RE: [PoC] Non-volatile WAL buffer
| От | Takashi Menjo |
|---|---|
| Тема | RE: [PoC] Non-volatile WAL buffer |
| Дата | |
| Msg-id | 000401d69bbd$92856bf0$b79043d0$@hco.ntt.co.jp_1 обсуждение исходный текст |
| Ответ на | Re: [PoC] Non-volatile WAL buffer (Takashi Menjo <takashi.menjo@gmail.com>) |
| Ответы |
RE: [PoC] Non-volatile WAL buffer
("Deng, Gang" <gang.deng@intel.com>)
|
| Список | pgsql-hackers |
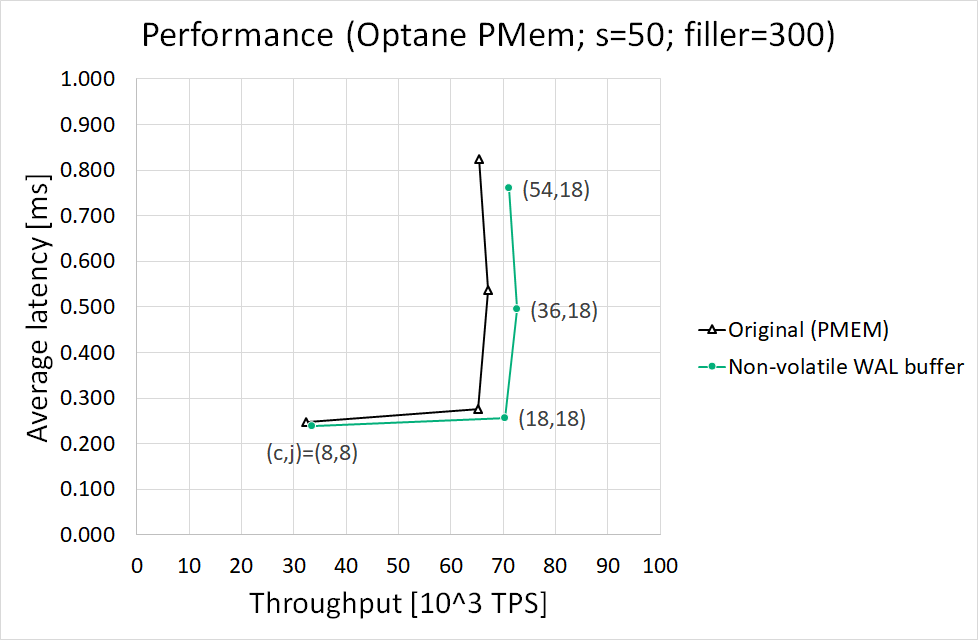
Hi Gang,
I have tried to but yet cannot reproduce performance degrade you reported when inserting 328-byte records. So I think
thecondition of you and me would be different, such as steps to reproduce, postgresql.conf, installation setup, and so
on.
My results and condition are as follows. May I have your condition in more detail? Note that I refer to your "Storage
overApp Direct" as my "Original (PMEM)" and "NVWAL patch" to "Non-volatile WAL buffer."
Best regards,
Takashi
# Results
See the attached figure. In short, Non-volatile WAL buffer got better performance than Original (PMEM).
# Steps
Note that I ran postgres server and pgbench in a single-machine system but separated two NUMA nodes. PMEM and PCI SSD
forthe server process are on the server-side NUMA node.
01) Create a PMEM namespace (sudo ndctl create-namespace -f -t pmem -m fsdax -M dev -e namespace0.0)
02) Make an ext4 filesystem for PMEM then mount it with DAX option (sudo mkfs.ext4 -q -F /dev/pmem0 ; sudo mount -o dax
/dev/pmem0/mnt/pmem0)
03) Make another ext4 filesystem for PCIe SSD then mount it (sudo mkfs.ext4 -q -F /dev/nvme0n1 ; sudo mount
/dev/nvme0n1/mnt/nvme0n1)
04) Make /mnt/pmem0/pg_wal directory for WAL
05) Make /mnt/nvme0n1/pgdata directory for PGDATA
06) Run initdb (initdb --locale=C --encoding=UTF8 -X /mnt/pmem0/pg_wal ...)
- Also give -P /mnt/pmem0/pg_wal/nvwal -Q 81920 in the case of Non-volatile WAL buffer
07) Edit postgresql.conf as the attached one
- Please remove nvwal_* lines in the case of Original (PMEM)
08) Start postgres server process on NUMA node 0 (numactl -N 0 -m 0 -- pg_ctl -l pg.log start)
09) Create a database (createdb --locale=C --encoding=UTF8)
10) Initialize pgbench tables with s=50 (pgbench -i -s 50)
11) Change # characters of "filler" column of "pgbench_history" table to 300 (ALTER TABLE pgbench_history ALTER filler
TYPEcharacter(300);)
- This would make the row size of the table 328 bytes
12) Stop the postgres server process (pg_ctl -l pg.log -m smart stop)
13) Remount the PMEM and the PCIe SSD
14) Start postgres server process on NUMA node 0 again (numactl -N 0 -m 0 -- pg_ctl -l pg.log start)
15) Run pg_prewarm for all the four pgbench_* tables
16) Run pgbench on NUMA node 1 for 30 minutes (numactl -N 1 -m 1 -- pgbench -r -M prepared -T 1800 -c __ -j __)
- It executes the default tpcb-like transactions
I repeated all the steps three times for each (c,j) then got the median "tps = __ (including connections establishing)"
ofthe three as throughput and the "latency average = __ ms " of that time as average latency.
# Environment variables
export PGHOST=/tmp
export PGPORT=5432
export PGDATABASE="$USER"
export PGUSER="$USER"
export PGDATA=/mnt/nvme0n1/pgdata
# Setup
- System: HPE ProLiant DL380 Gen10
- CPU: Intel Xeon Gold 6240M x2 sockets (18 cores per socket; HT disabled by BIOS)
- DRAM: DDR4 2933MHz 192GiB/socket x2 sockets (32 GiB per channel x 6 channels per socket)
- Optane PMem: Apache Pass, AppDirect Mode, DDR4 2666MHz 1.5TiB/socket x2 sockets (256 GiB per channel x 6 channels per
socket;interleaving enabled)
- PCIe SSD: DC P4800X Series SSDPED1K750GA
- Distro: Ubuntu 20.04.1
- C compiler: gcc 9.3.0
- libc: glibc 2.31
- Linux kernel: 5.7 (vanilla)
- Filesystem: ext4 (DAX enabled when using Optane PMem)
- PMDK: 1.9
- PostgreSQL (Original): 14devel (200f610: Jul 26, 2020)
- PostgreSQL (Non-volatile WAL buffer): 14devel (200f610: Jul 26, 2020) + non-volatile WAL buffer patchset v4
--
Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
NTT Software Innovation Center
> -----Original Message-----
> From: Takashi Menjo <takashi.menjo@gmail.com>
> Sent: Thursday, September 24, 2020 2:38 AM
> To: Deng, Gang <gang.deng@intel.com>
> Cc: pgsql-hackers@postgresql.org; Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp>
> Subject: Re: [PoC] Non-volatile WAL buffer
>
> Hello Gang,
>
> Thank you for your report. I have not taken care of record size deeply yet, so your report is very interesting. I
will
> also have a test like yours then post results here.
>
> Regards,
> Takashi
>
>
> 2020年9月21日(月) 14:14 Deng, Gang <gang.deng@intel.com <mailto:gang.deng@intel.com> >:
>
>
> Hi Takashi,
>
>
>
> Thank you for the patch and work on accelerating PG performance with NVM. I applied the patch and made
> some performance test based on the patch v4. I stored database data files on NVMe SSD and stored WAL file on
> Intel PMem (NVM). I used two methods to store WAL file(s):
>
> 1. Leverage your patch to access PMem with libpmem (NVWAL patch).
>
> 2. Access PMem with legacy filesystem interface, that means use PMem as ordinary block device, no
> PG patch is required to access PMem (Storage over App Direct).
>
>
>
> I tried two insert scenarios:
>
> A. Insert small record (length of record to be inserted is 24 bytes), I think it is similar as your test
>
> B. Insert large record (length of record to be inserted is 328 bytes)
>
>
>
> My original purpose is to see higher performance gain in scenario B as it is more write intensive on WAL.
> But I observed that NVWAL patch method had ~5% performance improvement compared with Storage over App
> Direct method in scenario A, while had ~20% performance degradation in scenario B.
>
>
>
> I made further investigation on the test. I found that NVWAL patch can improve performance of XlogFlush
> function, but it may impact performance of CopyXlogRecordToWAL function. It may be related to the higher
> latency of memcpy to Intel PMem comparing with DRAM. Here are key data in my test:
>
>
>
> Scenario A (length of record to be inserted: 24 bytes per record):
>
> ==============================
>
> NVWAL
> SoAD
>
> ------------------------------------ ------- -------
>
> Througput (10^3 TPS) 310.5
> 296.0
>
> CPU Time % of CopyXlogRecordToWAL 0.4 0.2
>
> CPU Time % of XLogInsertRecord 1.5 0.8
>
> CPU Time % of XLogFlush 2.1 9.6
>
>
>
> Scenario B (length of record to be inserted: 328 bytes per record):
>
> ==============================
>
> NVWAL
> SoAD
>
> ------------------------------------ ------- -------
>
> Througput (10^3 TPS) 13.0
> 16.9
>
> CPU Time % of CopyXlogRecordToWAL 3.0 1.6
>
> CPU Time % of XLogInsertRecord 23.0 16.4
>
> CPU Time % of XLogFlush 2.3 5.9
>
>
>
> Best Regards,
>
> Gang
>
>
>
> From: Takashi Menjo <takashi.menjo@gmail.com <mailto:takashi.menjo@gmail.com> >
> Sent: Thursday, September 10, 2020 4:01 PM
> To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> Cc: pgsql-hackers@postgresql.org <mailto:pgsql-hackers@postgresql.org>
> Subject: Re: [PoC] Non-volatile WAL buffer
>
>
>
> Rebased.
>
>
>
>
>
> 2020年6月24日(水) 16:44 Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp> >:
>
> Dear hackers,
>
> I update my non-volatile WAL buffer's patchset to v3. Now we can use it in streaming replication
> mode.
>
> Updates from v2:
>
> - walreceiver supports non-volatile WAL buffer
> Now walreceiver stores received records directly to non-volatile WAL buffer if applicable.
>
> - pg_basebackup supports non-volatile WAL buffer
> Now pg_basebackup copies received WAL segments onto non-volatile WAL buffer if you run it with
> "nvwal" mode (-Fn).
> You should specify a new NVWAL path with --nvwal-path option. The path will be written to
> postgresql.auto.conf or recovery.conf. The size of the new NVWAL is same as the master's one.
>
>
> Best regards,
> Takashi
>
> --
> Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> NTT Software Innovation Center
>
> > -----Original Message-----
> > From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> > Sent: Wednesday, March 18, 2020 5:59 PM
> > To: 'PostgreSQL-development' <pgsql-hackers@postgresql.org
> <mailto:pgsql-hackers@postgresql.org> >
> > Cc: 'Robert Haas' <robertmhaas@gmail.com <mailto:robertmhaas@gmail.com> >; 'Heikki
> Linnakangas' <hlinnaka@iki.fi <mailto:hlinnaka@iki.fi> >; 'Amit Langote'
> > <amitlangote09@gmail.com <mailto:amitlangote09@gmail.com> >
> > Subject: RE: [PoC] Non-volatile WAL buffer
> >
> > Dear hackers,
> >
> > I rebased my non-volatile WAL buffer's patchset onto master. A new v2 patchset is attached
> to this mail.
> >
> > I also measured performance before and after patchset, varying -c/--client and -j/--jobs
> options of pgbench, for
> > each scaling factor s = 50 or 1000. The results are presented in the following tables and the
> attached charts.
> > Conditions, steps, and other details will be shown later.
> >
> >
> > Results (s=50)
> > ==============
> > Throughput [10^3 TPS] Average latency [ms]
> > ( c, j) before after before after
> > ------- --------------------- ---------------------
> > ( 8, 8) 35.7 37.1 (+3.9%) 0.224 0.216 (-3.6%)
> > (18,18) 70.9 74.7 (+5.3%) 0.254 0.241 (-5.1%)
> > (36,18) 76.0 80.8 (+6.3%) 0.473 0.446 (-5.7%)
> > (54,18) 75.5 81.8 (+8.3%) 0.715 0.660 (-7.7%)
> >
> >
> > Results (s=1000)
> > ================
> > Throughput [10^3 TPS] Average latency [ms]
> > ( c, j) before after before after
> > ------- --------------------- ---------------------
> > ( 8, 8) 37.4 40.1 (+7.3%) 0.214 0.199 (-7.0%)
> > (18,18) 79.3 86.7 (+9.3%) 0.227 0.208 (-8.4%)
> > (36,18) 87.2 95.5 (+9.5%) 0.413 0.377 (-8.7%)
> > (54,18) 86.8 94.8 (+9.3%) 0.622 0.569 (-8.5%)
> >
> >
> > Both throughput and average latency are improved for each scaling factor. Throughput seemed
> to almost reach
> > the upper limit when (c,j)=(36,18).
> >
> > The percentage in s=1000 case looks larger than in s=50 case. I think larger scaling factor
> leads to less
> > contentions on the same tables and/or indexes, that is, less lock and unlock operations. In such
> a situation,
> > write-ahead logging appears to be more significant for performance.
> >
> >
> > Conditions
> > ==========
> > - Use one physical server having 2 NUMA nodes (node 0 and 1)
> > - Pin postgres (server processes) to node 0 and pgbench to node 1
> > - 18 cores and 192GiB DRAM per node
> > - Use an NVMe SSD for PGDATA and an interleaved 6-in-1 NVDIMM-N set for pg_wal
> > - Both are installed on the server-side node, that is, node 0
> > - Both are formatted with ext4
> > - NVDIMM-N is mounted with "-o dax" option to enable Direct Access (DAX)
> > - Use the attached postgresql.conf
> > - Two new items nvwal_path and nvwal_size are used only after patch
> >
> >
> > Steps
> > =====
> > For each (c,j) pair, I did the following steps three times then I found the median of the three as
> a final result shown
> > in the tables above.
> >
> > (1) Run initdb with proper -D and -X options; and also give --nvwal-path and --nvwal-size
> options after patch
> > (2) Start postgres and create a database for pgbench tables
> > (3) Run "pgbench -i -s ___" to create tables (s = 50 or 1000)
> > (4) Stop postgres, remount filesystems, and start postgres again
> > (5) Execute pg_prewarm extension for all the four pgbench tables
> > (6) Run pgbench during 30 minutes
> >
> >
> > pgbench command line
> > ====================
> > $ pgbench -h /tmp -p 5432 -U username -r -M prepared -T 1800 -c ___ -j ___ dbname
> >
> > I gave no -b option to use the built-in "TPC-B (sort-of)" query.
> >
> >
> > Software
> > ========
> > - Distro: Ubuntu 18.04
> > - Kernel: Linux 5.4 (vanilla kernel)
> > - C Compiler: gcc 7.4.0
> > - PMDK: 1.7
> > - PostgreSQL: d677550 (master on Mar 3, 2020)
> >
> >
> > Hardware
> > ========
> > - System: HPE ProLiant DL380 Gen10
> > - CPU: Intel Xeon Gold 6154 (Skylake) x 2sockets
> > - DRAM: DDR4 2666MHz {32GiB/ch x 6ch}/socket x 2sockets
> > - NVDIMM-N: DDR4 2666MHz {16GiB/ch x 6ch}/socket x 2sockets
> > - NVMe SSD: Intel Optane DC P4800X Series SSDPED1K750GA
> >
> >
> > Best regards,
> > Takashi
> >
> > --
> > Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> NTT Software Innovation Center
> >
> > > -----Original Message-----
> > > From: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> > > Sent: Thursday, February 20, 2020 6:30 PM
> > > To: 'Amit Langote' <amitlangote09@gmail.com <mailto:amitlangote09@gmail.com> >
> > > Cc: 'Robert Haas' <robertmhaas@gmail.com <mailto:robertmhaas@gmail.com> >; 'Heikki
> Linnakangas' <hlinnaka@iki.fi <mailto:hlinnaka@iki.fi> >;
> > 'PostgreSQL-development'
> > > <pgsql-hackers@postgresql.org <mailto:pgsql-hackers@postgresql.org> >
> > > Subject: RE: [PoC] Non-volatile WAL buffer
> > >
> > > Dear Amit,
> > >
> > > Thank you for your advice. Exactly, it's so to speak "do as the hackers do when in pgsql"...
> > >
> > > I'm rebasing my branch onto master. I'll submit an updated patchset and performance report
> later.
> > >
> > > Best regards,
> > > Takashi
> > >
> > > --
> > > Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp <mailto:takashi.menjou.vg@hco.ntt.co.jp>
> > NTT Software
> > > Innovation Center
> > >
> > > > -----Original Message-----
> > > > From: Amit Langote <amitlangote09@gmail.com <mailto:amitlangote09@gmail.com> >
> > > > Sent: Monday, February 17, 2020 5:21 PM
> > > > To: Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp> >
> > > > Cc: Robert Haas <robertmhaas@gmail.com <mailto:robertmhaas@gmail.com> >; Heikki
> Linnakangas
> > > > <hlinnaka@iki.fi <mailto:hlinnaka@iki.fi> >; PostgreSQL-development
> > > > <pgsql-hackers@postgresql.org <mailto:pgsql-hackers@postgresql.org> >
> > > > Subject: Re: [PoC] Non-volatile WAL buffer
> > > >
> > > > Hello,
> > > >
> > > > On Mon, Feb 17, 2020 at 4:16 PM Takashi Menjo <takashi.menjou.vg@hco.ntt.co.jp
> <mailto:takashi.menjou.vg@hco.ntt.co.jp> > wrote:
> > > > > Hello Amit,
> > > > >
> > > > > > I apologize for not having any opinion on the patches
> > > > > > themselves, but let me point out that it's better to base these
> > > > > > patches on HEAD (master branch) than REL_12_0, because all new
> > > > > > code is committed to the master branch, whereas stable branches
> > > > > > such as
> > > > > > REL_12_0 only receive bug fixes. Do you have any
> > > > specific reason to be working on REL_12_0?
> > > > >
> > > > > Yes, because I think it's human-friendly to reproduce and discuss
> > > > > performance measurement. Of course I know
> > > > all new accepted patches are merged into master's HEAD, not stable
> > > > branches and not even release tags, so I'm aware of rebasing my
> > > > patchset onto master sooner or later. However, if someone,
> > > > including me, says that s/he applies my patchset to "master" and
> > > > measures its performance, we have to pay attention to which commit the "master"
> > > > really points to. Although we have sha1 hashes to specify which
> > > > commit, we should check whether the specific commit on master has
> > > > patches affecting performance or not
> > > because master's HEAD gets new patches day by day. On the other hand,
> > > a release tag clearly points the commit all we probably know. Also we
> > > can check more easily the features and improvements by using release notes and user
> manuals.
> > > >
> > > > Thanks for clarifying. I see where you're coming from.
> > > >
> > > > While I do sometimes see people reporting numbers with the latest
> > > > stable release' branch, that's normally just one of the baselines.
> > > > The more important baseline for ongoing development is the master
> > > > branch's HEAD, which is also what people volunteering to test your
> > > > patches would use. Anyone who reports would have to give at least
> > > > two numbers -- performance with a branch's HEAD without patch
> > > > applied and that with patch applied -- which can be enough in most
> > > > cases to see the difference the patch makes. Sure, the numbers
> > > > might change on each report, but that's fine I'd think. If you
> > > > continue to develop against the stable branch, you might miss to
> > > notice impact from any relevant developments in the master branch,
> > > even developments which possibly require rethinking the architecture of your own changes,
> although maybe that
> > rarely occurs.
> > > >
> > > > Thanks,
> > > > Amit
>
>
>
>
>
>
> --
>
> Takashi Menjo <takashi.menjo@gmail.com <mailto:takashi.menjo@gmail.com> >
>
>
>
> --
>
> Takashi Menjo <takashi.menjo@gmail.com <mailto:takashi.menjo@gmail.com> >
Вложения
В списке pgsql-hackers по дате отправления:
Предыдущее
От: "osumi.takamichi@fujitsu.com"Дата:
Сообщение: RE: extension patch of CREATE OR REPLACE TRIGGER
Следующее
От: Amit KapilaДата:
Сообщение: Re: Resetting spilled txn statistics in pg_stat_replication