Re: Improving spin-lock implementation on ARM.
| От | Krunal Bauskar |
|---|---|
| Тема | Re: Improving spin-lock implementation on ARM. |
| Дата | |
| Msg-id | CAB10pyYwOWZxoyYmz35zUk_PkdGPh2J8CiNhBZ3MzPMgGi7_RQ@mail.gmail.com обсуждение исходный текст |
| Ответ на | Re: Improving spin-lock implementation on ARM. (Tom Lane <tgl@sss.pgh.pa.us>) |
| Ответы |
Re: Improving spin-lock implementation on ARM.
|
| Список | pgsql-hackers |
On Thu, 3 Dec 2020 at 21:32, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Krunal Bauskar <krunalbauskar@gmail.com> writes:
> Any updates or further inputs on this.
As far as LSE goes: my take is that tampering with the
compiler/platform's default optimization options requires *very*
strong evidence, which we have not got and likely won't get. Users
who are building for specific hardware can choose to supply custom
CFLAGS, of course. But we shouldn't presume to do that for them,
because we don't know what they are building for, or with what.
I'm very willing to consider the CAS spinlock patch, but it still
feels like there's not enough evidence to show that it's a universal
win. The way to move forward on that is to collect more measurements
on additional ARM-based platforms. And I continue to think that
pgbench is only a very crude tool for testing spinlock performance;
we should look at other tests.
Thanks Tom.
Given pg-bench limited option I decided to try things with sysbench to expose
the real contention using zipfian type (zipfian pattern causes part of the database
to get updated there-by exposing main contention point).
----------------------------------------------------------------------------
Baseline for 256 threads update-index use-case:
- 44.24% 174935 postgres postgres [.] s_lock
transactions:
transactions: 5587105 (92988.40 per sec.)
Patched for 256 threads update-index use-case:
0.02% 80 postgres postgres [.] s_lock
transactions:
transactions: 10288781 (171305.24 per sec.)
perf diff
0.02% +44.22% postgres [.] s_lock
----------------------------------------------------------------------------
As we see from the above result s_lock is exposing major contention that could be relaxed using the
----------------------------------------------------------------------------
As we see from the above result s_lock is exposing major contention that could be relaxed using the
said cas patch. Performance improvement in range of 80% is observed.
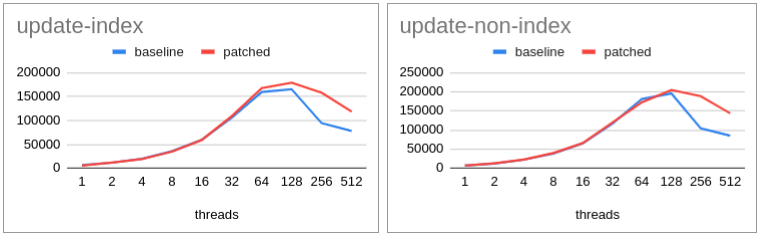
Taking this guideline we decided to run it for all scalability for update and non-update use-case.
Check the attached graph. Consistent improvement is observed.
I presume this should help re-establish that for major contention cases existing tas approach will always give up.
-------------------------------------------------------------------------------------------
Unfortunately, I don't have access to different ARM arch except for Kunpeng or Graviton2 where
we have already proved the value of the patch.
[ref: Apple M1 as per your evaluation patch doesn't show regression for select. Maybe if possible can you try update scenarios too].
Do you know anyone from the community who has access to other ARM arches we can request them to evaluate?
But since it is has proven on 2 independent ARM arch I am pretty confident it will scale with other ARM arches too.
From a system structural standpoint, I seriously dislike that lwlock.c
patch: putting machine-specific variant implementations into that file
seems like a disaster for maintainability. So it would need to show a
very significant gain across a range of hardware before I'd want to
consider adopting it ... and it has not shown that.
regards, tom lane
Regards,
Krunal Bauskar
Krunal Bauskar
Вложения
В списке pgsql-hackers по дате отправления: