Re: very high replay_lag on 3-node cluster
Вложения
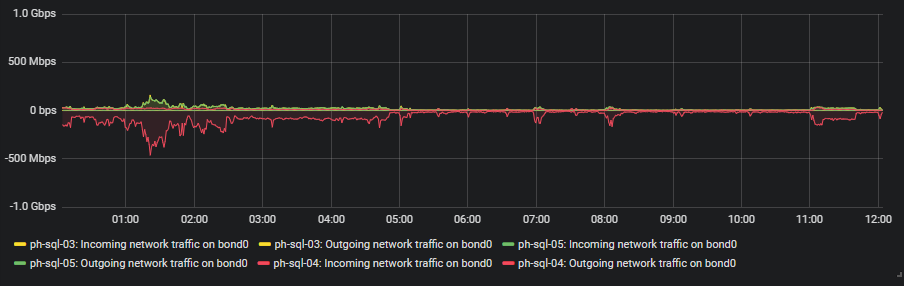
В списке pgsql-general по дате отправления:
Предыдущее
От: "Jehan-Guillaume (ioguix) de Rorthais"Дата:
Сообщение: Re: very high replay_lag on 3-node cluster
Следующее
От: Rory Campbell-LangeДата:
Сообщение: Re: How to run a task continuously in the background