СУБД для 1С Fresh. Быстро. Надежно. Бесплатно
«Кнопка» уже несколько лет для работы с бухгалтерскими базами использует технологию публикаций 1C Fresh. Мы уже недавно писали о нашем опыте эксплуатации. Использование нами в качестве СУБД PostgreSQL вызвало интерес и ряд вопросов, поэтому мы решили рассказать об этом подробнее.

Введение
В самом начале мы использовали в качестве СУБД традиционный для 1С MS SQL Server. Когда наш Fresh дорос до необходимости горизонтального масштабирования, стало понятно, что по экономическим соображениям нужна альтернатива продукту от Microsoft. Тогда мы внимательно посмотрели в сторону PostgreSQL, тем более что специалисты из 1С его рекомендовали к использованию в инсталляции 1С Fresh. Мы провели простое сравнение производительности на стандартных операциях и выяснили, что база Бухгалтерия Предприятия (БП) 3.0, содержащая около 600 областей работает не хуже. В то время мы переходили на схему нескольких виртуальных машин на Linux с сервером приложений и СУБД. Об этом немного рассказано в статье. Но по разным причинам через год пришли к схеме сервер приложений на Windows и СУБД с несколькими информационными базами (ИБ) на Linux. Но смеем вас заверить, что проблем с работой сервера приложений на Linux у нас не было, изменения связаны с некоторыми другими нашими особенностями работы.
Итак, в качестве сервера баз данных был выбран PostgreSQL. В этой статье Кнопка расскажет, как мы подружили одно с другим, и как это всё заработало.
В первой инсталляции использовали готовые deb-пакеты PostgreSQL 8.4.3-3.1C, предоставляемые 1С, так как это была рекомендуемая для использования версия. Но к сожалению, столкнулись с проблемой зависимостей при установке на Debian Wheezy, являющийся на тот момент oldstable выпуском, содержащим пакеты apache2.2 (поддержки apache2.4 в 1С тогда еще не было). В то время мы держали СУБД и сервер приложений на одном хосте, поэтому приходилось использовать oldstable. Для установки этой версии PostgreSQL требовался libc6 из Debian Jessie. В результате такого скрещивания получилась система, с которой особо ничего не сделаешь, даже установка NFS-клиента ломала необходимые для работы зависимости. Но переходить на другой дистрибутив Linux нам было не выгодно стратегически. Когда мы начали активно использовать микросервисы (для простоты мы называем их роботами), которые взаимодействовали с сервером приложений через COM-соединение, в базах данных начали появляться висящие коннекты, которые приводили к утечке памяти. Эта проблема решалась переходом на новую версию PostgreSQL, но в тот момент 1С еще не выпустил дистрибутив этой версии.
Мы приняли волевое решение перейти на использование сборки PostgreSQL 9.6 из репозитория Postgres Professional. Проблемы с зависимостями и утечкой памяти остались позади, и мы начали решать вопросы масштабируемости, распределения нагрузки и увеличения времени доступности. В настоящее время специалистами 1С уже обновлены сборки PostgreSQL, самая свежая 9.6.3, это вполне актуальная версия и надежнее использовать именно её. По информации от 1С новые сборки будут выпускаться оперативно.
В настоящее время мы работаем на Debian Jessie и далее мы будем рассматривать все вопросы в рамках этого дистрибутива.
Состояние нашей системы мы отслеживаем с помощью Zabbix, выглядит это вот так:
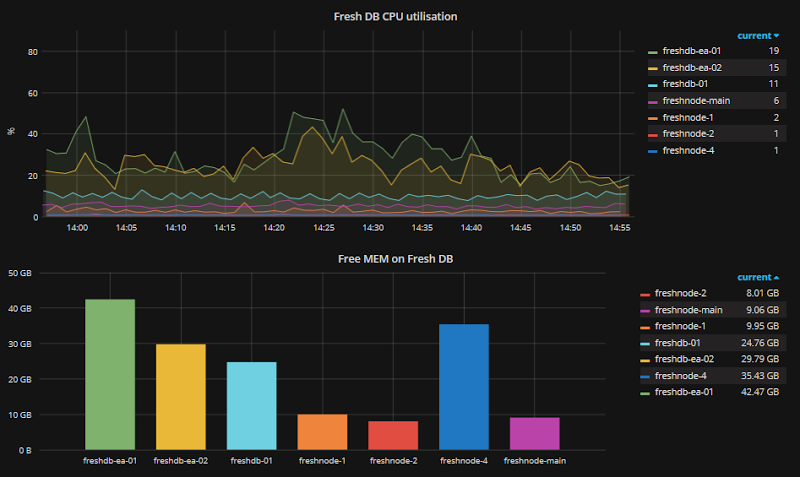
На графиках еще присутствуют старые серверы, но продуктив уже переведен с них на PostgreSQL 9.6.
А еще мы меряем количество транзакций:
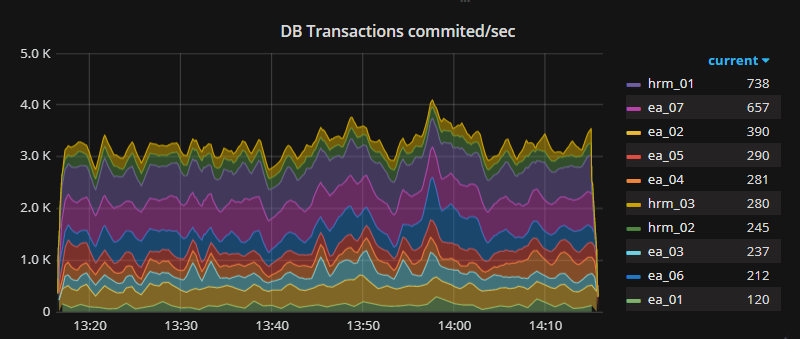
И количество добавленных, измененных и удаленных строк:

В эксплуатации СУБД мы внимательно следим за нашими показателями и все настройки, приведенные ниже, родились именно из реальной эксплуатации и наблюдений. У нас сейчас 2 основных сервера СУБД, каждому из которых выделено по 8 ядер и 40 Гб памяти. Диски с базами располагаются на SSD. Этих ресурсов нам хватает для обслуживания 7 ИБ БП 3.0 с включенным режимом разделения данных (200-800 областей в одной базе). При такой конфигурации мы добились неплохой утилизации ресурсов с одной стороны и хорошего запаса для роста и пиковых нагрузок с другой.
Кластеры в PostgreSQL
При размещении нескольких ИБ на одной виртуальной машине, мы столкнулись со сложностью администрирования. Каждая ИБ желала своих настроек сервера, любая остановка СУБД отключала все базы, а еще архивация WAL совсем не имела смысла, потому что восстановление через этот механизм откатывало бы все базы на сервере.
Для начала каждую из наших баз разместили в отдельном кластере PostgreSQL, что дало возможность гибко управлять ими, запускать несколько независимых копий PostgreSQL на одном хосте, настроить потоковую репликацию, архивирование WAL, а также восстановление данных на момент времени (PiTR).
На практике процесс развертывания выглядит так:
У нас имеется машина, с установленным Debian 8 Jessie, уже установлен PostgreSQL 9.6 из репозитория Postgres Professional.
Создадим наш новый кластер:
# pg_createcluster 9.6 -p 5433 -d /databases/db_01
После этого в /databases создастся каталог db_01, в котором разместятся файлы данных, а файлы конфигурации в /etc/postgresql/9.6/db_01/. Кластер будет использовать 9.6 версию PostgreSQL его экземпляр будет запущен на порту 5433. Сейчас кластер не запущен, это можно проверить командой:
# pg_lsclusters
Вносим изменения в конфигурационный файл кластера postgresql.conf, приблизительные значения параметров можно получить используя PgTune. За что отвечает тот или иной параметр подробно рассказано в документации, мы же поясним только те параметры, которые PgTune не учитывает.
max_parallel_workers_per_gather полезно установить значение равное количеству воркеров, которые будут использоваться параллельно для последовательного чтения таблиц. Это ускорит многие операции чтения. Исходите из количества ядер на вашем хосте, превышение этого количества не даст прироста производительности, а наоборот, произойдет деградация.
max_locks_per_transaction по-умолчанию 64, но в ходе работы значение подняли до 300. Параметр назначает количество блокировок объектов, выделяемых на транзакцию. Если будет использоваться слейв-сервер, то это значение на нём должно быть равно или больше чем на мастер-сервере.
Если файловая система не достаточно производительна, разместите pg_xlog на отдельном хранилище.
Для примера конфиг файл одного кластера:
# -----------------------------
# PostgreSQL configuration file
# -----------------------------
#------------------------------------------------------------------------------
# FILE LOCATIONS
#------------------------------------------------------------------------------
data_directory = '/db/disk_database_db_01/db_01'
hba_file = '/etc/postgresql/9.6/db_01/pg_hba.conf'
ident_file = '/etc/postgresql/9.6/db_01/pg_ident.conf'
external_pid_file = '/var/run/postgresql/9.6-db_01.pid'
#------------------------------------------------------------------------------
# CONNECTIONS AND AUTHENTICATION
#------------------------------------------------------------------------------
listen_addresses = '*'
port = 5433
max_connections = 100
unix_socket_directories = '/var/run/postgresql'
ssl = true
ssl_cert_file = '/etc/ssl/certs/ssl-cert-snakeoil.pem'
ssl_key_file = '/etc/ssl/private/ssl-cert-snakeoil.key'
#------------------------------------------------------------------------------
# RESOURCE USAGE (except WAL)
#------------------------------------------------------------------------------
shared_buffers = 1536MB
work_mem = 7864kB
maintenance_work_mem = 384MB
dynamic_shared_memory_type = posix
shared_preload_libraries = 'online_analyze, plantuner,pg_stat_statements'
#------------------------------------------------------------------------------
# WRITE AHEAD LOG
#------------------------------------------------------------------------------
wal_level = replica
wal_buffers = 16MB
max_wal_size = 2GB
min_wal_size = 1GB
checkpoint_completion_target = 0.9
#------------------------------------------------------------------------------
# REPLICATION
#------------------------------------------------------------------------------
max_wal_senders = 2
wal_keep_segments = 32
#------------------------------------------------------------------------------
# QUERY TUNING
#------------------------------------------------------------------------------
effective_cache_size = 4608MB
#------------------------------------------------------------------------------
# RUNTIME STATISTICS
#------------------------------------------------------------------------------
stats_temp_directory = '/var/run/postgresql/9.6-db_01.pg_stat_tmp'
#------------------------------------------------------------------------------
# CLIENT CONNECTION DEFAULTS
#------------------------------------------------------------------------------
datestyle = 'iso, dmy'
timezone = 'localtime'
lc_messages = 'ru_RU.UTF-8' # locale for system error message
# strings
lc_monetary = 'ru_RU.UTF-8' # locale for monetary formatting
lc_numeric = 'ru_RU.UTF-8' # locale for number formatting
lc_time = 'ru_RU.UTF-8' # locale for time formatting
default_text_search_config = 'pg_catalog.russian'
#------------------------------------------------------------------------------
# LOCK MANAGEMENT
#------------------------------------------------------------------------------
max_locks_per_transaction = 300 # min 10
#------------------------------------------------------------------------------
# VERSION/PLATFORM COMPATIBILITY
#------------------------------------------------------------------------------
escape_string_warning = off
standard_conforming_strings = off
#------------------------------------------------------------------------------
# CUSTOMIZED OPTIONS
#------------------------------------------------------------------------------
online_analyze.threshold = 50
online_analyze.scale_factor = 0.1
online_analyze.enable = on
online_analyze.verbose = off
online_analyze.min_interval = 10000
online_analyze.table_type = 'temporary'
plantuner.fix_empty_table = false
Настало время запустить свежесозданный кластер и начать его использовать:
# pg_ctlcluster 9.6 db_01 start
Для подключения по нестандартному порту в оснастке администрирования серверов 1С Предприятия в параметрах информационной базы в поле «Сервер баз данных» указать:
hostname port=5433
А еще важно не забывать про регулярное обслуживание базы. VACUUM и ANALYZE очень полезны.
Потоковая репликация
Реализация standby-сервера довольно проста.
Настроим master-сервер
Вносим изменения в файл конфигурации postgresql.conf, не забыв, что конфигурируем наш новый кластер и находится файл в /etc/postgresql/9.6/db_01/
listen_addresses = '*'
wal_level = replica
max_wal_senders = 3
wal_keep_segments = 128
Создадим новую роль replica:
postgres=# CREATE ROLE replica WITH REPLICATION PASSWORD 'MyBestPassword' LOGIN;
И разрешим подключение для slave-сервера, поправив файл pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD
host replication replica 192.168.0.0/24 md5
После этого потребуется перезапустить кластер:
# pg_ctlcluster 9.6 db_01 restart
Теперь пришло время настроить slave-сервер. Предположим, что конфигурация его идентична мастеру, создан кластер с таким же названием, файлы данных лежат в каталоге, который смонтирован аналогично мастеру. Остановим кластер на слейве:
# pg_ctlcluster 9.6 db_01 stop
В файле postgresql.conf включаем режим standby:
hot_standby = on
Очищаем каталог с файлами данных на слейве /databases/db_01/ и делаем копию текущего состояния мастера на слейв:
# cd /databases/db_01
# rm -Rf /databases/db_01
# su postgres -c "pg_basebackup -h master.domain.local -p 5433 -U replica -D /databases/db_01 -R -P --xlog-method=stream"
Будет создан файл recovery.conf, поправим его по необходимости:
standby_mode = 'on'
primary_conninfo = 'user=replica password=MyBestPassword host=master.domain.local port=5433 sslmode=prefer sslcompression=1 krbsrvname=postgres'
В данном случае мы не делаем failover, который будет автоматически забирать роль мастера. Чтобы реплика начала работать в роли мастера достаточно переименовать файл recovery.conf и перезапустить кластер.
Запускаем слейв кластер:
# pg_ctlcluster 9.6 db_01 start
Проверим, что репликация идет. На мастере появится процесс wal sender, а на слейве wal receiver. Более подробную информацию о репликации можно получить выполнив на мастере:
SELECT *,pg_xlog_location_diff(s.sent_location,s.replay_location) byte_lag FROM pg_stat_replication s;
На слейве можно следить за значением, которое показывает когда проходила последняя репликация:
SELECT now()-pg_last_xact_replay_timestamp();
Резервное копирование и архивирование WAL
Первоначально резервирование производилось посредством pg_dump раз в сутки, что в совокупности с внутренним механизмом резервных копий областей в 1C Fresh давало приемлемую схему резервирования. Но иногда случаются ситуации, когда между моментом последнего бэкапа и моментом аварии проделано большое количество работы. Чтобы не потерять эти изменения нам поможет архивирование WAL-файлов.
Для включения архивирования WAL необходимо соблюсти три условия:
Параметр wal_level должен иметь значение replica или выше
Параметр archive_mode = on
В archive_command задана команды оболочки, например:
archive_command = 'test ! -f /wal_backup/db_01/%f && cp %p /wal_backup/db_01/%f'
Таким образом мы копируем архивные сегменты WAL в каталог /wal_backup/db_01/
Чтобы изменения вступили в силу, требуется рестарт кластера. Итак, когда очередной сегмент WAL будет готов, он будет скопирован, но чтобы им воспользоваться при восстановлении нужна базовая копия кластера, на которую будут применяться изменения из архивных сегментов WAL. С помощью простого скрипта мы будем создавать базовую копию и класть ее рядом с WAL-файлами.
#!/bin/bash
db="db_01"
wal_arch="/wal_backup"
datenow=`date '+%Y-%m-%d %H:%M:%S'`
mkdir /tmp/pg_backup_$db
su postgres -c "/usr/bin/pg_basebackup --port=5433 -D /tmp/pg_backup_$db -Ft -z -Xf -R -P"
test -e ${wal_arch}/$db/base.${datenow}.tar.gz && rm ${wal_arch}/$db/base.${datenow}.tar.gz
cp /tmp/pg_backup_$db/base.tar.gz ${wal_arch}/$db/base.${datenow}.tar.gz
Для того чтобы восстановить резервную копию на определенный период времени (PiTR) останавливаем кластер и удаляем содержимое
# pg_ctlcluster 9.6 db_01 stop
# rm -Rf /databases/db_01
Затем распаковываем базовую копию, проверяем права и правим (либо создаем) файл recovery.conf со следующим содержанием:
restore_command = 'cp /wal_backup/db_01/%f %p'
recovery_target_time = '2017-06-12 21:33:00 MSK'
recovery_target_inclusive = true
Таким образом мы восстановим данные на момент времени 2017-06-12 21:33:00 MSK, а точка останова будет сразу после достижения этого времени.
Заключение
В боевой эксплуатации связка 1С Fresh и PostgreSQL показали себя достойно, конечно не сразу все было гладко, но мы справились. СУБД прекрасно работает под нагрузкой, которую генерируют около сотни пользователей, множество фоновых заданий и еще наши роботы день и ночь загружают и проводят выписки, создают документы из других инструментов, анализируют состояние нескольких тысяч областей.
Картинка про надежность связки 1C Fresh и PostgreSQL:

У нас более 350 Гб информационных баз отлично себя чувствуют, растут и развиваются. Чего и вам желаем!
Источник: Блог компании «Кнопка» на www.habrahabr.ru
Сергей Синяков