Re: BitmapHeapScan streaming read user and prelim refactoring
| От | Melanie Plageman |
|---|---|
| Тема | Re: BitmapHeapScan streaming read user and prelim refactoring |
| Дата | |
| Msg-id | CAAKRu_Z+Ja-mwXebOoOERMMUMvJeRhzTjad4dSThxG0JLXESxw@mail.gmail.com обсуждение исходный текст |
| Ответ на | Re: BitmapHeapScan streaming read user and prelim refactoring (Melanie Plageman <melanieplageman@gmail.com>) |
| Ответы |
Re: BitmapHeapScan streaming read user and prelim refactoring
Re: BitmapHeapScan streaming read user and prelim refactoring |
| Список | pgsql-hackers |
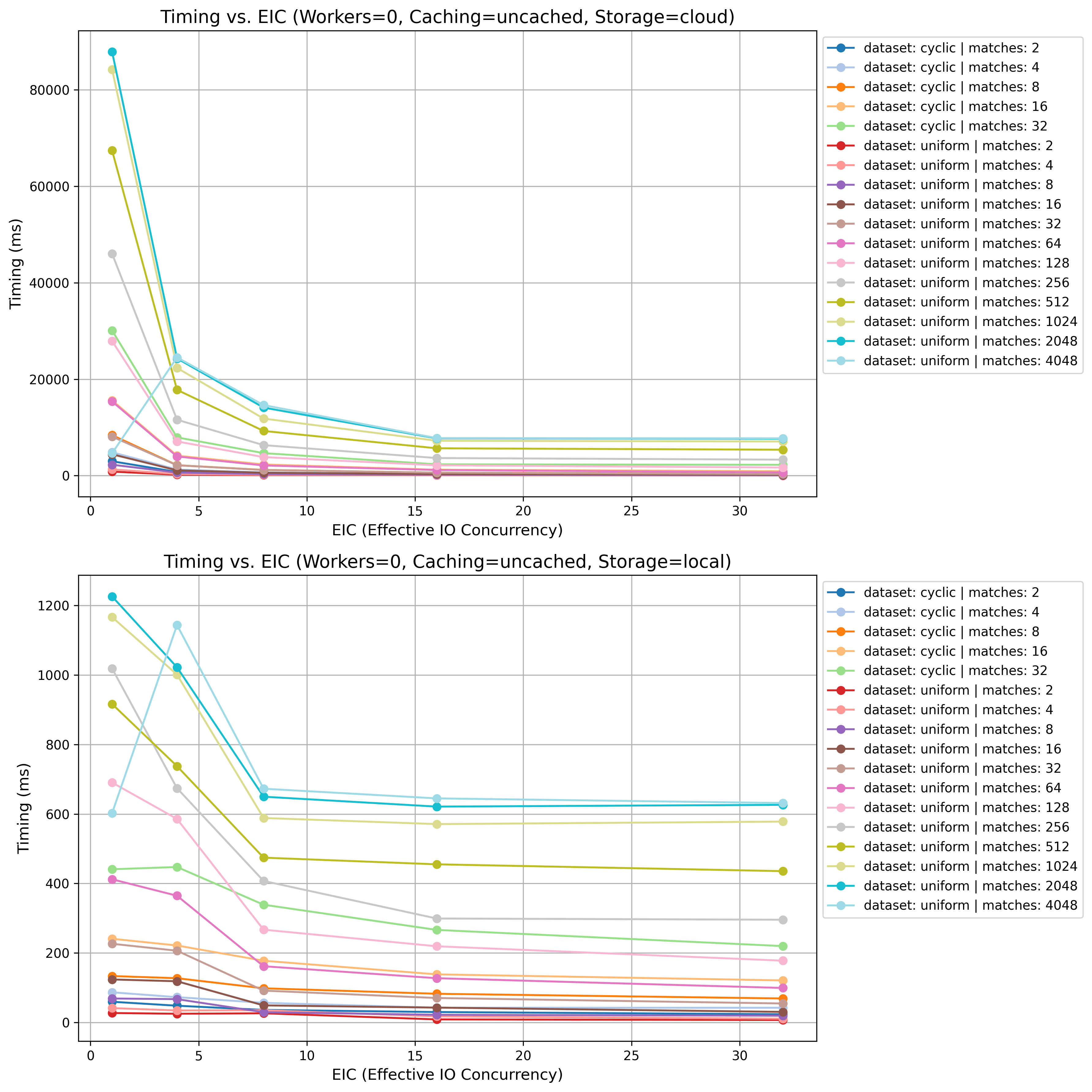
On Mon, Feb 24, 2025 at 5:07 PM Melanie Plageman <melanieplageman@gmail.com> wrote: > > I was thinking about what the default value should be for > effective_io_concurrency, and I looked back at Tomas' results. It > definitely should be > 1. But, there are cases where 16 is a > regression. So, perhaps it would be good to run some tests trying out > 4 and 8 once we have a fixed up sequential detection algorithm. I ran some experiments on master with datasets and access patterns derived from Tomas' original bitmap heap scan benchmarking scripts to try and identify a good default effective IO concurrency value on master. The takeaway is that I think 16 is a good default effectio_io_concurrency value. I've attached an image with two charts of the effects of different effective_io_concurrency values on query duration. The top are results from a cloud VM with approx 3ms random read completion latency. The bottom are results from a local nvme SSD. The results you see are only for queries for which the optimal plan was a bitmap heap scan. All results are for a 1,000,000 row (~0.5 GB total size given fillfactor) dataset. The uniform dataset has 10,000 distinct values uniformly distributed throughout the relation, so I/O should be pretty random. The cyclic dataset has 100 distinct values banded every 10,000 rows. So, rows where a = 1 would be something like row 1-100, 10,000-10,100, 20,000-20,100, etc. So there are intermittent ranges of sequential values that match. "matches" determines how big the range is in the WHERE clause. In this query, $from and $to are based on the number of matches and the number of distinct values. So a higher matches value means more of the table matches. SELECT * FROM bitmap_scan_test WHERE (a BETWEEN $from AND $to) OFFSET $rows; I also tested the linear data distribution -- which had 10,000 distinct values starting with 0, each value repeating 100 times, and linearly increasing to 10,000. None of these queries chose bitmap heap scan as the optimal plan, so they are not pictured in the results. I've displayed the results for the uncached workload (data was evicted from kernel buffer cache before doing each query). I also ran the same queries with OS caching and shared buffer caching. There was no meaningful difference. I was mostly confirming that there was no regression there with higher effective_io_concurrency values. - Melanie
Вложения
В списке pgsql-hackers по дате отправления: