Re: Cost limited statements RFC
| От | Greg Smith |
|---|---|
| Тема | Re: Cost limited statements RFC |
| Дата | |
| Msg-id | 51B3E1DA.5020007@2ndQuadrant.com обсуждение исходный текст |
| Ответ на | Re: Cost limited statements RFC (Robert Haas <robertmhaas@gmail.com>) |
| Ответы |
Re: Cost limited statements RFC
|
| Список | pgsql-hackers |
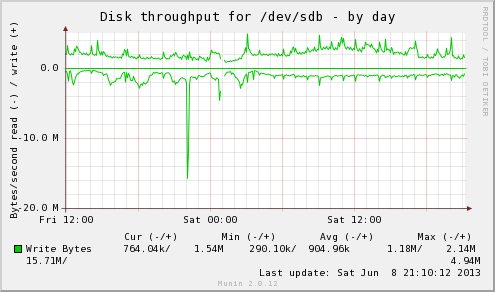
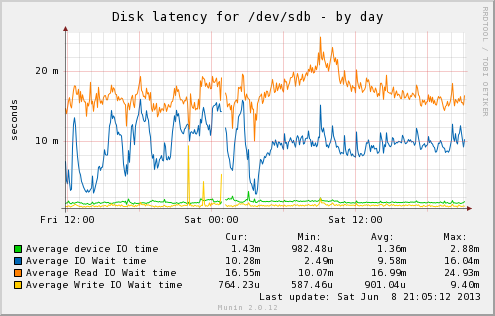
On 6/8/13 8:37 PM, Robert Haas wrote: > The main time I think you're going to hit the read limit is during > anti-wraparound vacuums. That's correct; a lot of the ones I see reading heavily are wraparound work. Those tend to be touching old blocks that are not in any cache. If the file isn't fragmented badly, this isn't as bad as it could be. Regular vacuum skips forward in relations regularly, due to the partial vacuum logic and all the mini-cleanup HOT does. Wraparound ones are more likely to hit all of the old blocks in sequence and get optimized by read-ahead. > But I have neither any firsthand experience nor any > empirical reason to presume that the write limit needs to be lower > when the read-rate is high. No argument from me that that this is an uncommon issue. Before getting into an example, I should highlight this is only an efficiency issue to me. If I can't blend the two rates together, what I'll have to do is set both read and write individually to lower values than I can right now. That's not terrible; I don't actually have a problem with that form of UI refactoring. I just need separate read and write limits of *some* form. If everyone thinks it's cleaner to give two direct limit knobs and eliminate the concept of multipliers and coupling, that's a reasonable refactoring. It just isn't the easiest change from what's there now, and that's what I was trying to push through before. Attached are some Linux graphs from a system that may surprise you, one where it would be tougher to tune aggressively without reads and writes sharing a cost limit. sdb is a RAID-1 with a pair of 15K RPM drives, and the workload is heavy on index lookups hitting random blocks on that drive. The reason this write-heavy server has so much weirdness with mixed I/O is that its disk response times are reversed from normal. Look at the latency graph (sdb-day.png). Writes are typically 10ms, while reads average 17ms! This is due to the size and manner of write caches. The server can absorb writes and carefully queue them for less seeking, across what I call a "sorting horizon" that includes a 512MB controller cache and the dirty memory in RAM. Meanwhile, when reads come in, they need to be done immediately to be useful. That means it's really only reordering/combining across the 32 element NCQ cache. (I'm sure that's the useful one because I can watch efficiency tank if I reduce that specific queue depth) The sorting horizon here is less than 1MB. On the throughput graph, + values above the axis are write throughput, while - ones are reads. It's subtle, but during the periods where the writes are heavy, the read I/O the server can support to the same drive drops too. Compare 6:00 (low writes, high reads) to 12:00 (high writes, low reads). When writes rise, it can't quite support the same read throughput anymore. This isn't that surprising on a system where reads cost more than writes do. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
Вложения
В списке pgsql-hackers по дате отправления: