Re: BitmapHeapScan streaming read user and prelim refactoring
| От | Tomas Vondra |
|---|---|
| Тема | Re: BitmapHeapScan streaming read user and prelim refactoring |
| Дата | |
| Msg-id | 84bf5689-4524-4ba1-b25e-18018045e94d@enterprisedb.com обсуждение исходный текст |
| Ответ на | Re: BitmapHeapScan streaming read user and prelim refactoring (Melanie Plageman <melanieplageman@gmail.com>) |
| Ответы |
Re: BitmapHeapScan streaming read user and prelim refactoring
|
| Список | pgsql-hackers |
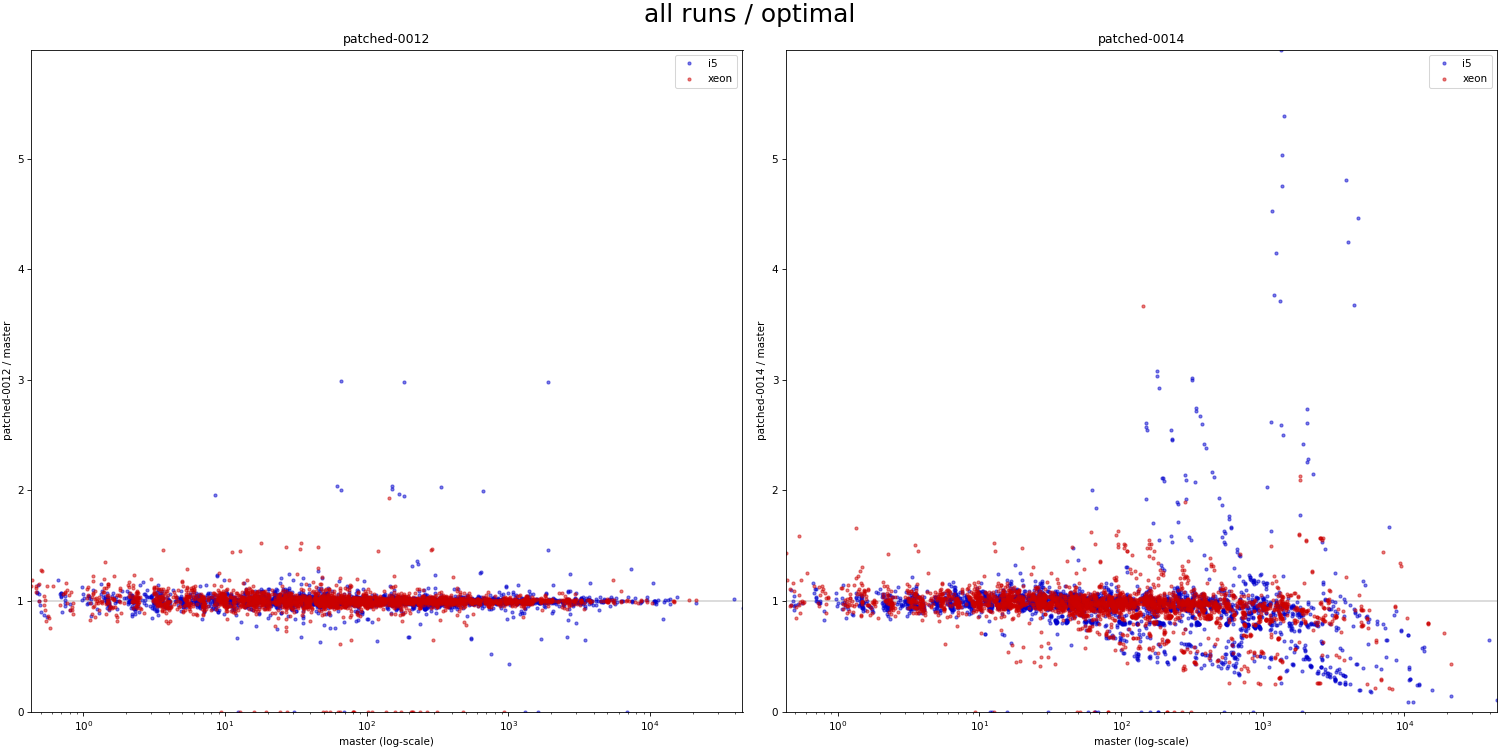
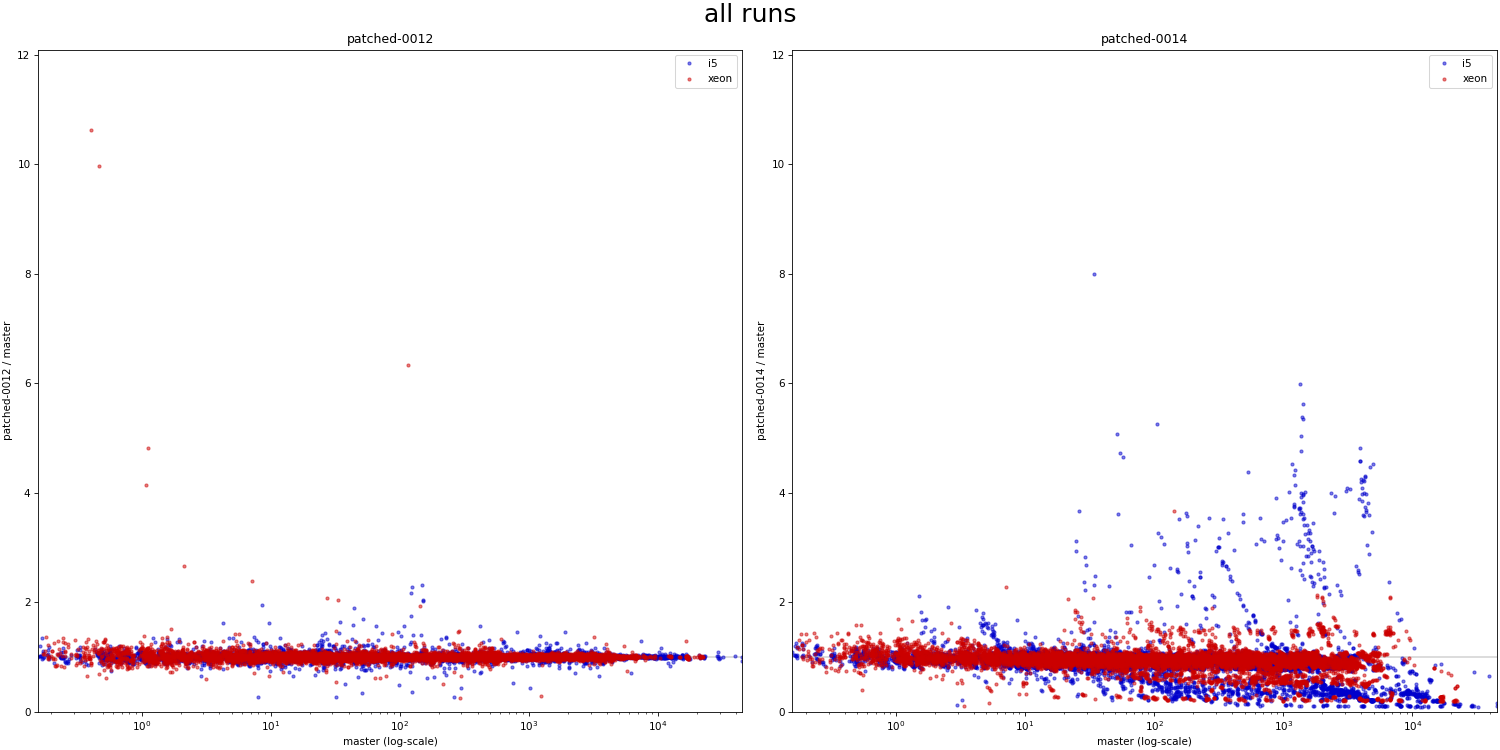
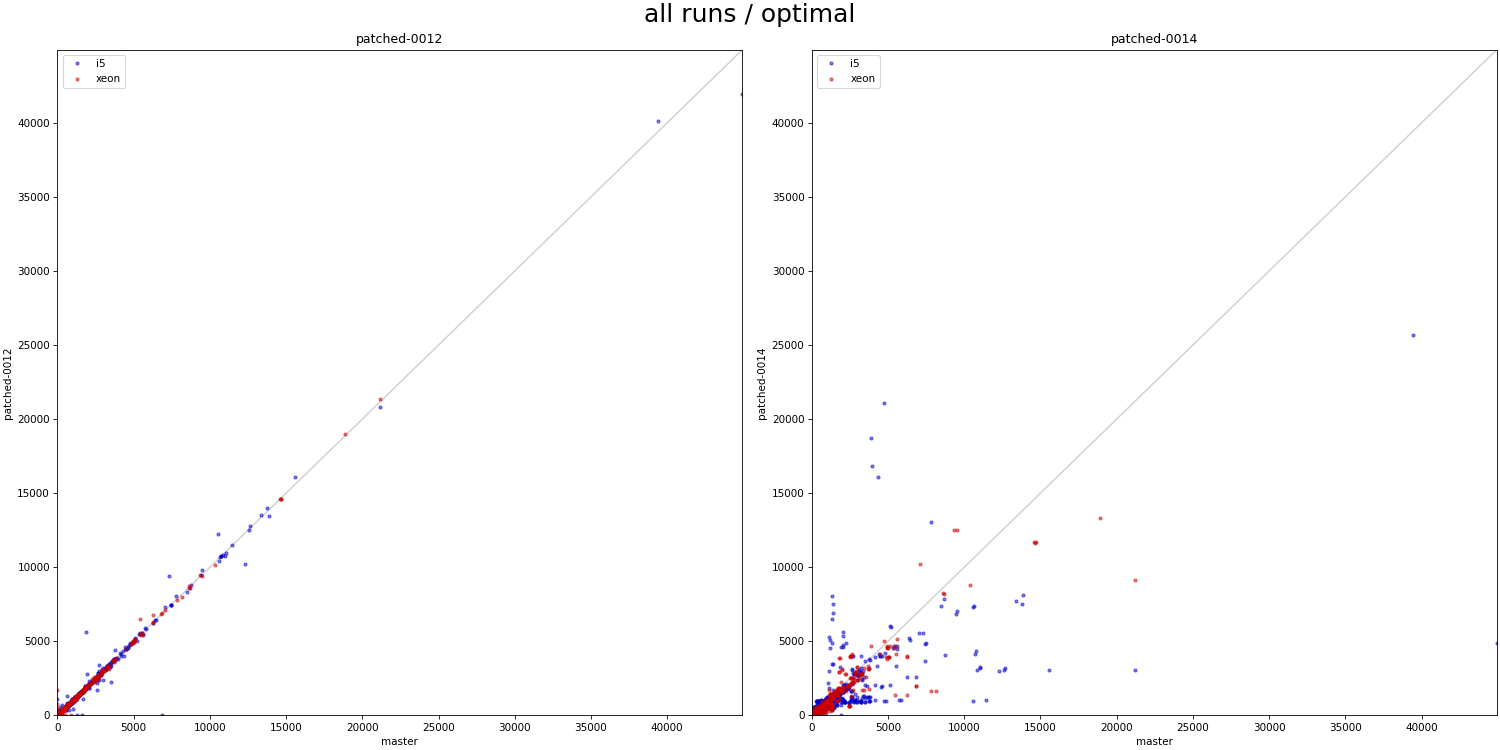
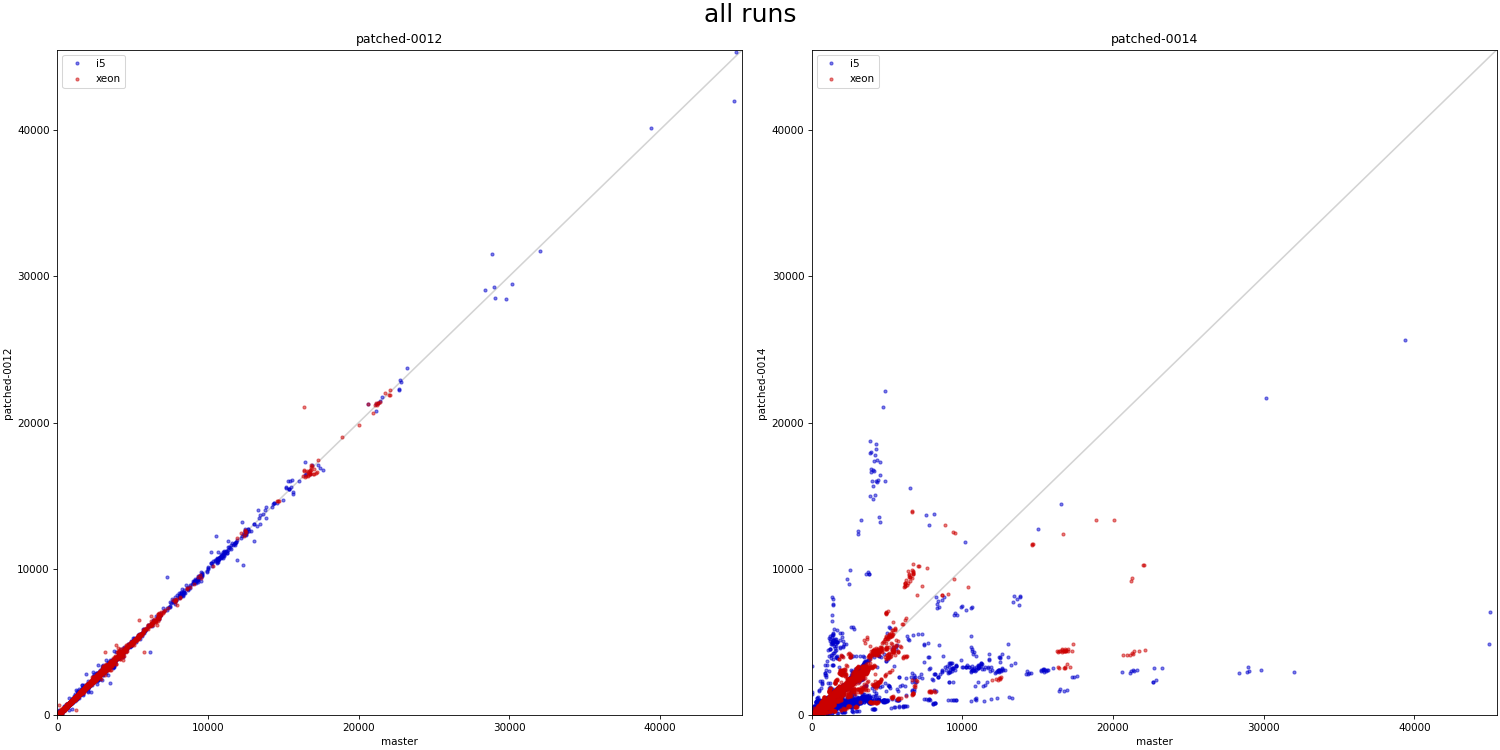
On 3/14/24 22:39, Melanie Plageman wrote: > On Thu, Mar 14, 2024 at 5:26 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> On 3/14/24 19:16, Melanie Plageman wrote: >>> On Thu, Mar 14, 2024 at 03:32:04PM +0200, Heikki Linnakangas wrote: >>>> ... >>>> >>>> Ok, committed that for now. Thanks for looking! >>> >>> Attached v6 is rebased over your new commit. It also has the "fix" in >>> 0010 which moves BitmapAdjustPrefetchIterator() back above >>> table_scan_bitmap_next_block(). I've also updated the Streaming Read API >>> commit (0013) to Thomas' v7 version from [1]. This has the update that >>> we theorize should address some of the regressions in the bitmapheapscan >>> streaming read user in 0014. >>> >> >> Should I rerun the benchmarks with these new patches, to see if it >> really helps with the regressions? > > That would be awesome! > OK, here's a couple charts comparing the effect of v6 patches to master. These are from 1M and 10M data sets, same as the runs presented earlier in this thread (the 10M is still running, but should be good enough for this kind of visual comparison). I have results for individual patches, but 0001-0013 behave virtually the same, so the charts show only 0012 and 0014 (vs master). Instead of a table with color scale (used before), I used simple scatter plots as a more compact / concise visualization. It's impossible to identify patterns (e.g. serial vs. parallel runs), but for the purpose of this comparison that does not matter. And then I'll use a chart plotting "relative" time compared to master (I find it easier to judge the relative difference than with scatter plot). 1) absolute-all - all runs (scatter plot) 2) absolute-optimal - runs where the planner would pick bitmapscan 3) relative-all - all runs (duration relative to master) 4) relative-optimal - relative, runs where bitmapscan would be picked The 0012 results are a pretty clear sign the "refactoring patches" behave exactly the same as master. There are a couple outliers (in either direction), but I'd attribute those to random noise and too few runs to smooth it out for a particular combination (especially for 10M). What is even more obvious is that 0014 behaves *VERY* differently. I'm not sure if this is a good thing or a problem is debatable/unclear. I'm sure we don't want to cause regressions, but perhaps those are due to the prefetch issue discussed elsewhere in this thread (identified by Andres and Melanie). There are also many cases that got much faster, but the question is whether this is due to better efficiency or maybe the new code being more aggressive in some way (not sure). It's however interesting the differences are way more significant (both in terms of frequency and scale) on the older machine with SATA SSDs. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
В списке pgsql-hackers по дате отправления: