Новые статьи от Postgres Professional на сайте www.HABRAHABR.ru | 2017
Сотрудники нашей компании - разработчики, инженеры, преподаватели - продолжают писать статьи для нашего технического блога на сайте www.HABRAHABR.ru. За последние месяцы в этом блоге появились 5 новых статей. А общее количество статей за полтора года существования нашего ХабраБлога приблизилось к трем десяткам. Что это за статьи, читайте в этом кратком обзоре.
И сперва, конечно, список новинок:
- Индексы в PostgreSQL — часть 1
от 19.04.2017 | автор: Егор Рогов - Примеры реальных патчей в PostgreSQL: часть 3 из N
от 06.04.2017 | автор: Александр Алексеев - Еще одна новая фича pg_filedump: восстанавливаем каталог PostgreSQL
от 10.03.2017 | автор: Александр Алексеев - Пример восстановления таблиц PostgreSQL с помощью новой фичи pg_filedump
от 18.01.2017 | автор: Александр Алексеев - Демонстрационная база данных для PostgreSQL
от 30.11.2016 | автор: Егор Рогов
Далее, как обычно, по вступительному абзацу от каждой статьи, для того, что бы быстро разобраться, о чем каждая статья, и решить, какую из статей читать в первую очередь.

Предисловие
В этой серии статей речь пойдет об индексах в PostgreSQL.
Любой вопрос можно рассматривать с разных точек зрения. Мы будем говорить о том, что должно интересовать прикладного разработчика, использующего СУБД: какие индексы существуют, почему в PostgreSQL их так много разных, и как их использовать для ускорения запросов. Пожалуй, тему можно было бы раскрыть и меньшим числом слов, но мы в тайне надеемся на любознательного разработчика, которому также интересны и подробности внутреннего устройства, тем более, что понимание таких подробностей позволяет не только прислушиваться к чужому мнению, но и делать собственные выводы.
За скобками обсуждения останутся вопросы разработки новых типов индексов. Это требует знания языка Си и относится скорее к компетенции системного программиста, а не прикладного разработчика. По этой же причине мы практически не будем рассматривать программные интерфейсы, а остановимся только на том, что имеет значение для использования уже готовых к употреблению индексов.
В этой части мы поговорим про разделение сфер ответственности между общим механизмом индексирования, относящимся к ядру СУБД, и отдельными методами индексного доступа, которые в PostgreSQL можно добавлять как расширения. В следующей части мы рассмотрим интерфейс метода доступа и такие важные понятия, как классы и семейства операторов. После такого длинного, но необходимого введения мы подробно рассмотрим устройство и применение различных типов индексов: Hash, B-tree, GiST, SP-GiST, GIN и RUM, BRIN, Bloom.
Индексы
Индексы в PostgreSQL — специальные объекты базы данных, предназначенные в основном для ускорения доступа к данным. Это вспомогательные структуры: любой индекс можно удалить и восстановить заново по информации в таблице. Иногда приходится слышать, что СУБД может работать и без индексов, просто медленно. Однако это не так, ведь индексы служат также для поддержки некоторых ограничений целостности.

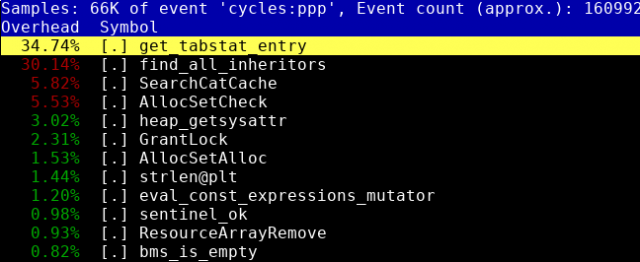
Сегодня я хотел бы вновь рассказать о некоторых патчах, принятых за последнее время в PostgreSQL (а также утилиту pg_filedump). Аналогичные статьи, опубликованные на Хабре ранее, набрали достаточно много плюсиков, что заставляет думать, что они представляют для кого-то интерес. Если вы пропустили предыдущие статьи, вот они — раз, два, три. Несмотря на то, что рассмотренные патчи были написаны мной, не стоит забывать о вкладе людей, которые их ревьювили и тестировали. Проделанная этими людьми работа зачастую оказывается больше и сложнее работы самого автора. Особо активное участие в разработке рассмотренных пачтей приняли Федор Сигаев, Robert Haas, Tom Lane, Дмитрий Иванов, Григорий Смолкин, Andres Freund, Анастасия Лубенникова и Tels.

В прошлой статье мы узнали, как при помощи утилиты pg_filedump можно восстановить данные, или, по крайней мере, какую-то их часть, из полностью убитой базы PostgreSQL. При этом предполагалось, что мы откуда-то знаем номера сегментов, соответствующих таблице. Если мы знаем часть содержимого таблицы, ее сегменты действительно не сложно найти, например, простым grep'ом. Однако в более общем случае это не так-то просто сделать. К тому же, предполагалось, что мы знаем точную схему таблиц, что тоже далеко не факт. Так вот, недавно мы с коллегами сделали новый патч для pg_filedump, позволяющий решить названные проблемы.
Пример восстановления таблиц PostgreSQL
с помощью новой мега фичи pg_filedump
Александр Алексеев18.01.2017

Позвольте я расскажу вам об одной классной фиче, которую мы с коллегами из Postgres Pro недавно запилили в утилите pg_filedump. Фича эта позволяет частично восстанавливать данные из базы, даже в случае, если база была сильно повреждена и инстанс PostgreSQL с такой базой уже не запустишь. Конечно, хочется верить, что потребность в таком функционале возникает крайне редко. Но на всякий случай нечто подобное хотелось бы иметь под рукой. Читайте дальше, и вы узнаете, как данная фича выглядит в действии.
В этой заметке я расскажу о нашей демонстрационной базе данных для PostgreSQL: почему она важна для нас и как может пригодиться вам, как устроена схема и какие данные в ней содержатся.
Сразу приведу ссылку на полное описание (там же написано, где взять демо-базу и как ее установить).
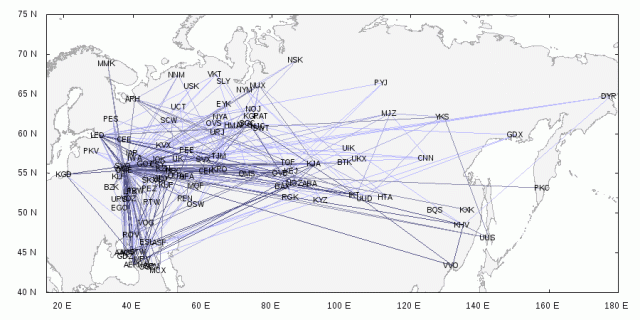
С нашей точки зрения, необходимость в демонстрационной базе назрела давно. Чтобы обсудить практически любую возможность СУБД, нужны какие-то данные, нужна таблица или несколько таблиц. Изобретать этот велосипед каждый раз заново — впустую тратить и внимание слушателя, и свое собственное время. Недаром каждый производитель СУБД имеет базу, которую и использует каждый раз, когда нужно что-либо продемонстрировать.
Для чего может понадобиться такая база данных?
Во-первых, для самостоятельного изучения SQL. Допустим, вы студент, осваиваете SQL и прочитали, скажем, про рекурсивные запросы. Надо ведь на чем-то потренироваться?
С другой стороны, чтобы студент смог прочитать про рекурсивные запросы, нужно, чтобы кто-нибудь об этом написал. Наша компания сотрудничает с несколькими авторами и сейчас идет работа над университетским курсом по технологиям баз данных и учебным пособием по SQL — обе книги будут использовать демонстрационную базу. Можно будет не просто прочитать книгу, а тут же воспроизвести приведенные в ней примеры, «поиграться» с ними, выполнить практические задания.
Другой вариант — проведение практики по курсу баз данных в вузе (или даже чтение коммерческого курса по SQL: лицензия PostgreSQL, под которой выпущена демо-база, это разрешает). Примеры такого использования уже есть.
Демонстрационную базу полезно задействовать и для написания заметок в блог или статей про PostgreSQL и его возможности. Вместо того, чтобы каждый раз начинать со слов «создадим табличку и вставим какие-нибудь данные с помощью generate_series», можно сразу приступать к делу.
Мы думаем и над переработкой со временем документации PostgreSQL, чтобы и она максимально опиралась на схему и данные демо-базы.
Сразу приведу ссылку на полное описание (там же написано, где взять демо-базу и как ее установить).
Зачем?
С нашей точки зрения, необходимость в демонстрационной базе назрела давно. Чтобы обсудить практически любую возможность СУБД, нужны какие-то данные, нужна таблица или несколько таблиц. Изобретать этот велосипед каждый раз заново — впустую тратить и внимание слушателя, и свое собственное время. Недаром каждый производитель СУБД имеет базу, которую и использует каждый раз, когда нужно что-либо продемонстрировать.
Для чего может понадобиться такая база данных?
Во-первых, для самостоятельного изучения SQL. Допустим, вы студент, осваиваете SQL и прочитали, скажем, про рекурсивные запросы. Надо ведь на чем-то потренироваться?
С другой стороны, чтобы студент смог прочитать про рекурсивные запросы, нужно, чтобы кто-нибудь об этом написал. Наша компания сотрудничает с несколькими авторами и сейчас идет работа над университетским курсом по технологиям баз данных и учебным пособием по SQL — обе книги будут использовать демонстрационную базу. Можно будет не просто прочитать книгу, а тут же воспроизвести приведенные в ней примеры, «поиграться» с ними, выполнить практические задания.
Другой вариант — проведение практики по курсу баз данных в вузе (или даже чтение коммерческого курса по SQL: лицензия PostgreSQL, под которой выпущена демо-база, это разрешает). Примеры такого использования уже есть.
Демонстрационную базу полезно задействовать и для написания заметок в блог или статей про PostgreSQL и его возможности. Вместо того, чтобы каждый раз начинать со слов «создадим табличку и вставим какие-нибудь данные с помощью generate_series», можно сразу приступать к делу.
Мы думаем и над переработкой со временем документации PostgreSQL, чтобы и она максимально опиралась на схему и данные демо-базы.
