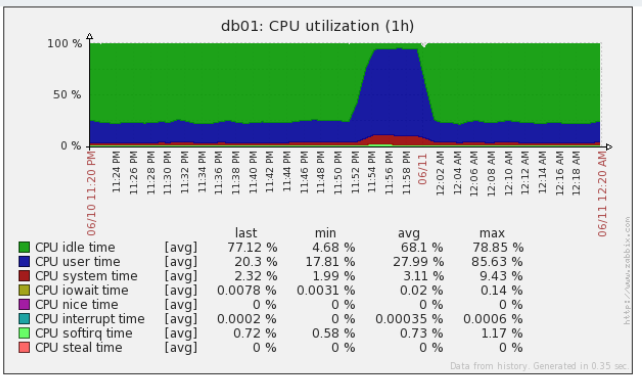
- cpu_utilization.png
- pg_db_profile.txt
- postgresql.conf
- perf_example_vmstat
- perf_example_dmesg
- perf_example_ipcs
- perf_example_locks.csv
- perf_example_pginfo
- perf_example_ps_auxfww
- perf_example_iotop
- perf_example_strace.47700
- perf_example_backtrace.47700
- perf_example_stack.47700
- perf_example_status.47700
- perf_example_strace.46462
- perf_example_syscall.47700
- perf_example_backtrace.46462
- perf_example_stack.46462
- perf_example_status.46462
- perf_example_strace.29561
- perf_example_syscall.46462
- perf_example_backtrace.29561
- perf_example_stack.29561
- perf_example_status.29561
- perf_example_syscall.29561
- perf_example_strace.81372
- perf_example_backtrace.81372
- perf_example_stack.81372
- perf_example_status.81372
- perf_example_syscall.81372
- perf_example_vacuum
В списке pgsql-general по дате отправления: