Re: pgsql: Add parallel-aware hash joins.
| От | Thomas Munro |
|---|---|
| Тема | Re: pgsql: Add parallel-aware hash joins. |
| Дата | |
| Msg-id | CAEepm=2rZ6NzdR7Rk5jsXsJR8M_kRmi+0JSY1x6DLSdmBb-=VA@mail.gmail.com обсуждение исходный текст |
| Ответ на | Re: pgsql: Add parallel-aware hash joins. (Tom Lane <tgl@sss.pgh.pa.us>) |
| Ответы |
Re: pgsql: Add parallel-aware hash joins.
Re: pgsql: Add parallel-aware hash joins. |
| Список | pgsql-committers |
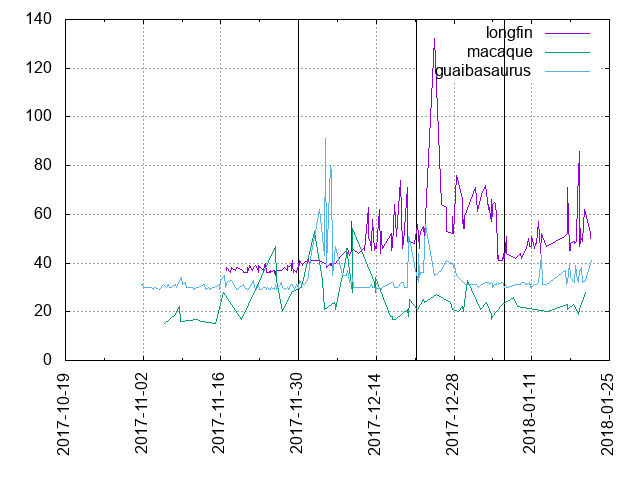
On Thu, Dec 28, 2017 at 5:26 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Thomas Munro <thomas.munro@enterprisedb.com> writes: >> On Thu, Dec 28, 2017 at 3:32 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> Aside from the instability problems, I'm pretty unhappy about how much >>> the PHJ patch has added to the runtime of "make check". I do not think >>> any one feature can justify adding 20% to that. Can't you cut down the >>> amount of data processed by these new test cases? > >> Isn't that mostly because of the CV livelock problem? > > Hm, maybe. I quoted the 20% figure on the basis of longfin's reports, > not prairiedog's ... but it might be seeing some of the livelock effect > too. > >> So without the effects of that bug it's only taking 2.4% longer than >> commit fa330f9a. Is that acceptable for a feature of this size and >> complexity? I will also look into making the data sets smaller. > > That sounds better, but it's still worth asking whether the tests > could be quicker. Here is a patch that halves the size of the test tables used. I don't want them to be too small because I want some some real parallel processing at least sometimes. On my slowest system with assertions enabled this brings "time make check" from ~37.5s to ~36.9s. I'm a bit worried about choosing parameters that lead to instability across the buildfarm, until I make the size estimation code a bit smarter[1], so I tested a few variations that affect the alignment and size of things (-m32, -malign-double, --disable-atomics, --disable-spinlocks) and didn't see failures. Does this pass repeatedly on gaur? Since you mentioned longfin, I checked some historical "check" runtimes and they seemed pretty erratic so I decided to bust out gnuplot to try to see what's happening. See attached, which goes back as far as I could web-scrape from the buildfarm. Three interesting commits are shown with vertical lines, in this order from left to right: Commit fa330f9a "Add some regression tests that exercise hash join code.", Nov 29. Commit 18042840 "Add parallel-aware hash joins.", Dec 20 Commit aced5a92 "Rewrite ConditionVariableBroadcast() to avoid live-lock.", Jan 5. For comparison I also plotted data for two other machines whose times are in a similar range. It looks to me like longfin's average and variation increased half way between fa330f9a and 18042840, somewhere near Dec 7 to 9, when we went from ~40s +/- 1 to ~50s with several seconds' variation. Was there some other environmental change then on that machine? Do you see any commit that could explain that -- maybe 0a3edbb33? Then maybe it also suffered a bit from livelock woes from 18042840 until aced5a92? It's hard to say and I'm not really sure what to make of this, but it seems clear that you could draw the wrong conclusion if you just picked a couple of random data points from that animal, and that those other animals aren't affected too much by any of these commits. [1] https://wiki.postgresql.org/wiki/Parallel_Hash
Вложения
В списке pgsql-committers по дате отправления: