Re: Seq scans roadmap
| От | Heikki Linnakangas |
|---|---|
| Тема | Re: Seq scans roadmap |
| Дата | |
| Msg-id | 46406CF7.9020607@enterprisedb.com обсуждение исходный текст |
| Ответ на | Re: Seq scans roadmap ("Luke Lonergan" <LLonergan@greenplum.com>) |
| Ответы |
Re: Seq scans roadmap
|
| Список | pgsql-hackers |
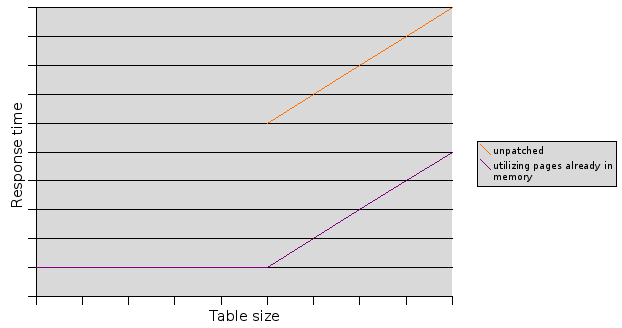
Luke Lonergan wrote: > On 3A: In practice, the popular modern OS'es (BSD/Linux/Solaris/etc) > implement dynamic I/O caching. The experiments have shown that benefit > of re-using PG buffer cache on large sequential scans is vanishingly > small when the buffer cache size is small compared to the system memory. > Since this is a normal and recommended situation (OS I/O cache is > auto-tuning and easy to administer, etc), IMO the effort to optimize > buffer cache reuse for seq scans > 1 x buffer cache size is not > worthwhile. That's interesting. Care to share the results of the experiments you ran? I was thinking of running tests of my own with varying table sizes. The main motivation here is to avoid the sudden drop in performance when a table grows big enough not to fit in RAM. See attached diagram for what I mean. Maybe you're right and the effect isn't that bad in practice. I'm thinking of attacking 3B first anyway, because it seems much simpler to implement. > On 3B: The scenario described is "multiple readers seq scanning large > table and sharing bufcache", but in practice this is not a common > situation. The common situation is "multiple queries joining several > small tables to one or more large tables that are >> 1 x bufcache". In > the common scenario, the dominant factor is the ability to keep the > small tables in bufcache (or I/O cache for that matter) while running > the I/O bound large table scans as fast as possible. How is that different from what I described? > To that point - an important factor in achieving max I/O rate for large > tables (> 1 x bufcache) is avoiding the pollution of the CPU L2 cache. > This is commonly in the range of 512KB -> 2MB, which is only important > when considering a bound on the size of the ring buffer. The effect has > been demonstrated to be significant - in the 20%+ range. Another thing > to consider is the use of readahead inside the heapscan, in which case > sizes >= 32KB are very effective. Yeah I remember the discussion on the L2 cache a while back. What do you mean with using readahead inside the heapscan? Starting an async read request? > The modifications you suggest here may not have the following > properties: > - don't pollute bufcache for seqscan of tables > 1 x bufcache > - for tables > 1 x bufcache use a ringbuffer for I/O that is ~ 32KB to > minimize L2 cache pollution So the difference is that you don't want 3A (the take advantage of pages already in buffer cache) strategy at all, and want the buffer ring strategy to kick in earlier instead. Am I reading you correctly? -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Вложения
В списке pgsql-hackers по дате отправления: