Re: [PERFORM] Slow query: bitmap scan troubles
| От | Tom Lane |
|---|---|
| Тема | Re: [PERFORM] Slow query: bitmap scan troubles |
| Дата | |
| Msg-id | 12791.1357580151@sss.pgh.pa.us обсуждение исходный текст |
| Ответ на | Re: [PERFORM] Slow query: bitmap scan troubles (Tom Lane <tgl@sss.pgh.pa.us>) |
| Ответы |
Re: [PERFORM] Slow query: bitmap scan troubles
|
| Список | pgsql-hackers |
I wrote:
> Now, if we consider only CPU costs of index descent, we expect
> about log2(P) comparisons to be needed on each of the H upper pages
> to be descended through, that is we have total descent cost
> cpu_index_tuple_cost * H * log2(P)
> If we ignore the ceil() step as being a second-order correction, this
> can be simplified to
> cpu_index_tuple_cost * H * log2(N)/(H+1)
I thought some more about this and concluded that the above reasoning is
incorrect, because it ignores the fact that initial positioning on the
index leaf page requires another log2(P) comparisons (to locate the
first matching tuple if any). If you include those comparisons then the
H/(H+1) factor drops out and you are left with just "cost * log2(N)",
independently of the tree height.
But all is not lost for including some representation of the physical
index size into this calculation, because it seems plausible to consider
that there is some per-page cost for descending through the upper pages.
It's not nearly as much as random_page_cost, if the pages are cached,
but we don't have to suppose it's zero. So that reasoning leads to a
formula like
cost-per-tuple * log2(N) + cost-per-page * (H+1)
which is better than the above proposal anyway because we can now
twiddle the two cost factors separately rather than being tied to a
fixed idea of how much a larger H hurts.
As for the specific costs to use, I'm now thinking that the
cost-per-tuple should be just cpu_operator_cost (0.0025) not
cpu_index_tuple_cost (0.005). The latter is meant to model costs such
as reporting a TID back out of the index AM to the executor, which is
not what we're doing at an upper index entry. I also propose setting
the per-page cost to some multiple of cpu_operator_cost, since it's
meant to represent a CPU cost not an I/O cost.
There is already a charge of 100 times cpu_operator_cost in
genericcostestimate to model "general costs of starting an indexscan".
I suggest that we should consider half of that to be actual fixed
overhead and half of it to be per-page cost for the first page, then
add another 50 times cpu_operator_cost for each page descended through.
That gives a formula of
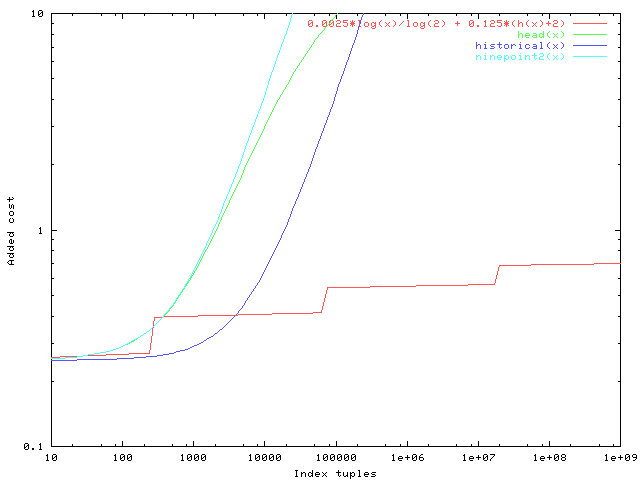
cpu_operator_cost * log2(N) + cpu_operator_cost * 50 * (H+2)
This would lead to the behavior depicted in the attached plot, wherein
I've modified the comparison lines (historical, 9.2, and HEAD behaviors)
to include the existing 100 * cpu_operator_cost startup cost charge in
addition to the fudge factor we've been discussing so far. The new
proposed curve is a bit above the historical curve for indexes with
250-5000 tuples, but the value is still quite small there, so I'm not
too worried about that. The people who've been complaining about 9.2's
behavior have indexes much larger than that.
Thoughts?
regards, tom lane
set terminal png small color
set output 'new_costs.png'
set xlabel "Index tuples"
set ylabel "Added cost"
set logscale x
set logscale y
h(x) = (x <= 256.0) ? 0 : (x <= 256.0*256) ? 1 : (x <= 256.0*256*256) ? 2 : (x <= 256.0*256*256*256) ? 3 : (x <=
256.0*256*256*256*256)? 4 : 5
head(x) = 4*log(1 + x/10000) + 0.25
historical(x) = 4 * x/100000 + 0.25
ninepoint2(x) = 4 * x/10000 + 0.25
plot [10:1e9][0.1:10] 0.0025*log(x)/log(2) + 0.125*(h(x)+2), head(x), historical(x), ninepoint2(x)
Вложения
В списке pgsql-hackers по дате отправления: