Re: Cost limited statements RFC
| От | Greg Smith |
|---|---|
| Тема | Re: Cost limited statements RFC |
| Дата | |
| Msg-id | 51B11D16.1010102@2ndQuadrant.com обсуждение исходный текст |
| Ответ на | Re: Cost limited statements RFC (Robert Haas <robertmhaas@gmail.com>) |
| Ответы |
Re: Cost limited statements RFC
|
| Список | pgsql-hackers |
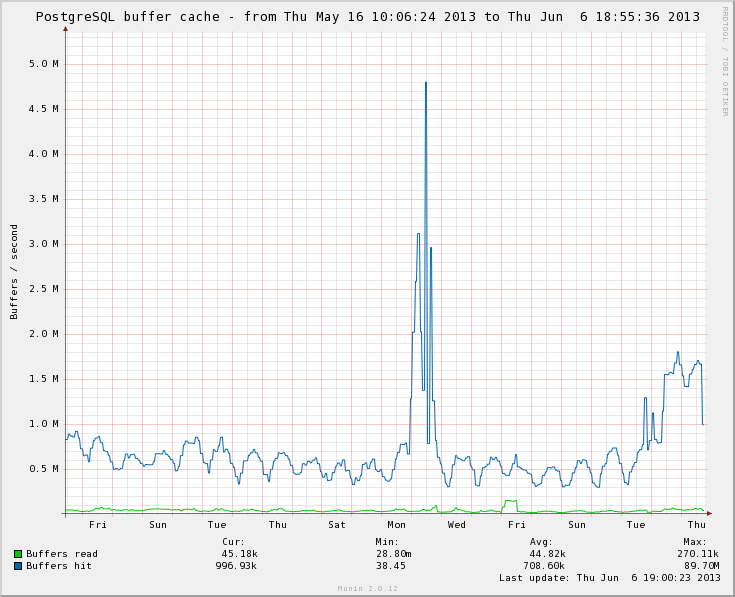
On 6/6/13 4:02 PM, Robert Haas wrote: > If we can see our way clear to ripping out the autovacuum costing > stuff and replacing them with a read rate limit and a dirty rate > limit, I'd be in favor of that. The current system limits the linear > combination of those with user-specified coefficients, which is more > powerful but less intuitive. There is also an implied memory bandwidth limit via the costing for a hit, which was the constraint keeping me from just going this way last time this came up. It essentially limits vacuum to 78MB/s of scanning memory even when there's no disk I/O involved. I wasn't sure if that was still important, you can also control it now via these coefficients, and most of the useful disk rate refactorings simplify a lot if that's gone. The rest of this message is some evidence that's not worth keeping though, which leads into a much cleaner plan than I tried to pitch before. I can now tell you that a busy server with decent memory can easily chug through 7.8GB/s of activity against shared_buffers, making the existing 78MB/s limit is a pretty tight one. 7.8GB/s of memory access is 1M buffers/second as measured by pg_stat_database.blks_read. I've attached a sample showing the highest rate I've seen as evidence of how fast servers can really go now, from a mainstream 24 Intel cores in 2 sockets system. Nice hardware, but by no means exotic stuff. And I can hit 500M buffers/s = 4GB/s of memory even with my laptop. I have also subjected some busy sites to a field test here since the original discussion, to try and nail down if this is really necessary. So far I haven't gotten any objections, and I've seen one serious improvement, after setting vacuum_cost_page_hit to 0. The much improved server is the one I'm showing here. When a page hit doesn't cost anything, the new limiter on how fast vacuum can churn through a well cached relation usually becomes the CPU speed of a single core. Nowadays, you can peg any single core like that and still not disrupt the whole server. If the page hit limit goes away, the user with a single core server who used to having autovacuum only pillage shared_buffers at 78MB/s might complain that if it became unbounded. I'm not scared of that impacting any sort of mainstream hardware from the last few years though. I think you'd have to be targeting PostgreSQL on embedded or weak mobile chips to even notice the vacuum page hit rate here in 2013. And even if your database is all in shared_buffers so it's possible to chug through it non-stop, you're way more likely to suffer from an excess dirty page write rate than this. Buying that it's OK to scrap the hit limit leads toward a simple to code implementation of read/write rate limits implemented like this: -vacuum_cost_page_* are removed as external GUCs. Maybe the internal accounting for them stays the same for now, just to keep the number of changes happening at once easier. -vacuum_cost_delay becomes an internal parameter fixed at 20ms. That's worked out OK in the field, there's not a lot of value to a higher setting, and lower settings are impractical due to the effective 10ms lower limit on sleeping some systems have. -vacuum_cost_limit goes away as an external GUC, and instead the actual cost limit becomes an internal value computed from the other parameters. At the default values the value that pops out will still be close to 200. Not messing with that will keep all of the autovacuum worker cost splitting logic functional. -New vacuum_read_limit and vacuum_write_limit are added as a kB value for the per second maximum rate. -1 means unlimited. The pair replaces changing the cost delay as the parameters that turns cost limiting on or off. That's 5 GUCs with complicated setting logic removed, replaced by 2 simple knobs, plus some churn in the autovacuum_* versions. Backwards compatibility for tuned systems will be shot. My position is that anyone smart enough to have navigated the existing mess of these settings and done something useful with them will happily take having their custom tuning go away, if it's in return for the simplification. At this point I feel exactly the same way I did about the parameters removed by the BGW auto-tuning stuff that went away in 8.3, with zero missing the old knobs that I heard. Another year of experiments and feedback has convinced me nobody is setting this usefully in the field who wouldn't prefer the new interface. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
Вложения
В списке pgsql-hackers по дате отправления: